What you see is What I get

Hello, and welcome to this rather whimsically named talk "What You See is What I Get", or when Screen Reader users attempt to explain what a screen reader is, what it does, how it does it, and to try and answer the question, what exactly has my code got to do with it anyway?
I'm going to focus on desktop and laptop platforms for this talk.
Not because there are no screen readers on mobile, quite the contrary, in fact, but just because there isn't enough space inside one talk to fit both in.
When we look at platforms and screen reader use, we discover that Windows is overwhelmingly the most popular operating system used.
We have the 9th WebAIM Screen Reader User Survey to thank for this data.
About 6.5% of people are using Mac OS with a screen reader, and about 1% are using Linux distributions.
The rest can be accounted for by people who are using screen readers on connected TVs, book readers, and consoles.
One of the reasons I raised this idea of platform numbers is because the same survey also tells us the number of people who do not have a disability using a screen reader are four times more likely to be using a Mac than an actual screen reader user is that's because by and large designers and developers who are using screen readers for testing are Mac users.
So bear in mind that there's a difference between the device you're most likely using and the one your screen reader audience is most likely using when it comes to testing.
So, what are these screen readers on Mac OS and Windows specifically as the majority of our audience.
On Windows, we find that Jaws takes up about 54% of the market.
It's one of the oldest screen readers, and it's had a heyday of around 70% of the market going back a few years, but it seems to have settled down at around the late 40s, early 50%, sort of share.
One of the reasons of its decline from its heyday is NVDA a free open source screen reader that now accounts for just over 30%, about 31% of the total market.
So these two between them are the two screen readers with the most of the market on the Windows Platform.
Things get a lot simpler with Mac OS because there is only one screen reader, there is VoiceOver.
And so if you're using a Mac and a screen reader, you're going to be using VoiceOver, keeps it nice and straightforward.
I've mentioned the phrase screenreader several times already.
And in a quite hand-wavy sort of a way that suggests it's really just a single entity.
It's actually not, there are three important component parts to a screen reader.
The first is actually the screen reader itself.
The piece of software that is, if you like, the brains of the outfit, it's the thing that has all the instructions, the commands, the configurations and the settings.
The screen readers are mostly driven through keyboard commands.
And I want to draw your attention to an important distinction here.
Keyboard users, which is to say sighted keyboard users, have access to a pretty limited range of keyboard shortcuts.
They can Tab, Shift Tab, use Space and Enter, Page Up, Page Down and such, but not much more.
Screen reader users, on the other hand, have an awful lot of keyboard shortcuts at their disposal.
And the reason it will become clear as we move forward.
There are so many keyboard shortcuts, in fact, that there aren't enough keys on the keyboard to cope.
So all screen readers use a modifier key.
In most cases, it's either the Insert key or the Capslock key.
So voiceover uses command option and it too can be configured to use Capslock, if you choose, if you read the documentation for these screen readers, you'll find that they're referred to as the NVDA key or the voiceover or vokey for short.
And armed with these modifier keys and a huge array of keyboard short cuts.
Screen reader users can carry out a wide range of tasks.
In fact, when you stop to think about it, screen readers needed to have tasks for doing the things that other people do by seeing.
This starts with things like reading text [Screen Reader Reads] Reading, text by character word, or line.
[Léonie] the keyboard shortcut to read the next line of text.
Maybe I want to get a bit more granular about it.
[Screen Reader Reads] Reading text by character, word or line.
[Léonie] And that's another keyboard command.
I might want to discover how some words in the sentence were spelt too.
[Screen Reader Reads] R E A D I N G space T E X T space B Y.
[Léonie] And you might have heard if you were listening carefully, that first character in that last example was spoken at a slightly higher pitch.
That's one of the ways screen readers indicate to the user that that letter was capitalized.
So three commands for reading text in three different ways, but of course you can double up those commands.
If you want to read backwards, the previous line, previous word or previous sentance.
When it comes to web content, there are an enormous number of shortcuts.
There is a shortcut for navigating by pretty much every garden variety, HTML element you can think of; graphics, links, tables, headings, landmarks, lists, listitems, and many more besides.
So between these two different forms of interaction, screen reader users are able to read content and navigate through it with equal facility.
The second component of a screen reader is the text to speech engine.
This is the bit that produces the speech output that if you've tried a screen reader, you will almost certainly have been using.
Text to speech engines, as the name suggests, takes text from on-screen content and converts it into synthetic speech.
Each TTS engine has a choice of voices that you can choose from.
[Screen Reader Reads] [Voice 1] Hello, this is the voice of Ava.
[Voice 2] This is the voice of Nathan.
[Voice 3] This is the voice of Zoe.
[Voice 4] This is the voice of Tom.
[Léonie] just a few choices from one TTS engine, but it doesn't stop there.
Those were all American sounding voices, but TTS engines also have voices that simulate accents from different parts of the world and even different areas within a country.
[Screen Reader Reads] [Voice 1] Hello, this is Tessa from South Africa.
[Voice 2] This is Sangita from India.
[Voice 3] This is Moira from Ireland.
[Voice 4] This is Kate from England.
[Voice 5] This is Karen from Australia.
So I'm fairly rich choice of the voices and accents that your screen reader can output.
Something else that the TTS is capable of doing is speaking at different rates controlled by the screen reader software.
The reason this is particularly important is that some screen reader, users particularly experienced ones, prefer to listen at really quite remarkably high rates.
This is an example now of a screen reader in its default voice at its normal speed.
And then at the speed, I typically listen to things like webpages and emails.[Screen Reader Reads] For millions of years, humans live just like the animals said something happened at unleash the power of our imagination.
We learned to talk.
[Sentance repeated at rapid speed] [Léonie] We don't like to hang about.
It's true.
You might be wondering why the drop in voice quality though.
And the reason is performance.
When you like to listen to speech fast, you want to be able to listen clearly and to understand it, however difficult that might be to believe, if you're listening to this for the first time.
And sometimes that means a trade-off in vocal quality against speed performance.
Another feature is punctuation.
Again, settings within the screen reader, lets you choose between typical settings like none, some most or all.
If you have all punctuation set, then this is the experience you'd get.
When you have the screen read or read what's on the current slide.
[Screen Reader Reads] Piglet sidled up to Pooh from behind period.
Quote, Pooh exclaim quote he whispered period.
Quote yes comma piglet question quote.
Quote nothing quote comma said piglet, comma, taking Pooh's paw period.
Quote I just wanted to be sure of you period quote.
[Léonie] Now, You'll agree, I'm sure that's pretty hard to understand.
It's really hard even to understand the texts that you're supposed to be consuming because all the punctuation marks get in the way.
This is why by default, almost all screen readers, choose 'Some' as their preferred punctuation level.
Some means that the text will be read just like a human would read it out loud, though, some punctuation marks do get spoken the ats in an email address, for example, and the experience is really quite different.
[Screen Reader Reads] Piglet sidled up to Pooh from behind Pooh he whispered yes Piglet, nothing said Piglet taking Poohs paw.
I just wanted to be sure of you.
[Léonie] And you'll notice that the screen reader and the text to speech engine still honor the punctuation, there is a pause at the end of a sentence, a slightly briefer pause for a comma.
And if there's a question mark at the end of the sentence, the intonation rises slightly just as though someone were asking a question.
Braille displays are the third component of a screen reader.
These are electronic devices that feature a number of braille dots that can be raised and lowered to form lines of braille characters.
Typically they have between 10 and 80 characters.
You might think that lots of blind people use braille and indeed you'd be right, but that doesn't equate to lots of blind people using braille displays with their screen readers.
This is for two reasons.
One they're horribly expensive, thousands of pounds, kinds of expensive.
And also they tend to be quite big and bulky.
There are smaller, more elegant ones, but as is so often the case with technology, the smaller and lighter and more elegant a thing, the more expensive it is.
There is one group, however, who will use a screen reader with a braille display exclusively.
And that's people who are deaf blind for whom, of course, speech output is a non-starter.
So there are at least one group of people who will be using braille output rather than speech, but the majority will be using speech output.
So we've looked at what a screen reader consists of.
And I've mentioned that there are numerous keyboard shortcuts for motoring around an interface and finding out what's there.
So the next question is where do they get their information from?
To understand this?
I'll take you back just a couple of steps in time.
If we go back to the days of MS-DOS, screen readers had it pretty easy.
They had access to the text buffer and they just converted it into synthetic speech.
So the experience for screenreader users and non screen reader users was pretty much identical.
And along came the graphical user interface, a Windows 3 the original MAC OS or OS2 for example, and things got massively complicated for screen readers.
What they ended up doing for a time was intercepting signals on the way to the graphics engine and using vast numbers of heuristics to try and make sense of it.
It was a pretty atrocious way to have to go about doing things, and fortunately, salvation came along in the late nineties in the form of platform accessibility APIs.
Microsoft active accessibility was the first to come along in 1997 as an update to Windows 95.
And it works through the Iaccessible interface.
After that in the following years, we had the assistive technology service provider interface, ATSPI for the gnome desktop, NSaccessibility protocol came along for the MAC.
Iaccessible2 extended MSAA on Windows and last but not least a new platform accessibility API came from Microsoft with Windows 7, UIAutomation.
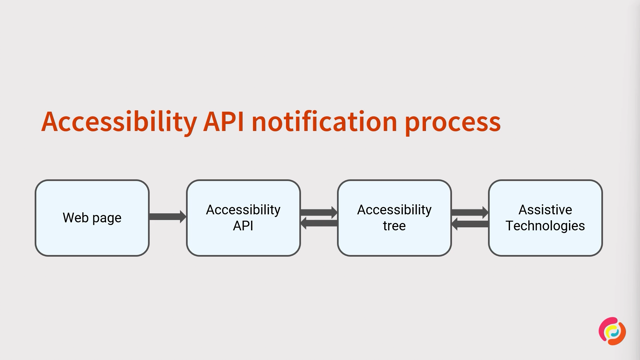
The things to remember about platform accessibility services are this.
They are available at the platform level and they are only available to assistive technologies.
They're not JavaScript APIs that we can use as part of the development process.
And they are the way that screen readers and other assistive technologies query information from the interface that the user wants to interact with.
So what does that information consist of?
The umbrella term is semantics.
What a screen reader, user wants to know is, pretty much, what you want to know.
What's on screen.
What is it?
Why is it there?
What's it for, and if it's Interactive, what's going to happen when I interact with it.
And we call these accessibility semantics.
The first bit of information is a role and looking at it from the point of view of web content.
This is what describes the elements purpose.
If we take our favorite talk example of a button element, and we worked to put it into a page, when the screen reader uses the inevitable shortcut for moving to the next button on the page, it will query the browser and say, Hey, look, what is this thing?
What information can you tell me about this element?
And the browser will respond with the first bit of information, its Role [Screen Reader Reads] the button [Léonie] And that's what I get to hear as a user.
So great.
I now know what this thing I have encountered on the page is therefore.
The next piece of information is the name or accessible name.
This is the thing that tells me what the element is therefore.
It's also the way that I will understand the difference between two buttons on a page, assuming they have a different purpose of course.
So if we keep building our button example, and we put some text inside the button element, that's what gives it its accessible name.
And now when my screen reader queries, the browser for information gets two pieces of information back, the accessible name and the role [Screen Reader Reads] show password button.
[Léonie] Great.
We're building up these layers of information.
We can add some more information by thinking about state.
This is the current condition the element is in assuming that it has a current condition at all, not all elements do of course.
There isn't a native way in HTML to indicate whether a button is pressed or not, but we can use the aria-pressed attribute to do the job for us, and we can set it to true or false to indicate whether the button is pressed or not.
So now my screen reader gets three bits of information, the role, the name and the state of the element.
[Screen Reader Reads] Password toggle button pressed.
[Léonie] You might also have noticed that the role changed slightly.
It's gone from being button to toggle button.
And that tells me now that the role of this button has changed.
It's going to be something I can toggle on or off.
It can be pressed or not pressed.
And because of the state, I know which state it's currently in.
So layers of information coming together.
There's a fourth piece of information, it's not used all that frequently, but it's great when it's put into practice to help users.
It can be used to provide an extra description, a short hint or explanatory note designed to help the user complete an action or use the control.
Again, there's no good way to do this in HTML natively, but the aria-describedby attribute lets us associate the container full of some text with, in our case, the button.
And the result is we now have four bits of information to use; the role, the name, the state and an extra description.
[Screen Reader Reads] Show password toggle button pressed reveals your password.
In other words, those four pieces of information between them have, almost certainly, given me access to everything you're able to discern by looking at the control that's on the screen.
And that's really the fine art of good screen reader accessibility, it's making available the information that everybody else has visually in non visual ways.
Let's look at some more examples.
Headings.
Yes, there is another keyboard shortcut for jumping between headings on a page.
And the heading elements all have the same role.
That's the role of heading, their state comes from the number that goes with it.
1, 2, 3, 4, 5, or 6.
And the accessible name comes from the text inside the heading element.
If you listen to the example of these headings on screen being spoken by a screen reader, you can start to understand why headings are so useful as a way of both navigating through content and understanding how the different sections of content relate to each other.
[Screen Reader Reads] Types of tequila, heading level one, Reposado tequila, heading level two Añejo tequila heading level two.
[Léonie] So we know that there's a heading one, that's the main topic, the main section of the page.
And within it, there are two subsections, of course you can keep cascading down through heading levels to keep dividing sections into subsections and so on.
Landmarks are another popular way of navigating with a screen reader because yes, there is another shortcut for letting you jump between one landmark element on the page and the next.
Landmark elements came along in HTML5, with things like header and footer and main.
And so as a screen reader user navigates between landmarks, they get a holistic sense of the page as a whole.
[Screen Reader Reads] Banner region, main region content and for region.
[Léonie] A quick note there about why the header elements doesn't have a role of header and the footer element doesn't have a role of footer.
It's actually because their roles, banner and content info predate the HTML elements.
The roles were actually defined as part of the original ARIA specification.
So they are explicitly appliable roles rather than the implicit roles that are mapped to HTML elements.
Then when HTML5 started to happen and these elements got introduced, the mapping was made, but there's a slight disconnect on the name.
Another landmark element is the nav element.
This time though, rather than using the landmark shortcuts to navigate to it.
Imagine we were just using the keyboard command for navigating through the content one line at a time, and we discovered that we can hear the beginning and the end of these sections [Screen Reader Reads] navigation region navigation region ends.
[Léonie] So you're not only know when you're entering a particular area of a page, you know, when you're leaving it too.
A quick word about use of the word region.
This is actually the Jaws screen reader and it calls them landmark regions.
If you were to do this with NBDA, you'd just hear them called landmarks.
This is perfectly all right and it's nothing to worry about.
It's like, I might say hello, you might say hi.
We both mean the same thing.
And we both know what each other means.
We do things just a little differently is all.
And screen readers are like that.
They will sometimes just do exactly the same thing in a very slightly different way, but that's to be expected.
And as I say nothing to worry.
We can keep building up with the nav though.
We can give it an accessible name.
This time.
It comes from the aria-label attributes.
So, not content inside the element, but to the content of an attribute.
And we can use it to distinguish this particular navigation block from any other that might exist on the page [Screen Reader Reads] website, navigation region, website, navigation region ends.
[Léonie] One thing you don't want to do in this pattern is include the word navigation inside the aria-label attribute.
That bit of information is the role and it comes from the HTML element itself.
So you don't need to repeat it.
If you did, the announcement would become something like website navigation, navigation region, which frankly gets a little bit noisy from the screen reader experience point of view.
Inside a navigation.
We might find a list full of some list items, <ul> list elements, ordered, unordered or definition have the same role, just list.
List items have a role of list item and they're accessible name as before comes from the content inside the element.
The browser also does something nice.
It'll count up all the list items inside the parent list element and make that information available to the screen reader too.
So we get a lot of useful information about the role and the accessible name of these things.
Plus the state of the list, how many things there are inside it.
[Screen Reader Reads] List of three items, bullet role bullet name bullet state list ends.
[Léonie] And if this had been an ordered list, instead of unordered, we would have heard 1, 2, 3, or ABC, instead of bullet bullet bullet.
We can keep building a navigation pattern.
As I say, it's common to have a list inside and navigation block and start building up the available information for screen reader users.
And for the list items to contain links to, well, different parts of the website in this case.
The link here has an implicit role of well link and it's accessible name comes from the content that goes inside the anchor element.
Because the link sits inside the list item that accessible name serves for the accessible name for both the link and the list item.
And when you hear it all together, it becomes a nice package of useful information.
[Screen Reader Reads] Website navigation region list of two items home Link about link list ends, website navigation, region ends, [Léonie] but there is one more thing we could do a little more state information.
We can use the aria-current attributes to indicate which of these things in the navigation block represents the currently visible page.
It's something we've done for ages visually, but until aria-current came along, we didn't have a really nice way of doing it programmatically, but with a value of page, we can now signal the same information that's available visually to screen reader users by indicating another piece of stateful information.
[Screen Reader Reads] Website navigation region list of two items, home, link, current page about link list ends, website navigation, region ends.
[Léonie] So, that's really nice and easy.
Now I've got access to exactly the same information that somebody looking at this would get.
I know it's navigation block, that inside it there are a number of navigation links to in fact, thanks to the browser, counting up the list items.
And I even know which one represents the page that's currently visible.
So it works really well when it works, well, properly.
Let's move on to some forms.
We'll take a look at a couple of radio buttons to input fields, both with the type of radio that will give them an implicit role of radio.
They're accessible names though, come from a slightly different source this time, not from the content of their own elements or an attribute, but from the content of another element, the label element.
And here's the thing to remember.
You've got to associate the label element with the form field or this all falls apart pretty quickly.
You've got to put a four attribute on the label element and an ID attribute on the form field and match the two values identically.
Without that the browser doesn't know, these two elements are related and it can't inform the screen reader when the screen reader queries it for information.
When it does though, we find out what kind of form fields these are and what they're accessible names are.
[Screen Reader Reads] Purple radio button not checked.
One of two red radio button, not checked two of two.
[Léonie] We also got some additional state information in there.
We had the both radio buttons were unchecked.
If we'd applied, the checks attribute to either one of them, one of them would have been announced as checked.
We also heard that there were two radio buttons in the group, and that information comes from the name attribute again with a shared value across the buttons in the group.
But there's something missing.
Why are we being asked to choose red or purple?
What was the question being posed to the user.
We can do something about this with the fieldset element this creates a group around the radio buttons that tells me that for some reason or another, the things in this group are related in some way.
By using the legend element as the first child of fieldset, we give the group its own accessible name.
And now when a screen reader focuses on that first radio button, they get a whole bunch of extra information that suddenly helps make sense of the whole lot.
[Screen Reader Reads] Group start choose the color purple radio button not checked one of two red radio, button not checked two have two group end.
[Léonie] And so we finally find out that we will be asked to choose a color, hence the red and purple choice, and that all happens automatically, thanks to the role, name and state information of this composition of elements.
Data tables often come up in accessibility terms, and I sometimes hear it said that they are a dreadful experience for screen reader users.
I actually disagree a well coded data table is an absolute delight to use because they just work so well.
We have the table element that has a role of table.
So I know what kind of construct it is.
In this case, the caption element gives the table an accessible name.
So I know why the table is here.
What it's for.
And then we come to the table, content itself, tr and td elements are counted up by the browser, so I get to find out how many rows and columns the table has got.
The really important element is the <th> element though.
It's the bit that indicates what the row and column headers are.
When someone sighted scans a data table, they will look up and down through columns and left and right through rows.
And as their focus moves to a particular cell, say in the middle of the table, you might flick your gaze up or to the left, just to remind yourself what the row and column headers were for that cell.
Screen readers have got, you guessed it, lots of keyboard commands for doing pretty much the same thing, moving up and down through columns left and right through rows.
And, as you move your focus into a new cell, it will automatically read the row or column header for you.
The equivalent of that casual flicker of a glance.
I can best to show you this by another demo.
[Screen Reader Reads] Table with three columns and four rows, average daily tea and coffee consumption.
Column one, row one, person Njoki.
Row two Iesha.
Row three coffee , one cup column two.
Tea two cups column 3 Léonie 25 cups row four.
[Léonie] And that's on a slow day, trust me.
But you can see that same interaction happening and again, what you're looking at on screen is essentially exactly what I'm getting through my screen reader curtosy of the HTML.
There's something else we need to touch upon when it comes to screen readers, we've looked at how there's lots of information to be found through the browser courtesy of the HTML.
But if you've been sitting here thinking, look, this is all very well.
There are shortcuts for navigating by headings.
HQ is usually for lists L T for tables, G for graphics.
What actually is controlling all this?
How does it actually work?
And the answer is that screen readers have different modes.
Of course they all call them something slightly different, but the basic mechanics are the same.
The default for browsing web content is known as virtual mode or browse mode.
And in this mode, the screen reader intercept all the keystrokes that get hit and it maps them to its own keyboard shortcuts.
So for example, if I hit the H key, the screen reader, intercepts that keystroke goes, wait, that's the shortcut for moving between headings.
I'll do that.
And that's how the navigation essentially works.
So the question then becomes what happens when you want to use the H key, well for typing an H character?
Screen readers in partnership with the browser are very good at recognizing this change of context.
When a screen reader focuses on something like a form field that expects text or characters to be entered, it will switch modes automatically, and it will stop intercepting the keystrokes and instead let them pass straight back through to the browser.
In other words in this mode, all screen reader commands, vanish, and a screen reader user has access to the same keyboard selection that any other user has.
We can show this through another demo, listen out for the thwocking noise that the screen reader makes as it focuses on the first form field.
And again, as it leaves, the second form.
[Screen Reader Reads] Username edit T I N K password, password edit, star star star star create an account, button.
[Léonie] And you'll hear they're the key echo that's common to all screen readers.
They echo back the key.
That's just being struck, except when they're in a password field.
When we get the same privacy and security affordance that everybody else does, the characters are announced as star star star, instead of whatever characters happened to have been typed in.
So screen readers in partnership with the browser are very good at working out when to switch contexts and switch modes like this.
But there's something to be aware of.
And that is that there are a number of ARIA roles that will trigger this same behavior and call it applications mode forms mode, focus mode, essentially it's all the same thing.
When a screen reader, user tabs onto a container that has one of these roles, the screen reader automatically switches context, and essentially withdraws access to all its typical keyboard shortcuts for reading and navigating content.
I can best demonstrate why this is important through an example.
If we start to build a menu bar, perhaps for browsing the categories and tags of a blog, we can start off with some good quality HTML, a list containing some list items that themselves contain links.
It's always a good idea to have a good, robust HTML fallback for all sorts of reasons.
But as we've discovered in accessibility terms, there's a rich source of accessibility information to be taken from the HTML.
If none of the aria or anything else that comes after this works, this will still be a viable and workable construct.
But we want it to be a menu bar not a list full of links.
So it will start adding some explicit roles.
We'll add a menu bar role to the parent list, that sets up the overall architecture of the thing.
We'll put a role of none on each of the list items.
This is actually because when we start building this composite control, we don't want the list items semantics to be exposed to screen readers as a tool.
So we're going to tell them, for this time and place assume that this list item has no semantics, that it has no role.
The links inside the list items though, become menu items instead of links, we again, override the implicit role of link, with an explicit role of menu item.
Then we can move on to add a little more in the way of accessible names.
The content inside the links act as the accessible names for the menu items, we don't need to do anything about that, but we can add in a little bit of extra here.
We can use the aria-label attribute to give the menu bar itself and accessible name, Blog taxonomy.
Okay.
I could have thought of something a bit more interesting, but it will do the trick.
We've also given the sub menu categories an accessible name, also using the aria-label attribute.
And finally, we can add in some state, visually it will be apparent when a menu is open or closed.
So we need to do the equivalent using the aria-expanded attribute with the value of true or false as is appropriate to the states of any of the given menus.
With all this information, the good underlying HTML that has been overwritten by explicit roles and names and state.
You think that we're in a really good position to give the screen reader user a great experience and here's what happened.
[Screen Reader Reads] Menu categories, sub menu one of two.
[Léonie] So it's great.
We had the thwock.
As a user, I know that my context has switched and that now I can start navigating using standard keyboard shortcuts.
I know that there is a menu and there is a category menu.
That's one of two, and that it is closed.
So far.
So good.
Except I can't go anywhere.
I can't do anything because my screen reader has switched context, switch modes.
It said, right, that's it.
You no longer have access to your keyboard shortcuts for reading texts, for navigating content you're on your own.
Which is why these roles are so important and understanding screenreader modes equally so.
It's because when you build constructs like this, you assume responsibility for providing the necessary keyboard navigation.
In this case, the most simple form is that the enter or space keys must be able to open or close the menus.
The left right up down, arrows must be usable for navigating along or up and down through the menu system and the escape key for closing any currently open child menus and returning focus back to the parent.
There is actually much more you can do in the way of good keyboard experience for a construct like this, but that's the basics that will get us by for these purposes.
And so when you take on that JavaScript and add in that keyboard functionality, then the experience becomes complete.
[Screen Reader Reads] Menu categories, sub menu, one of two.
Tags sub menu, two of two.
categories, sub menu, one of two.
Sub menu expanded code things one of three, web life, two of three.
[Léonie] So I hope with these examples, we have been able to answer the question.
What exactly does my code have to do with it anyway?
And the answer is absolutely everything.
Screen readers are almost entirely dependent on information obtained from the browser based on the code that the browser renders.
It really can't be emphasized enough, just how important it is that your HTML has all the semantics that it needs.
And if you can't use the HTML elements as they were originally intended that you poly fill those accessibility semantics using aria and, where necessary, that you also provide the keyboard interaction that's needed when screen readers switch modes and contexts.
I hope this has been useful.
If you have questions, I'll be around after the talk and as always I'm around on Twitter.
Thank you very much, indeed.
Ever wondered how screen readers do what they do? Ever wondered what screen readers actually do come to think of it?
Who uses them? What do they sound like? Where do they get their information from? What is it with screen readers and punctuation? And what exactly does my code have to do with it anyway?
Find out all this and more in What You See Is What I Get – one screen reader user’s explanation of how it really works.