What could you do with a neural network in your browser?
Hello everyone.
I'm Ningxin Hu, a Software Engineer at Intel.
I'm participating the WC3 Machine Learning for the Web community group and Working Group.
There we are working on a new Web Standard, so-called Web Neural Network API that can help web applications and frameworks to access a purpose-built machine learning hardware.
Agenda wise, I'll first to introduce the observations we have so far.
What's the problem?
There is a performance gap between the web and native for AI applications.
Then, I'll talk about the Web Neural Network API proposal itself, and how it can fill the gap by introducing the new domain specific abstraction.
We also implemented the webnn-polyfill and as a webnn-native, that allows you to start experimenting web and API today.
And I like to share the results of the running code and give some interesting demos.
As you know, in the last decade, the machine learning in particular, the deep learning has been getting increasingly important and widely applied in many applications like computer vision, natural language processing, and the speech recognition.
Nowadays thanks to the merging, JavaScript to machine learning frameworks such as iTensorFlow.js, ONNXRuntime Web, MediaPipe and OpenCV.js now the web applications can easily incorporate this innovative usage by running the machine learning models in web browser.
Underlying those frameworks usually leverage WebAssembly, WebGL, and the even a new WebGPU to run the machine learning computation on CPU and the GPU respectively.
On the other hand, to meet the exponential increasement of the computing demand for machine learning workload, the innovation of hardware architecture is advancing very fast.
The Machine learning extensions have been added into the general purpose devices, such as the CPU and the GPU . A bunch of new dedicated machine learning accelerators is emerging, such as NPU (Neural Engine), VPU (Vision Processing Unit) and TPU (Tensor Processing Unit) just to name a few here.
These dedicated accelerators not only help optimize the performance, but also help reduce the power consumption for machine learning tasks.
By taking advantage of this new hardware features, the native platforms got a very good performance and were successfully deployed in real production.
So how about the Web?
We tested MobileNetV2, a widely used image classification neural network for client usage as the workload and measured the inference throughput with batch size 1.
For hardware devices, we chose a laptop and a smart phone, both of them equipped with machine learning specialized hardware.
The CPU of the laptop has a vector neuron network instruction know as VNNI.
The smartphone has a low power digital signal processor optimized for full machine learning.
According to the charts, there is a big performance gap between Web and native.
For instance on the laptop, the native CPU inference is about 5.6 times faster than a WebAssembly for float point 32 precision.
The reason behind is that is that native can access 256 bit vector instructions and optimized the memory layout for that vector width, however, WebAssembly only has 128 bit vector instructions available.
Native GPU inference is about eight times faster than WebGL for float point 16 precision.
That's because a hardware dependent machine learning kernels, within the GPU driver are not available to WebGL.
On the smartphone, we observed the similar results.
The lower precision inference, as known as the quantization is a widely used technique to optimize the inference performance and then reduce power consumption.
The VNNI and DSP are designed to accelerate that.
So if the using 8 bit precision on the laptop, the native inference accelerated by VNNI, can be 12 times faster than the best of the web.
And on the smartphone that 8 bit inference could be even 16 times faster.
Unfortunately, neither VNNI nor DSP is exposed to web apps through the generic web API.
The JavaScript and machine learning frameworks can not take advantage of these hardware features.
That leads to is a big performance gap.
However, due to the architecture diversity of this new machine learning hardware.
It is quite challenging to expose them by the generic CPU or GPU compute web APIs.
So we propose Web Neural Network API as an abstraction for neural networks in the web browsers.
It aims at bridging the innovations in the software and hardware ecosystem, bringing together a solution that scales across hardware platforms and the working with any framework for web based machine learning experiences.
As illustrated in the architecture diagram, web browsers may implement the WebNN API using native machine learning API available in the operating systems.
This architecture allows JavaScript frameworks to tap into cutting-edge machine learning innovations in the operating system and hardware platform underneath it without being tied to platform specific capabilities, bridging the gap between software and hardware through a hardware agnostic abstraction layer.
At the heart of the neural network is a computational graph of a mathematical operations.
These operations, as a building blocks of modern machine learning technologies in computer vision, natural language processing, and robotics.
The WebNN API is a specification for constructing and executing computational graphs of neural networks.
It provides web applications with a capability to create compile and run machine learning networks on the web browsers.
The WebNN API may be implemented in web browsers using the available native operating system machine learning APIs for the best of performance and the reliability of results.
The execution of a WebNN graph come interoperate with kernels written in WebAssembly, WebGL, and the WebGPU shaders.
With that, the frameworks can be flexible by using WebNN for hardware acceleration and the still using WebAssembly/WebGL/WebGPU for custom operations support.
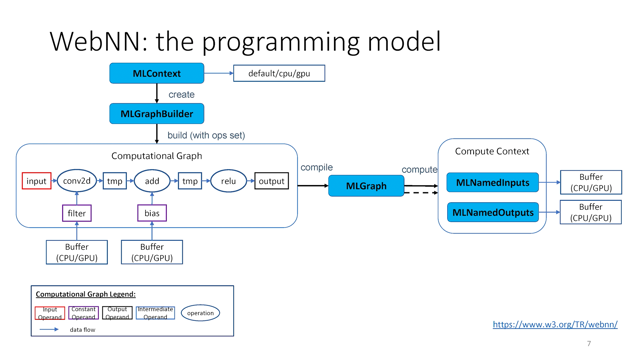
There are three major interfaces within WebNN API: MLContext, MLGraph, and the MLGraphBuilder.
An MLContext to interface represents a global state of neuron network API execution.
One of the important context to states is the underlying execution device.
The execution device manages the resources and the facilitates, the compilation and the execution of the neural network graph.
With WebNN API frameworks can specify the device preference such as a CPU or GPU later, it will support AI accelerator.
Frameworks can also set power preference by high performance or low power.
The implementation would select as the best hardware device available on the platform regarding to the preference setting.
The MLGraph interface represents a compiled computational graph and exposes a compute method to perform the inference.
So MLGraph, Buder interface service as a builder, also known as a factory to create a MLGraph.
An MLOperand is a representation of data that flows within thea computational graph, which includes input-values, the trained weights as known as a constants, intermediate values, as well as output values of the inference.
At inference time every MLOperand will be bouned to the actual data, in machine learning term, they are tensors.
Tensors are essentially a multi-dimensional arrays.
The representation of the tensors is implementation dependant, but it is typically includes the array data stored in some buffer and some metadata, describing the data type and shape.
The MLGraphBuilder interface enables the creation of MLOperands.
A key part of the MLGraphBuilder interface as an operations, such as con2d(), pooling() and matmul()).
The operations have a functional symantics.
Each operation invocation returns at distinct new value without changing the value of any other MLOperand.
The build() method of the MLGraphBuilder interface is used to compile and optimize the computational graph.
The key propose of the computation compilation step is to enable optimizations that span two or more operations.
Such as operation or loop fusion.
For example, the street operations in the graph, conv2d, element-wise add and relu might be fused into one kernel depending on the hardware implementation.
The compute() method of the MLGraph interface is used to execute the compiled computational graph.
That is to perform interference.
The caller supplies the input values using MLNamedInputs, binding the input MLOperands to their values.
The caller also supplies, a pre allocated buffers for output MLOperands using MLNamedOutputs.
The buffers could be CPU buffer or GPU buffer.
That avoids unnecessary cross device data moving when interoperate with kernels written in WebAssembly and WebGL/WebGPU.
Let's use a simple example to demonstrate how to use a WebNN API, to build and execute a computational graph.
This is athe graph we'll use, it contents only one operation MatMul, stands for Matrix Multiplication It takes two inputs and a produces one output The input a is a float matrix in shape 3 by 4 the input a B is another float matrix in shape 4 by 3.
According to the matrix multiplication the output C is a float matrix in shape 3 by 3.
To build that graph with WebNN API, first we need to create the context through navigator.ml.createContext.
would take options where you can specify the device and the power preference, As I mentioned.
With the context we can create a builder instance for graph building and the execution.
For input a ,we can use builder.input to create as an input ut Operand for it.
Builder.input takes two arguments The first one is input name The second one is the operand descriptor that describes the data type and shape.
First Input a it's data type is a 'float 32 and the dimension is 3 by 4 We can create input operand for B in a similar way.
Then we can call builder.matmul, That is a matrix and multiplication operation with a and b it returns c.
That is an output operand of this operation The next step is to build the graph.
It can be done by calling builder.build.
We need to supply the output operand of the graft with its name.
Builder.build would compile an optimize a graph in the hardware optimized the way it returns compiled graphs that we can compute with it . For the sake of simplcity, we've put values in CPU buffer here are using typed array buffers.
For input a because it's shape is a 4 by 3, so we allocate afloat32array with length 12, here we fill it with value 1.0 just for example.
Similarly for input b we allocate another float32array with value 2.0 We also need to allocate a buffer for our output C.
As it's shape is a 3 by 3 it requires a buffer lists is 9.
It doesn't need to be initialized with values because it will receive results of a graph compute.
Then we can invoke graph.compute with these buffers The 1st argument of graph to compute is a named inputs that bind input buffers to input operand and through names The second argument is a named output that bind the output buffers to the output operand and through name .After graft.compute completes the results would be placed in bufferC.
This sample is available online as one of the webnn-samples.
It is able to run in today's web browsers Thanks to webnn-polyfill.
Feel free to check it out through the link in the slide . Although the previous example is very simple It actually illustrates the essential steps that for any complex neural networks.
There are more other real use case samples available on webnn-samples github repository .They include the Computer vision ones like the handwritten digits classification, image classification, style transfer, objects detection, semantic segmentation and the non-compute vision ones like noise suppression.
All these examples can run in today's web browser with webnn-polfill.
The webnn-polfill itself leverages TensorFlow.js ops implemented in WebGL and WebAssembly.
You can also run this WebNN API samples on native Machine learning API is through WebNN-native.
WebNN-native provides several building blocks: it provides C/C++ headers that have one to one mapping with WebNN IDL the applications including JavaScript runtime or web browser can use it to implement WebNN API.
For example, WebNN-native provides a node.js addon that JavaScript applications can incorporate.
WebNN-native also has several backends that use the native machine learning APIs, So far it has a DirectML backend for Windows10, and OpenVINO backend for Linux and Windows.
More backends are coming in the ways Thanks to the community's contribution.
I'd like to demonstrate a running a few WebNN samples with webnn-polyfill and webnn-native.
So I will use WebNN object detection example as a demo.
So first I will run this example in the web browser with webnn-polyfill.
So there are some configurations.
So the layouts there is NCHW NHWC stand for the channel first or the channel last for the input image layout.
So I'll use a NCHW for this demo.
And then for models you have options You can draw on the Tiny Yolo V2 or SSD MobileNet V1.
So I will use MobileNet V1.
So it will load, build model and do the compute.
So there are some time measurement here.
Like the build time is 2 57 milliseconds The inference time is a 130.
So this is a performance about as a polyfill....this is actually is the result.
The person detector with a bounding box image and then there is a kite so I will turn on the live camera, we'll get as a meta stream with a camera and do the detection.
So it detects I'm a person, it's very nice.
So the FPS is around seven.
So it's about polyfill.
Then I will demonstrates the electron with webNN native So this is an Electron app entering point with the object detection So first I will NPM install, yes it is done, it will install the electron node.JS banding of the web and native and then I will start.
So this is an electron app running the exact same WebNN object detection sample.
So the only difference is that it is using the node addon of the WebNN-native.
So let's see its performance.
So its inference time is improved much like a it's a reduced to 7.87 ms.
So if I turn on the live camera, so you see is the FPS is around 47....around 50 now, Right?
So you can see the rendering is very smooth.
It can ecognize this in a chair and it can also recognise that I have a cup.
There a corresponding performance numbers of WebNN-native on laptop, and the previous Chromium WebNN prototype on smartphone.
As these numbers show, by introducing the domain specific abstraction of a neural network and the relying on the native of machine learning APIs WebNN can help access the optimized software and hardware for machinelearning, and close the gap between the web and native.
The Web Neural Network API is being standardized within WC3 machine learning for the web Working Group.
Thanks for watching and looking forward to your feedback
Neural Networks are an approach to machine learning (specifically Deep Learning) that are now widely used from supercomputers to your smartphone (via APIs like CireML in iOS and Neural Networks API on Android).
The Web Neural Network API (WebNN) in development at the W3C aims to bring Neural Networks natively to the browser, and with them solutions to a range of common use cases including Face Recognition, Facial Feature Detection, image captioning, and much more.
And best of all you can start exploring it today with the WebNN polyfill.
In this presentation Ningxin Hu, one of the editors of the WebNN specification, takes us through its features and aims, and how we can get started using WebNN right now.