Personalised Curiosity: Why and how machine learning can keep your users surprised and engaged
(upbeat electronic music) - OK, so thank you very much for that introduction, Jen. I want to acknowledge my current employer, the University of Sydney and my former employer The University of North Carolina at Charlotte for funding some of this work, as well as the US National Science Foundation and as of nine o'clock this morning, the Australian Research Council.
On with it, then.
We are surrounded by machines that know what we want, that give us what we want, and it's great.
Don't get me wrong, that's wonderful.
But a side effect of that is that we shop a bit too much. We eat a bit too much.
We binge watch shows a bit too much, and we have this luxury that has never really been known in the human race until now of never actually having to listen to someone we don't already know that we agree with.
And that has resulted last year in a number of really interesting geopolitical dramas.
Algorithms are in some sense responsible for a lot of this. The dream of the personalised web, the dream of content that was fit to everyone individually has turned into this kind of convergence, this kind of hyper-partisan focus where everyone gets exactly what they want and no more. That wasn't the intent, of course.
The intent was just to give people what they want so they use more of your service they buy more of your stuff but it seems to have been a side effect.
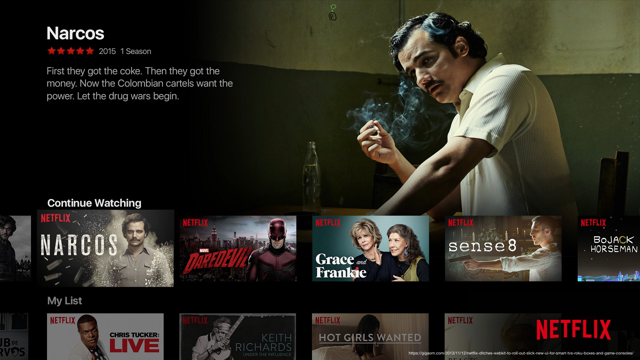
For example, we have products now like Netflix where the entire front page is driven by recommender systems.
Recommender systems has become such a dominant form of AI and personalization algorithm and we don't really think of them as AI anymore. They're a mature technology.
They're just an algorithm, they're just an approach. This hyper-convergence isn't found everywhere. I think one interesting example where things go in the opposite direction, one sort of taste of the stuff that I'm interested in looking at is actually in music discovery algorithms. Here's an example from Spotify who do some really interesting things with their recommender systems to help you discover new things.
But this actually happens only where it makes business sense.
It makes business sense for Spotify to try and get you to discover new music for reasons that have to do with their licencing agreements, but music is also a domain where there's a very low cost to consume new material and to reject it if you don't like it, so it's really one keystroke away. The user experience for these products is very clearly built around the, no, don't like that, give me the next one. The users are also already motivated to want to try new things.
That's part of why they're on your service. So we know that this sort of approach of motivating users to try new things, it works for music. It works for some media consumption, but what would it look like for that to work trying to get people to eat more diversely, which has, for example, been linked to greater overall health outcomes. You don't need to tell people to eat healthily. You just have to tell people to eat differently and they run into healthily along the way.
What would it mean in getting people to read news more broadly to try and avoid filter bubbles? How would we motivate people to actually want to see things from someone else's perspective? And how would we motivate people to want to read more broadly, whether that's a child in primary school, or whether that's a research student who just won't read the stuff I ask them to read. So all of this comes down to the same question of how can our experiences, our digital experiences motivate users to try new things? We've got a one-year-old kid, so I've been thinking a lot about curiosity recently.
I've been thinking about what motivates people to try new things.
And so we've been working on this approach where we are trying to simulate curiosity.
Trying to build algorithms that simulate the process of curiosity in order to stimulate it.
So we are trying to find ways that an AI can understand what will make you curious in order to give you that, in order to give you stuff that you don't know you want.
And we call this approach curiosity machines. And this sort of falls into a gap between how we think about these technologies. This is actually, it's wonderful that I get to give this talk after the great keynote we had this morning by Genevieve Bell.
It was talking about how there actually does need to be a space in the middle here between AI, psychology, and design because these things aren't wholly covered by the idea of user experience design or service design or any of the other flavours of design that we usually talk about, and they're certainly not wholly covered by artificial intelligence. And they're not really covered by traditional approaches to psychology, because we're trying to induce a change in behaviour. We're not just studying an existing behaviour. So these are all areas that are a little underexplored so far, and I think that the curiosity machine's angle is just one of many things that we've yet to explore that lie in the overlap between those three fields. Now I'm an academic and I like looking at really super abstract Venn diagrams talking about spaces between things.
Let me give you an example from something that my team put together last year.
This is an early mock-up.
I'm deciding to show you an early mock-up because that won't give you the false impression that this works yet, but here's an app for suggesting what to cook.
A sort of standard recipe app, but in this case, it's a healthy eating app that doesn't tell you eat healthy. All it's trying to do is build a model of what you want and then give you something that you don't yet know you want so it works in the same sort of way you'd expect and it recommends recipes that are created just for you. There's an AI angle to this where it's not just picking things from a database but it's customising them to fit you. Think about this as a grown-up version of hiding vegetables in your kid's food.
It's trying to get you to try new things without realising you're actually trying new things. And then it recommends them to you and the process changes very, very slightly from the average experience that people are used to where instead of being asked just one question, how good was it? You're asked several questions.
How different was this to what you know, and how difficult was this for you to make? Because there are more variables in the user model behind the scenes than people are used to so far. So this is an early look at the kind of experience that we're trying to bring about.
To the user, very little difference, but behind the scenes what is happening is trying to model this whole new dimension. This emotional, or the surprise, or this discovery that we want to induce in people.
So get to a few more details beyond that example. I wanna clarify that I'm talking about curiosity as a state, so that is, I am very curious about this thing. Not curiosity as a personality trait.
She is very curious.
That actually also has two definitions, but in this case I mean she likes trying new things. There are two whole sets of psychological research that cover both state and trait curiosity.
In this, we're talking about what is capable, what everyone is capable of.
Everybody can become curious in the right circumstances. And when I say curiosity, I mean the union of interest and surprise.
I mean stimulus that is interesting to you that you already know you want, or that when you see it you find it interesting, that has some value to you, but is surprising. There is something about that for which you, unconsciously, had strong expectations, strong assumptions, and they were wrong.
And so that starts to give us an operationalization. That has to give us something that we can build models of. For anybody who is doubting that AI, that computers can do anything surprising, that the computer has any capacity to surprise us, think back to that go championship between DeepMind's AlphaGo software last year, 2015, some time ago.
The AI moved stupidly quickly.
And the world champion, or a world champion Lee Sedol actually had to leave the room for a few minutes. The machine took a move that no human would have ever taken. The machine actually knew that it was a one in 10,000 move for a human player, a human grandmaster to make that move, but it decided to make it anyway and the commentators, of course there were commentators, the commentators on the stream flipped out. They just went bananas.
I don't know if that's actually very common in go championships, but I don't watch that many of them, but these ones went bananas.
The commentator, a grandmaster in his own right, said that's not a human move.
I've never seen that move, it's beautiful.
Articles were written, and are actually quite good, about that one move in that game, 'cause that's the point at which they realised that the AI, working entirely within the rules of the game, could surprise people, so it's possible.
We've just got to figure out how to leverage that. Figure out how to leverage that to change people's behaviour for the better. Also when I talk about curiosity, I'm not necessarily talking about this undirected novelty-seeking, this undirected, oh, anything that surprises me I'll flit off in that direction, 'cause it's much more complicated that that. We can't just serve up a set of results and hope that some of them are surprising.
There are more touchpoints in the experience because people tend to focus on something which triggers a whole new round of what is called specific curiosity.
Then they get interested in other things that are like that thing.
And now in this mindset, you're not interested in other stuff that would be surprising to you, because it's no longer interesting.
You have this focus, but a focus now on something that is new.
So if we want to build these models we need to understand the psychology that goes into them and we can't just treat it like a new way of ranking search results.
We have to actually build these sequential experiences that recommend something to you and then recommend something else to you and something else and maybe lead you along the bread crumbs to an outcome that is more beneficial. There's also the case of personalization.
So what you find curious would be different to what I find curious.
And in the recipe domain this is very easy to understand. Think about the foods that you grew up with. Those ones won't be surprising to you at all. But, if you grew up in a different set of recipes you'd think very differently.
If you grew up somehow in Sydney perhaps, that doesn't really make sense, but if you somehow grew up only thinking that ginger was used in sweet baked goods in the traditional European way of using ginger and you'd never encountered it in the Eastern way of using ginger in stir-fries and other savoury contexts you would find ginger and beef to be an absurd combination. That would be surprising for you.
But if you had maybe a bit more of a cosmopolitan upbringing that would be totally commonplace.
So we need to personalise this.
We need to have the user giving feedback and receiving suggestions in the system and then we have a personalised model of that. So this is a research agenda.
This is something that we've played around with, my team, some colleagues here in the US.
We have developed these ideas and we've started experimenting with them.
And I want to just share a sort of rapid-fire succession of fairly random experiments with you.
So we've tried this with food.
Anyone Greek here? I'd like to apologise in advance for murdering your national dishes, I apologise. So there is a dish, we went trolling over the web. We gathered hundreds of thousands of recipes and we threw them into some deep learning, some natural language processing, and a few other things looking at co-occurrence between ingredients and verbs and stuff in a simplified form.
We found this is one of the most surprising recipes to someone who had seen that whole database. So if you've seen across that whole database of what's out there, you're a gourmand, you're a foodie, you've seen all of that stuff, what would you still find interesting? We found this recipe for a kind of Greek meat pie had some of the rarest combinations in the world's cuisines, at least the world's cuisines that ended up on the internet. Let's remember that previous talk on inclusion really points out that the vast majority of the world's cuisine maybe doesn't end up on allrecipes.com. But the reason why this was surprising, kreatopita, I'm sure I'm saying that wrong, is because of this trio of ingredients.
Eggs, parsley, and cinnamon.
The system had seen a lot of eggs and cinnamon obviously. And seen a lot of eggs and parsley obviously, different context, but the idea of seeing all three together was kind of weird.
And that meant that this recipe stood out as having an unusual flavour profile.
We then put this into another AI system that could take unusual flavour combinations and generate whole recipes out of them.
It actually didn't generate a whole recipe with a set of steps, we're still working on that. The natural language processing is still playing catch-up a bit there.
It keeps saying add rice, now add rice.
(audience laughing) Turn on the burner, and then add rice.
But, what we were able to do is develop a set of tags and some titles and we were able to take that and it would tell us, OK, I've generated another recipe that is surprising in the same way.
So if you've developed that specific focus, you've got that specific curiosity towards this sort of thing, then it will generate this, which was a spicy fried pork chop.
I have to admit, it generated a list of potential titles and I curated that one.
It's still a little bit absurdist, which is excellent. I like recipes with absurd titles, but maybe we need to get this beyond the very, very early adopter.
So this is a recipe that includes that trio of ingredients. We've also got some other projects which are about including ingredients with similar flavour profiles, similar flavour combinations. One of the advantages of throwing AI at stuff is that you can then take in all of molecular gastronomy's chemical compounds if you've got ahold of the data, then you can just build that into what you're making. But to take it out of the food domain, some colleagues of mine, Sunshine and Fackery. Fackery was her PhD student.
They took this and they applied it to health articles, so news articles about health, to find ones that would be surprising for a user.
So the user would come in looking for articles in one category and they'd look for recipes that combined that with another category in a surprising way.
So this was someone looking for sleep disorders. They connected dyslexia.
It turns out there's a correlation between infants with sleep disorders and dyslexia later in life. Some other examples, connections between diabetes and bipolar disorder, and between food intolerances, gluten here, and tuberculosis.
That one surprised me.
So we can take these and apply it in multiple domains. We can look at computer science papers, and let's be honest, we spend all of our days looking at computer science papers, so we had this data lying around.
We went to one of the larger libraries of computer science papers on the internet and we gathered up 300,000 abstracts and full texts from PDFs and we applied a different machine learning technology here. We looked at what's called topic modelling, which is just about finding groups of words that occur together.
They're thematically related in this context. And you see the two topics at the bottom there. The most common words that were in this little cluster of words used in documents were research, social, study, group, community, so this is sort of the social science-y part of computer science.
And then the other topic that was only very rarely combined with it used words like algorithm, programme, graph, compute, this is traditional computer science, optimization. So here's a paper Star Search Affective Subgroups in blah, blah, blah, academic titles are dry.
I would like to apologise, I should have used a shorter title for this talk.
If you look in your programme, spot the academic. I'm the one with like an essay right there in the title field.
Three word titles next time, I promise.
And so this paper is about using algorithms to understand the characteristics of how teams effectively work together.
So they're taking the social graph across collaborative teams and looking at it algorithmically. This is a fairly emerging area of research, one that has a lot of interesting things going on and it's pretty surprising, right, that you can use those two things together. We also looked at the words used in the most surprising co-occurring words found within computer science literature.
Here's the top five, I love these.
You do not see the following words in the same papers. Compiler and emotional.
Chip and social.
Vertex and organisational.
That one actually, that was a bit weird.
I double-checked that one.
I would have expected to have seen that work on social graphs would use both of those, but whatever. Voltage and curriculum.
And participatory and cache, because those two take place at opposite ends of the hierarchy of how we deal with computer systems.
Cache happens very down close to the metal, and when you're talking about participation with people that's many, many levels up.
Do have to acknowledge, if you look down about number seven or eight on the list. (groans) Algorithm and woman.
Yeah, well, computer science does need to change in that regard, but maybe that's why we're doing this. This is about trying to bring algorithms that are able to improve us, are able to not just hyper-focus us, not able to give us more of what we want, but to change what we might want.
And this isn't some utopian fantasy where suddenly everybody's going to stop making recommender systems that actually sell their products and start making recommender systems that make everybody better people.
There are real business models that can be built around this idea of algorithmic diversification. Of broadening people's horizons.
We just have to go out there and find them. So, to summarise, curiosity machines learn about us, build models of us, simulate our behaviour in order to make us more diverse, make us more curious, to broaden our horizons. The potential applications are really, really broad. I've talked a little bit about health, media, design. There are many, many others.
Politics comes to mind.
And that making this a reality will require cognitive science and psychology.
It'll require design of all stripes and it will require AI, machine learning, and engineering. But, hopefully it can be done, thank you.
(audience applauding) (upbeat electronic music)
When machine learning is used to recommend content, it usually gives us more of what we already know we want. What if the opposite approach, piquing our interest in new content and driving us to explore the unfamiliar, turned out to be better for us all in the long run? This talk explores how an AI model of curiosity inspired by cognitive science can be used to encourage us to broaden our tastes.