Product Design for A.I. driven products

(upbeat electronic music) (applause) - Thanks everyone, it's really good to come up and have the applause happening and everything, that was very well organised Tim.
As Tim said, I'm Nick, I run a company called Tyto.ai and before that, I was at a place called Data to Decisions Cooperative Research Centre for about four and a half years running A.I. and machine learning projects there. We weren't funded by the DOD, because it's the Department of Defence in Australia, so thanks Caroline. I think Caroline's talk was really good.
I was a bit worried at some points because I thought she'd use the exact examples I'm gonna use but they're not, and we didn't coordinate this. There's a lot that we have in common here I think. The toxic comments thing was a competition that I did as well, it's an interesting field. I'll just get this around the right way.
So, artificial intelligence, it's a hard thing to define. It's a hard thing to define intelligence itself. One question I have when people are asking: is this artificial intelligence, is it not? If they can give me a good definition of intelligence, then we can talk about artificial intelligence. But for me, today, what we're gonna talk about is any system that has software components that learn. So things that adapt to change and data or the environment that they're running in over time. So why does this matter? It's easy for us to talk about this at some kind of superficial level and think A.I. is the next big thing.
But, actually thinking about the product design parts of it, why do we need to do that.
There's a really good reason, A.I. is an amplifier. It takes what we think and what we build, and it makes it easier, faster, and better, hopefully, or worse. There's a saying, machine learning is money laundering for buyers.
It's very easy to say: the machine did it, the machine made this decision.
So one of the things I want to talk about today is trying to avoid that trap.
A.I. is an amplifier, you get these good news/bad news things, and we do tend to talk about a lot of the bad news, the A.I. could lead to nuclear war by 2040. But there are good things as well.
The french fries, I think these are important things. I am gonna use a lot of examples here that concentrate on the bad things that happen, because it's important to point those out.
But there are really really good things and good uses of A.I. as well, so we need to acknowledge that.
And I'll try to talk about that a bit as well. We have rules in user interface design at the moment, but I think it's time to have some new rules around incorporating these A.I.-type pieces into our products. Firstly, the world is bigger than your dataset, but your A.I. doesn't know this.
When you talk to data scientists, they'll use this type of language when discussing this problem. They'll talk about training distributions and test distributions of data.
When you start hearing that, that's what they're saying. They're saying that A.I., the machine learning that they've built, hasn't seen the entire world. Black swans, you may have heard of the book Black Swans, and that was an example of unexpected events happening. But black swans are really a change in the real world distribution of data over what people were trained on. Until about 1647, all the white people in the world who wrote books about what was possible had only ever seen white swans.
And they truly believed it was impossible for there to be black swans until the Dutch came to Australia and found some black swans and were told that they were lying about it. So let's talk about what can go wrong.
You may have seen a recent thing about how Amazon abandoned an A.I.-powered hiring programme that they had because it couldn't hire women. They didn't have enough women in their workforce, so anyone who went to a women's college wasn't being recommended. They never implemented that system, and you have to give credit to Amazon here because they found those problems first.
But, there's a lot of companies that aren't as good as that. Here's an example of a start-up that was doing the same thing, they were doing resume screening, and when a company audited the algorithm, they found that the two most important features were whether the person's name was Jared, or whether they played lacrosse.
I think we can acknowledge that if they were hiring for lacrosse teams, that's probably appropriate, but generally speaking, that's not the kinds of features you wanna see when you're building an A.I. to hire.
So, if you have data scientists who are working for you or with you to build these types of things, it's absolutely okay to ask for this kind of information. People are scared because data scientists tend to couch things in language that makes it hard to understand, but it's absolutely okay to say: what are the most important things that your algorithm is making decisions on.
So, domain expertise, again, Caroline talked about this a little bit, but, do the results you're seeing really make sense? There's a great example that's quite well-known in machine learning around tanks.
Back in the 1990s, possibly, it's a little bit unclear when this story happened.
The department of defence tried to train a vision system to distinguish between Russian tanks and NATO tanks. They gave it to a research group, and the research group took the photos that they were given and built this neural network, which in the early 90s was quite sophisticated, that was getting 100% accuracy on their training data. These were research scientists, and they were very well aware that 100% was unlikely.
So they checked it all, they couldn't see what the problem was, sent it over to the Department of Defence, they started testing it in the real world and it was returning random results, and so they dug into it more. They found that the photos that had been taken of all the NATO tanks had been taken during sunny conditions, and the Warsaw tanks were taken through telephoto lenses in foggy conditions, cloudy and overcast, and the algorithm was really really good at picking up sun and light.
Here's another example, predicting gender using iris images.
This is where they take a photo of your eye, just the eye with your eyelid and your eyelashes, and predict the gender from it.
People in the medical field thought this was impossible, and yet these people generated this dataset, and with a relatively unsophisticated algorithm we're getting 80% accuracy. This really got into the medical field, people started going: what is going on? Until someone who had a woman in their team looked at the thing, yeah, it was great at detecting mascara. So have domain expertise, think about whether or not someone's wearing makeup, or this type of thing, because otherwise you're going to make these mistakes and people are just gonna laugh at you.
Still happens, this is a paper that came out of Stanford last year I believe, by the person who did a lot of the early Cambridge Analytica work. Deep neural networks are accurate at predicting sexual orientation, so, a gay detector.
While I don't like to read slides, I will read this part because there's some parts of it that are really interesting. These findings advance our understandings of the origins of sexual orientation and the limits of human perception.
Additionally, given that companies and governments are increasingly using computer vision algorithms to detect people's intimate traits, our findings expose a threat to the privacy and safety of gay men and women.
So these researchers were entirely aware of the problems that this had, and yet they released this. And, does it work, well, no.
This guy took a good look at it, found that the training data they were using was from one gay dating website in California, where everyone looked like this, had stereotypical piercings in particular places, and they were white, so it's really good at detecting people with facial piercings, who are white, and who looked in a particular way for a gay website.
Really what it's detecting is whether or not you're likely to appear on this gay dating website, and all the talk that they had about trying to understand the medical support for whether or not you had a gender preference was nonsense.
Yet, they still defend this, but you just look at the photo. And again, this is something you should ask for. This isn't impossible, even in a neural network, people think neural networks are black boxes, and you can do this, and look at the model and see where it's predicting the classification to say whether or not you're gay, and you can see there, it's red around where there's piercings.
So don't believe your own hype.
If you're a practising data scientist, it's very easy to see some really good results. I've done this myself, you're like: this is really awesome! Until you hit the real world and things break. So if things appear too good to be true, they probably are. Second rule: allow humans to shape decisions. In my company we're building this app to do data collection and one part of it lets you draw what you want your app to look like, take a photo, and it'll generate that app and a website out of that. It's easy, you just take some photo, do some magic, and you generate html and a mobile layout. Here's a neural network, it's awesome.
You can do this type of thing, generates html, awesome. And look, look at the numbers that come out. The accuracy is 99%, must be fantastic.
But, when you actually test it with users, it was really useless.
It didn't respond to user needs, users don't know what they want so it's much better to present the options to the user and let them choose from that, perhaps based on a photo of something that they like. Instead of trying to do the generation of this website, what instead we do is have a preset of templates, let them draw something, and do the selection. So that's what this is saying.
Look, it's a lot more reliable, you don't have the generation problems with generating invalid code, and it also solves a whole lot of other problems. Things like where do you put navigation on a generator website, do you try to make the person write in: I want navigation here.
Do you try to make them draw menus? All of those things are really hard for a machine learning approach to tackle.
But by turning into classification, which means selection out of pre-existing things, you can deal with that straight away.
So this is what it looks like, a very early prototype from around about May. So just take a photo, and there you get your layouts. So you can let them scroll through and you can see the top match is at the top and that generates it from there.
Generally, I think it is better to use recommendation over some other approaches, because it incorporates the human factor straight into it. It lets the human make those decisions.
If that's not going to work for your problem, then do selection which maybe a classification or an aggression-type problem if you're a data scientist. And if that's still not sufficient, then you start using advanced techniques like generation. In all these cases, the interaction with the user interface matters a lot.
If you look at your typical recommendation engine. Here's Spotify, neurals for A.I., you'll see the recommendation songs here.
And it's really intuitive for a user to go: oh yeah, type in something, alright.
It's not obviously searching on the words 'new rules', but these are songs that are like that.
You can see how it's easy for them to switch to something that they perhaps didn't know about, or to make a decision from that.
Selection is in technical terms is classification and perhaps regression.
So something like Shazam where you play a song and it tries to match that song.
So in practise, again, ranking the selections works better. So perhaps there's multiple versions of the same song and you can present them to the user, let them choose the one that it is, or you can do things like just, if you don't get an accurate match, present other options to say low probability of match, but lets them go through them.
And you'll notice that by scoring the matching, it turns it more into a recommendation problem. The user interface is gonna be the same.
So again, you can incorporate the human decision making into that.
And then you can do generation.
This is a fairly recent stuff.
(classical music) This is entirely artificial, no human wrote this. I'm not a musician by anything, but that was trained on effectively all the chamber music in the world that's pre-copyright. And then they get a neural network to try and generate its own, and it does good results. And indeed, when you're working with a large amount of data, these results can seem like magic.
These are entirely artificial faces, they're trained on a dataset called the celebrity data face, which is why they're all beautiful, but they're made up by a machine.
A process called a GAN, a Generational Adversarial Network, which has one neural network trying to generate a photo, and one trying to say whether it's fake or not. So if you look very very carefully, you can see some strange oddities around the corner of this guy, and perhaps the woman's eyes aren't perfect. But, I don't know, it's pretty good, and it's gonna get better.
Nvidia did this work.
Another rule: A.I. should be fast.
We built an application that was doing social media analysis, it was doing millions of rows per day, and people wanted to be able to use that. So we were using a product called Apache Spark, distributed system, and like most pieces of software it's not a silver bullet. So, when we first did our implementation, to just count the number of messages in a month of data, which was many millions of rows, crashing after four hours, but after a reasonable amount of work, we got it down to 4.5 seconds. So this is a really dramatic change and it changes the way that people use the tools. Instead of people going and using them as a batch system where they try and do some analysis overnight, they're able to do things interactively.
So people can ask questions in a meeting and you can find results straight away.
And indeed, I was running SQL on our multi-billion row Spark dataset in meetings and putting out answers like this and complex stuff, it's not your typical SQL, Spark can do natural language processing over all that inside a sequel query. I'm getting results consistently in this 10 second range. And that's a really different experience to this thing where you have to say: okay, ill get back to you tomorrow on that. And then iterate on that when someone goes: okay, that wasn't actually the answer that I wanted. People don't know the questions, but if you can explore the data, it lets them discover what questions need to be asked. People who have worked in software will understand the idea of pre-indexing.
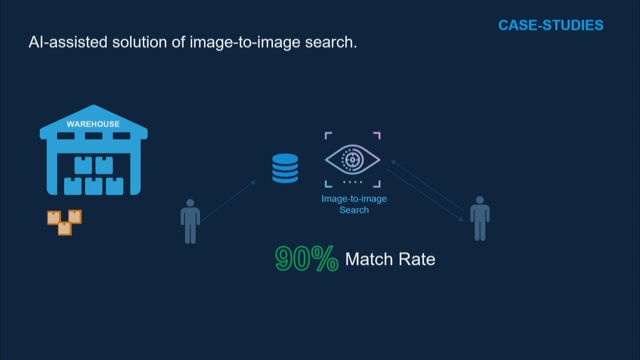
I know this is a little bit technical but there is really interesting work you can do here. You can build an index using a neural network to train similarities of any objects.
So they may be visual objects, they may be word objects, you can even do multimodal, so you can put both words, music, and photos in the same space, and train the distance between them.
Once you have this distance built, you can build an index out of it.
An embedding is a word that means a data structure that's got a whole lot of rows in it, columns in it I suppose, and these columns may be things that are interpretable.
So perhaps like how red is the object, how big is the object, and they may be not meaningful at all, they may be some combination of how angry and blue is the object.
But if you're careful, you can make these dimensions actually meaningful.
By using tools like this, you can do this up to a billion objects at the moment, and that's only gonna get bigger.
So things like facial matching for example, is very easy to do, you can build neural networks that match how similar faces are, put them into this, and you can find similar faces. You can do that for just about anything you can think of. And if you have these meaningful dimensions, you can do stuff like this.
Photo of a woman's top, and you add the pregnancy dimension to it, and you find tops that are similar visually, but are designed for pregnant women. That's the kind of application that I want to build. They're the types of things where A.I. can make a real difference, and can't do without it. There's no way that you're gonna be able to get people to type in descriptions of all these things that say all the different ways you can say maternity wear or the ways you can say 'suitable for pregnant women'. And yet, an A.I. system can understand what they look like, and add that pregnancy dimension to the query. And that's a really really powerful technique. You can do that for anything.
So, A.I. should disappear.
This was a demo Google did early this year. It's a thing called Google Duplex.
- [Receptionist] Hello, how can I help you? - [Nick] That's a real person.
- [Woman's Voice] Hi, I'm calling to book a woman's haircut for a client. - [Nick] This is a machine.
- [Woman's Voice] I'm looking for something on May 3rd. - [Receptionist] Sure, give me one second.
Sure, what time are you looking for around? - [Woman's Voice] At 12p.m.
- [Recpetionist] We do not have a 12p.m. available, the closest we have to that is a 1:15.
- So, that goes on and it goes and successfully books a hairdressing appointment for a woman after this backwards and forwards querying thing. Now you notice, both voices sounded human-like but they're also able to interact because Google had thought about how to make this seem human. By restricting the domain to booking very specific events, they were able to solve a lot of the problems around understanding human language.
Human language understanding is really hard, that's where I do a lot of my work and it's, you can say the same thing in so many different ways and people don't understand it.
And making machines understand it is even harder. But if you restrict the domain, that at least makes it approachable.
There's different expectations on response time depending on what people say. A complex sentence, something around scheduling requires thinking time and people expect that. And if you give an answer straight away, it's very strange, but at the same time you say hello, people expect the hello back straight away. And you've noticed this on phone calls or, God forbid, Skype calls, where you get the delay in the call, and people are going hello h h hello? That's because you're not matching the expectations of the people, and so Google have noticed that and have made the different types of responses varying in time. And by adding in little things like this, the 'umms' and 'errs', it lets you know that there is still someone on the other end of the line, and makes that conversation flow.
And, it gives you more computation time.
So if you need to do look-ups, doing 'umm' lets you do that look-up, and there's no cost to that in the conversation, because people expect the human to be doing these types of things. Now Google are actually shipping this now I believe, but they've restricted the domain even further to suspected spam call filtering, so they're where you're not wasting the other persons time because you think it's a spam call, I think they feel that this is a reasonable place to deploy this first, and I believe they've released that in the latest version of Android.
So, consider adversaries.
I was very worried about this part when I saw Caroline's talk but we don't have the same examples, so it's awesome. A.I. is rapidly becoming a non-traditional cyber-security field.
Harassment is one area, but there's a lot more than this. Traditionally, spamming SEO on search engines. You know, your keyword spamming, and then people started doing link graph manipulation to try and increase the ranking of their website. Now that's an adversarial use of machine learning, people are well familiar with this.
Now we start seeing social media manipulation, fake news, which is a real thing.
It surprises me that the same people who believe advertising works think fake news doesn't work. Leave it like that.
And deep fakes, which is things like the photos that you saw earlier, but doing things like this. So, I won't let that finish, it goes on and it's pretty impressive.
That's a model you can download from the internet now, you can train it on your own stuff, on Reddit people do porn, which has been banned, but nonetheless, of course.
But, just this voice acting type thing where it changes both the sound of the voice but also makes the facial expressions match what the person is doing, it's really impressive, the technology is amazing, the positive aspects of it are impressive as well, but obviously there are negative problems.
So just be aware of that when you are deploying these type of technologies.
The way that you think people are going to use it inevitably won't be, and A.I. is particularly vulnerable
to this type of thing because of the other problems that I've said about the difference between real world data and your training data. Caroline talked about facial analysis earlier, about emotion detection, and this is a really good example. I've got a model running on my computer that I downloaded doing that exact thing.
It uses the camera on this, you can stand in front of it, smile and it goes happy, frown and it looks sad, it works really well for me until I very embarrassingly tried it with a friend who's black, he's Indian actually, and it didn't work at all and then we realised that we had no idea where this training data had come from, but apparently it didn't understand that skin colour could be different.
Because it's looking basically at your lips, and the contrast in tone between your lips changes for people. So, that's the kind of problem, you know, the HP example that Caroline showed, it's embarrassing. And in some circumstances, it can be a lot worse than embarrassing, so just be aware of that. So in summary, consider your training data. The world is a lot bigger place than you think it is. Prefer tools which include humans.
A.I. is powerful, and it's fast, but humans often should make important decisions.
Make A.I. fast, because nothing is more frustrating than something that's slow, and making things fast is systematically different as well as a slow system. And make it disappear, the best systems are ones that people don't notice are there at all. Consider your adversaries, and if you've got questions, that's my contact details, I can take things now as well. (upbeat electronic music)
Modern applications are increasingly using A.I. and machine learning to drive important parts of their functionality. While there has been significant progress on improving the raw algorithms powering these systems there has been little thought put into *how* they should be used within applications.
In this talk, Nick will show examples from 4+ years experience in running A.I. driven products of the different concerns one needs to consider when integrating these tools into applications.