Machine Learning Today
(upbeat electronic music) - So hi everyone, my name is Paul, I've been doing machine learning since 2009, I was fiddling around with neural networks and reinforcement learning back then, for my honours thesis for my electrical engineering degree. So you can find me on Twitter here, all locked in. I like to tweet about all things machine learning related. And, yeah, I think actually Twitter's a pretty good platform for finding out about the latest and greatest in machine learning. So, as Tim mentioned, I'm the founder of Sydney Machine Learning, we are the largest group of practising machine learning practitioners in Sydney.
And I'm also the founder of Star AI, which I'll talk to you about a little bit right now. So, through my work in this field, I've been lucky enough to meet a lot of different people in the machine learning space, and I've found three intersecting problems that work together quite well, to achieve, essentially the top thing.
So, I've run a lot of courses, like educational courses, and through that I've found that I know that there's a lot of like professionals right now, a bit, like developers, or graduates coming out of university that are trying to transition into the machine learning field.
But, there's this problem called the cold start problem. And what it is, is getting your first foot in the door, essentially, so once you got your foot in the door, once you got your first job, then your career's set up and you can go for gold, but getting that first job is really hard.
The second side of this, the second circle on the left, companies that are trying to apply machine learning, is the second problem, there's essentially two parts that make that part up, the first part is that machine learning talent right now is expensive, it's very expensive. So a lot of emerging machine learning companies, find it hard to hire these people because they're expensive. The second part is that there's not really a lot of them. So through my work in Sydney Machine Learning and teaching all these courses, I've come to find that there's a lot of people that want to transition that have really high skill sets but they just can't land that first job. And I think that there's a good matcher between emerging ML companies and professionals that want to transition into machine learning.
And finally the last part is research.
So I myself am kind of faced with this problem and I meet a lot of people that are faced with it too. And that is when you get to a certain level in Sydney, there's pretty much nowhere to go, you have to go to either, you either have to go to San Francisco, I mean there's CSIRO, there's the universities, that you can go to, there's a handful of high-tech startups that you can go to, but apart from that, once you reach a certain level, you pretty much have to go to San Francisco. So I myself have been working really hard on the top one. And yeah so I'm now heading up Star AI.
And what it is.
So, Star AI Applied Research.
And what it is is, if you are a machine learning engineer as a data scientist, the general goal is that we're gonna send you out as a consultant for four days, three to four days where you get to work in an emerging ML company.
And then on the first day, you pitch us a machine learning project, be it whatever it is, say dealing with doing work with GANs or whatever, and get to work on your research idea.
This is kind of like how Google has that one day off a week where they get to do whatever they want.
In this case, the whatever you want is your research idea, and that one's on us. So yeah if you are a machine learning company that needs talent, or if you are an emerging ML company, we'd love to hear from you.
Feel free to contact me at that address.
Contact@starai.io Alright.
Alright, so, this is the format of today's talk, I'm pretty excited to be giving it to you guys. The first part we're gonna briefly talk about why we're even talking about machine learning in 2018. The second part is the main focus of today's talk, which is what machine learning is capable of in 2018. And then we're gonna run through some basic ML algorithms. Feel free to take pictures of the slides, because if you want to get into this, there's some resources, which you can pretty much follow up after this talk, and that should lead you onto being able to implement machine learning yourself.
Alright, so, today I'm gonna introduce three fundamental, key concepts that machine learning can do in 2018.
And then I'm gonna, we need to introduce those before we jump into explaining a couple of algorithms. And how they work.
Okay, so that is what today is gonna be all about. So what can machine learning do in 2018? So the first idea is classification.
And a lot of this stuff is trivial, it will seem trivial to a lot of you, we're building these ideas and we're gonna sort of layer this on like cake, so you can understand the later concepts.
So the first one is classification.
It's pretty straightforward.
It's the idea of like, say you're trying to, you've just washed the dishes, and you've got a whole bunch of knives and forks. You take the knife, you look at it, you say okay that's going in the knife bucket. Got a fork that's going in the fork bucket. Got a spoon and so on and so forth.
So this is kinda similar with machine learning. So you've got a, you're analysing a whole bunch of customers and you're looking for fraudulent behaviour, what you do is take the customers, run it through some machine learning and you put the fraudulent customers in the fraudulent customers bucket, and all the customers in the other, in the good customers bucket.
So that's classification in a nutshell.
And there was this famous use case, in 2016, I believe, where a Japanese farmer, traditionally he had to hire people to sort cucumbers. To look to see whether like it was a good cucumber it didn't have any, there's nothing wrong with it or whatever.
But what he did is he went and he used a machine version, and essentially did classification. He looked at the cucumber from different angles and was like, okay this is a good cucumber, we'll keep it.
And in this example you can literally see it's going in a bin, like we were talking about with classification.
It's going in the good bucket, which is the one on the right.
One on the left, it goes to the bin.
Right, so, that's classification.
The next one's prediction.
Again very trivial.
Prediction is essentially just predicting some number in the future.
So, for example, say the weather.
We've been doing this for like, almost 100 years, you know. Trying to predict, based on a whole bunch of data, predict some kind of future outcome, that's prediction in a nutshell.
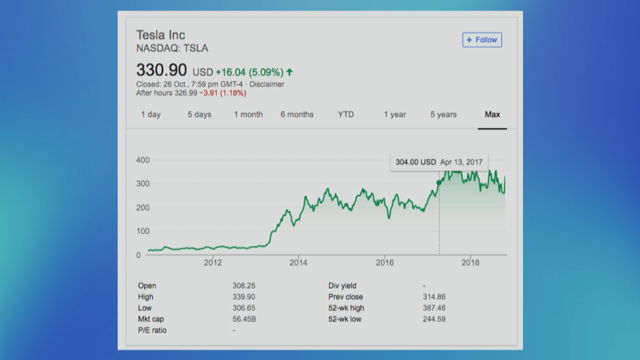
So like a classic one is predicting stock market shares. So say for example you've trained a model on Tesla's stocks, which is quite volatile at the moment. Yeah, you can use machine learning to kind of do prediction of some kind of metric in the future. And the third one, which is the topic which I'm, myself, am most excited about is control. So, you can do control with machine learning in 2018. And there's various ways of going about this. But, like, one of the most famous use cases is Google's Data Centres.
So they acquired DeepMind, I believe, in 2015. DeepMind is a machine learning research company for those who do not know.
And they applied DeepMind's machine learning technology to Google's Data Centres.
To get across the significance of this, these data centres are really, like highly optimised. So they've already hired a whole bunch of engineers to come along and like make sure it's all running really efficiently.
They applied the machine learning technology on top of what was already there, and were able to save 40% in like power reduction used by the data centres.
So just by itself, just by that number, DeepMind was able to like essentially pay for itself. So those are the three things.
We talked about classification.
You can do classification in 2018, you can do prediction, and you can do control. There's a whole bunch of other sort of minor ones, but those are the three majors.
Alright, so we've sort of set the stage now by talking about what machine learning can do. Let's now talk a bit about the different types of machine learning that exist.
So there are essentially three major flavours of machine learning.
There are supervised learning, and we're gonna be spending the most time, this talk on supervised learning, and you'll see why in a couple of minutes.
The next one is unsupervised learning.
And the final one, reinforcement learning.
Alright.
So, supervised learning.
So if you are looking to transition into machine learning right now, I suggest you spend most of your time on supervised learning.
The reason being is this is where the money is at at 2018. Okay.
That's the reason you should learn about supervised learning.
So, what is supervised learning? Let's say you have a data set of images, and associated labels that go with those images. Let's say we have an image of yours truly.
Another image and an associated label that goes with that image.
And another image.
So the way supervised learning works is you have your input data sets, and the labels that are associated with that input data. You pass your input data into the machine learning model, it then produces either a prediction or a classification on the other side.
You measure the error between your label, yes or no, Paul or not Paul, and then push that error back into your machine learning model, and that updates it and makes it a slightly better predictor or classifier.
So what you're essentially doing, with supervised learning, is mapping your input data to the labels.
That's essentially what you're doing.
You're creating a map between your input data and your labels.
Right, so, here's a little concept, I'm just gonna quickly go through this.
You need to bookmark this in your mind for the rest of this to make sense.
Alright, so.
In machine learning, if we have a data set, and let's say in this example we are trying to predict house prices and we have some data here.
If you have a table in machine learning we call features, the columns going right.
So all the columns going right to our features. So number of windows, number of bedrooms, size, you could have more, for example, if it has a pool or not. If it's a high-crime area, et cetera.
And the next thing.
So we call, as you go down, your rows, or what we call observations.
So here we have four houses, there's a little typo there, but yeah let's say you have a thousand houses in your data set.
There'd be a thousand different rows.
A thousand different observations, in your data set. Alright, okay, so.
There are many different heuristics that data scientists and machine learning engineers use to, when we decide which model we're gonna use to apply to a data set.
There's quite a few.
But the main one is the size of the data set, okay? So based on the size of the data set, it's usually the main heuristic we use to decide which machine learning model we're gonna be applying to a specific problem or whatever. So over here we got prediction and classification. Two of the tasks we talked about earlier.
And in the middle we have a column of number of observations.
That's saying, so that's the size of your data set. So let's say we had between one and a thousand different data points, different rows, in our data set. If we were gonna be doing prediction, a good model to use is linear regression.
This is quite an old one, it goes back to like the early 1900's.
But it is solid for data between one to a thousand observations.
And it kind of works as follows.
I'm not gonna go into the very specific details of how this works, but just from a very high level, 'cause we only have a limited amount of time in this talk. Linear regression kind of works like this, you have a data set, and you're trying to fit a straight line to approximate the data set, to try and make some kind of approximation of it. Once you have fitted your model, as we like to say, you can then make predictions on it about data you don't know about.
So let's say for example in this case, I have been trying to study for a test in machine learning. And I want to know if I study for 67 hours, how well am I gonna perform on the test? I can read up the line, read off my model, and know that I'll be, I'll get 98%, if I study for 67 hours.
So that's linear regression in a nutshell.
Same thing, so that was for prediction.
For classification, you know, the whole buckets thing, where you like a picture of Paul, a picture of not Paul, if you've got between one and a thousand observations in your data set, a fairly good model to be thinking about here is logistic regression. This is a tried and tested model.
And kind of looks like this.
So, let's say you are trying to predict whether there's like cats or dogs.
There's two classes there, cats or dogs.
All logistic regression does is it's sort of fitting a boundary between one class and another class. So we could have like cats on the left and dogs on the right.
The beautiful thing about logistic regression is it works, we talked about those columns earlier, the number of features, like number of windows, number of pools for your house.
Logistic regression works like, in dimensions. It's pretty good.
Alright, so, we've talked about one to one thousand. Now, if we pushed the amount of observations, the amount of rows in our data set, between one to a hundred thousand, from a thousand to a hundred thousand, what sort of models can we use there? So, this guy, decision trees, is a sort of a staple of the data science world. And the reason being is that you can use it for prediction or classification and it has this really beautiful property that it is, something which is known as interpretable.
Now what does that mean? So, interpretability is a big issue in machine learning. And what it means is, say for example I created a model that I was gonna use to predict whether I'm gonna hire somebody or not. I'd like to know, like I'd like to be able to open up the model and see how it's making its decisions.
Okay? And one way to do that is use this model which is called a decision tree.
So we train our model.
And we open it up and we can kinda see, it's essentially a set of like flows, like is my potential candidate a certain age? What's their education level? Et cetera.
Yes, no, yes, no.
So that's decision trees in a nutshell.
This guy, random forest, is essentially like the bread and butter algorithm of the data science world at the moment.
And the reason being is it's a sort of, it's a derivative of decision trees.
And it can do prediction or classification, like we talked about at the start of this lecture. Or talk.
Yeah, it's a derivative of decision trees and how it essentially works is, a very high-level overview.
You train multiple decision tree models, okay? You train.
And you tweak the parameters of each decision tree model just slightly.
And then what you do is you take the aggregation, the output of all the different decision trees, aka a forest, and you take the average of that, and that average is your prediction or classification. So that's kind of how random forests work.
And that again is the bread and butter algorithm. So if you wanna get into machine learning, I suggest you learn that guy.
Also as a side caveat, there's a lot of talk at the moment about big data and all that jazz. Most companies that are trying to get into machine learning right now, their data sets are in this size range.
Between one thousand to a hundred thousand observations in their data sets.
There's a lot of companies out there, and that number's gonna increase over time, obviously, but right now, that is roughly the numbers of observations that most people have in their data sets.
Okay.
Now we're gonna move to sort of the high-level algorithms. So if you have a hundred thousand plus observations in your data set.
But, pretty much the main algorithm that's used in production is something that's known as XGBoost.
Okay? Now, I'm not gonna dive into this, but XGBoost essentially borrows sort of the best ideas from random forests and the best ideas from something called gradient boosting, and combines them together and gives you the best of both worlds.
And this algorithm is implemented in like big data set things like Doop and Spark so you can make use of it there.
Some examples of companies that are using this are like big banks who have massive data sets, aeroplane companies, you know, they'll have lots of data, they can process, so those sorts of companies. And finally, we get to deep learning.
So there's been a lot of hype around deep learning, in the last two years.
Unfortunately actually, deep learning has not been used very much in Sydney at the moment, there are very few people that are actively using deep learning.
Multiple reasons for this.
Mainly because I'd say Sydney is a little bit behind, let's say, but also being it's not exactly the most easiest algorithm to just get going off the get-go, okay? Deep learning's a little bit more complicated, so. Deep learning, you must have heard, is like roughly inspired by how the human mind works. Yeah, it's got some really beautiful features, though, that I really wish that this model was being used more in Sydney, because it can essentially infinitely scale, so you can feed it as much data as you want, and it just becomes more and more accurate. That's essentially one of the great positives of deep learning.
Okay, so, right now on the screen, you have a whole bunch of algorithms, that you can like take a photo of and start learning after the session.
There's a really great library that's implemented in Python called Scikit-Learn. I suggest you go take a look at that after this. That'd be like the first port of call, if I was gonna be learning machine learning in 2018. It's quite easy.
Alright, so we talked about supervised learning, that's the bread and butter side of machine learning right now.
I'm gonna quickly dive through the other two. So we have unsupervised learning.
So, unsupervised learning is essentially when you have your data, like your data set of images like we had before.
But you have no labels for those images, okay? And what you're trying to do is automatically generate the labels for the data.
So, the most commonly used one, as a data scientist, this is pretty much the only one you need to know, is one called K-means clustering.
And, what it is is, you essentially say okay, I've got this massive data set, I want to group my data into five different categories, for example, and the algorithm will automatically run through the data and like make groups of five, because you said I want five groups.
And what's going on there is you essentially are assigning the label of the group to the data, that's essentially unsupervised learning, in a nutshell.
So, the best way to understand it is just to see it. So here we're running it on five groups.
And you can kind of see in this image, that the label now is the group that the data belongs, the label will be, from the group, has been attached to the data, in a nutshell, is what's going on there.
Okay, so, that's kind of what you need to know as a data scientist.
I'm gonna now go through, so that's like the data science money side of things. We're now gonna go through, like the cutting-edge stuff, the stuff that's emerging on the horizon, okay? Spend some time on that.
Right, so, there's a famous machine learning researcher called Yann Lecun.
And he says that supervised learning which we talked a bit about just before we gave you all those algorithms, that's the icing on the cake, okay? Where the really big progress is gonna be, is in unsupervised learning, which he represents on this diagram, as literally the cake.
And unfortunately, we actually haven't made much progress at the moment in unsupervised learning. I mean, K-means, which I showed you before, is actually trivial.
But, there is something that I want to show you, where we have made progress.
And that's artwork generation.
So this is gonna be huge probably in the next twelve years, is sort of generating artwork, whether that's speech, people's voices, actual pieces of art, textures for games, characters themselves, et cetera, et cetera. So, picture of yours truly.
So let's say for example I wanted to paint myself, using Vincent van Gogh's sort of style.
What I can do is I can apply this technique called General Adversarial Networks.
I ran this on the weekend.
And yeah you get something that looks pretty similar to a piece of art that would have been created by Vincent van Gogh. And this sort of level of technology is, it's here and now.
And it's only getting better.
So artwork generation is something machine learning can do right now.
Another example is this.
This was a piece of research from last year. Guys applied the same techniques to transform a horse to a zebra, and you can see that there's like some errors there, but like I said, like, this year we've actually taken this technology even further, so yeah. So that's unsupervised learning in a nutshell. Now when I get to reinforcement learning, this is where I got started in machine learning. Way back in 2009.
And I'd just like to share with you a little bit about this, and then we'll wrap it up. So, what is reinforcement learning? The best analogy is kind of like how you'd go about training your dog to give you the paw. So what you do is you, you put your hand out, you take the dog's paw and you put it in your hand, and you give it a treat.
And you repeat this process, you do it over and over, you put your hand out, you take the dog's paw, put it in your hand, give it a treat.
And over time, the dog's brain begins to associate, I'm gonna get a reward when the master is putting out his hand.
So that's essentially reinforcement learning in a nutshell.
We train our models and we assign them like reward labels, either positive reward for something that we'd like them to do, or negative reward to discourage things that we wouldn't want them to do.
Okay.
And this is the technology that powered DeepMind's system that beat Lee Sedol, the like, the Roger Federer of the Go world, Go is a Chinese board game.
And, yeah, this is the technology that powered that, so I'd like to just show you a couple of examples of other things.
But first, State of the art RL, if you'd like to know a little bit about this yourself, there's three major ones, there's Proximal Policy Optimization, that's an algorithm that was invented by OpenAI. And has recently had much success, I don't know if you have seen it, there was a lot of publicity around DOTA this year, that was Proximal Policy Optimization at work. Rainbow, that's an algorithm by DQN.
And IMPALA, that's another algorithm from DeepMind. So if you wanna get state of the art RL, those are the three you need to know about. And I just want to show you some use cases. So on the left here, we have an example from 2008 where reinforcement learning was being applied to a little model helicopter running on petrol because we didn't have electric drones at the time.
So Stanford University was just using a little petrol helicopter here.
(drone buzzing) And they trained it to do little aerobatical manoeuvres. And this is using reinforcement learning.
So again it's all about essentially controlling things, making decisions.
And they got the little thing to do some really crazy manoeuvres like, over here you can see it do stationary rolls. Flies upside down.
It like imitates like a clock.
And that's all autonomously, using reinforcement learning. And this here is the latest success from this year. It was actually just a couple of months ago. So Open AI trained a hand using Proximal Policy Optimization, which is that algorithm I just talked about. So what they wanted to do was face the objective is in the bottom right-hand corner there, so like let's face E to the camera.
And the craziest thing about watching that video there, is it almost looks like a human hand, how you would manipulate a block to do the same task. So say you wanted to face O towards the camera, you know, you could see yourself doing the same thing. And finally this guy, so some of you may have seen the machine learning guys may have seen this already, but for those of you who haven't.
Back in, yeah, this is a success from 2015. DeepMind trained one of their reinforcement learning algorithms to play the game of Atari, and right at the start you can see, it's not behaving very intelligently, it's just sort of missing the ball.
After 200 training episodes, it starts to play it a bit like how you would imagine a computer to, it's like very sporadic, it's not flowing.
After 400 training episodes, it's starting to play a lot like a human would.
So like it goes to like match the trajectory of the ball. But the real magic happens around the 600 episode mark.
So around the 600 episode mark, the algorithm figures out that the best way of playing the game, and the way to do that if you want to know, is you build a tunnel on the side and then what it does is it bounces the ball around the top and maximises the score.
And this is all autonomously, it figured it out itself, so that to me is pretty crazy.
So if you want to know more about reinforcement learning, I would suggest you go and check out a library called OpenAi Baselines.
You can get it at this address which is currently on the screen.
This is the stable version of it, which is a fork.
But, the people here have gone to the effort of like commenting the code and making the variable names interpretable so you actually know what's going on, et cetera. So, yeah, that's it from me.
I hope you got something out of that, and thank you. (applause) (upbeat electronic music)
Due to the hype in the media recently around the recent advances in Deep Learning, machine learning & Ai has been touted about with images of terminator and a doomsday scenario or, as a panacea that can be used to solve any problem – and I believe there is currently a large misunderstanding of what machine learning is & what it can do for your business.
The giants such as Google, Amazon & others, have a firm understanding of what Data Science, Machine Learning & Ai can do to empower their businesses. So do startups, working with very specific machine learning algorithms to solve new problems. However, I believe there is a massive gap “in the middle” where a lot of companies that are not yet familiar with machine learning tech, could benefit immensely from Data Science, Machine Learning & Ai and use it to improve their business systems.
In this talk Paul, co-founder of SigmoidOne and the Sydney Machine Learning meetup group will:
- Demystify what machine learning is capable of in 2018,
- Introduce a couple of easy to understand core concepts that can
- Teach you how to identify “machine learning addressable” problems within your business that you can start working on to improve your business today.