The ins and outs of LLMs

Introduction
Paul Conyngham introduces himself, highlighting his 14-year experience in artificial intelligence, and his involvement with supermarket chains, banks, the defense department, startups, and the Data Science and AI Association of Australia.
Overview of Large Language Models
Paul explains the concept of large language models (LLMs), focusing on their development history and the evolution from GPT-2 to ChatGPT, and how these models have transformed the AI landscape.
How Models Work
He details how models function by transforming input data into outputs, using an example to illustrate how this process is similar to human sensory and response systems.
Sequence to Sequence Models
Paul delves into the specifics of sequence to sequence models in LLMs, emphasizing their predictive capabilities and the importance of understanding these models to implement them effectively in business.
InstructGPT and Instruction-Based Training
He discusses InstructGPT and the key breakthrough of training models on instruction-answer datasets, explaining how this approach significantly enhances the models' ability to provide accurate and relevant answers.
Context Window in Large Language Models
Paul explains the concept of the context window in LLMs, likening it to the model's short-term memory, and elaborates on its significance in processing and responding to inputs.
System Prompts and Controlling LLM Outputs
He introduces the concept of system prompts in LLMs, detailing how hidden instructions guide the model's responses and how users can manipulate these prompts for specific outcomes.
Vector Databases and Long-Term Memory
Paul describes vector databases as a method to provide long-term memory to LLMs, reducing hallucination in model responses and ensuring more reliable and relevant outputs.
Summary and Closing Remarks
In his concluding remarks, Paul summarizes the key techniques for building and deploying LLMs, highlighting the importance of context windows, system prompts, vector databases, and fine-tuning for specific business applications. He invites attendees to connect with him for further discussion.
Hi guys, as John alluded to, my name is Paul.
I've been working in the field of artificial intelligence for 14 years.
I started out in 2009.
Was lucky enough to do, to work on this with, for my degree all the way back then.
And since then I've been lucky enough to work with clients ranging from supermarket chains, to banks and the defense department and a lot of startups.
And I'm one of the co founders of the Data Science and AI Association of Australia.
And also, as John said, run my own consultancy called Core Intelligence.
Specifically with regards to large language models, I've been working on GPT based solutions since 2019, when OpenAI released GPT 2, which back then was a game changing technology in my field, and it's only gotten bigger and bigger.
First with GPT 3 in 2020, that sort of exploded, with, in the space of startups and then in 2022, at the end of 2022, when OpenAI released, ChatGPT exploded across, everyone got access to the technology.
Okay.
So I was tasked with the extremely hard problem of trying to explain to you all what large language models are and specifically how you like, what is the best ways of using them and how you can go about thinking how to use them, how to implement them, if this is something that you're looking at adding to your business.
So to get started, the best place for that is to start with how they work.
So one of the things Kaz did not do just before is explain what a model actually is.
So a model is essentially just a mathematical function that takes some inputs.
It can be picture data, it can be text data, it can be a single variable.
It goes into a model and that transforms that data into some other output.
So everyone in this room does this.
You're taking data through your eyes and your ears and your nose.
And you translate that into actions with your hands or talk or whatever.
So that's what a model does, in a nutshell.
Specifically with regards to large language models, all a large language model is what's called a sequence to sequence model.
So it takes in a sequence.
In this case, we have a sequence on the screen here.
The cat that's on there is the sequence that it takes in.
And all the model is trained to do is predict the next most likeliest thing, okay?
So it just takes in a sequence of things.
And predicts the next thing.
That's all that's going on under the hood.
To give you an understanding about how you can go about implementing this in your business, you have to go a little bit more under the hood to understand how to build a GPT.
And some of those concepts will transfer across to how you can implement it in your business.
The first thing to make a chat GPT, what you gotta do to make one of, a model that can do this, what OpenAI did, is they took pretty much all the data on the internet, the text data, they trained a model to take in all those sequences of sentences and stuff as the input, all the data, they trained it, and they, all they did was, all they did was predict the next word using all the data on the internet.
Taking in all the data of the internet, Pushing it through is the input, and just to predict the next word.
So if you have something like this, the cat's sat on there, and you have a model that's trained on all the data on the internet to predict the next word, hopefully it'll give you, hopefully it'll give you that as the likeliest output.
So this is around this is GPT 3, this is around 2020, that this, that they were doing this.
And just to show you what this looks like, I'll give you a quick demo.
So this here is the OpenAI Playground.
It's like the More advanced version of ChatGPT, and we're going to use a model here that's a little bit more older.
This is GPT 3.
Using GPT 3, when I press submit here, hopefully it'll give us the answer we're looking for.
Congratulations, GPT.
So this is this here is circa 2020 technology.
If you want to build a ChatGPT, OpenAI added a couple more tricks to it the most important trick, which I'll show you now.
So around 2020, 2021, OpenAI released this paper called InstructGPT.
And the key thing that they've figured out is, because these models can predict the next word, if they can train them on instruction answer datasets, where an instruction is the input, and the output is an answer how can I, how say the instruction is how can I pick up that glass over there, and then the output is a detailed set of instructions.
It turns out that these models became, are very good at being able to give an answer based on instructions.
So you've got your input is instructions.
You got GPT-3 as the base model and they train it on in instruction onto datasets, train the model, and an instruction onto dataset looks something like this.
This is straight out of the Instruct GPT paper.
So you can see on the input, they would've put instructions and as the, on the output, they would've put these answers.
So this is straight outta the instruct GPT paper.
You can see some of the use cases that they were training.
The thing on back then, this is 20 20, 20 21, was brainstorming, classification, open question answering, and this is why ChatGPT is actually so good at all these tasks because they've actually gone and trained it on specific use cases and a whole bunch more down here, like millions of them.
Okay, so once you've taken a base ChatGPT 3, which is just predicting the next word, you then fine tune it, you train it on question answer datasets, you get a ChatGPT.
And if you give it a question, hopefully it will give you an answer.
And as of July, it will probably give you something similar to that.
Okay, so with all that being said, those are the two primary technologies that they, or tricks that they use to get to ChatGPT.
And is there anyone in the room here that has not used ChatGPT?
If you'd like to raise your hand, so everyone here has used it.
That's incredible.
So those two things, plus this other technique that I won't go into, got us to chat GPT today.
So with those concepts explained at a very high level, hopefully that'll be good enough to build a foundation to teach you how to build GPT apps.
Okay.
So the first thing you need to know about GPT is it has this thing called a context window.
The context window in a nutshell is essentially the working memory of the large language model.
Said another way, it's like it's short term memory.
So everyone in this room has a short term memory.
It's plus minus 30 seconds.
And then hopefully some of what I'm saying gets stored in your long term memory.
Hopefully that happens.
In a nutshell, we all have short term memory.
A good analog to a context window is the LLM's short term memory.
To explain in a bit more detail what it is, let's look at an example of a toy large language model.
Let's assume that our toy large language model has a context window of 100 characters.
So we have the same situation before, we have an input, an output, and we have this toy model in the middle.
It can only, it has a context window of 100 characters.
So the scenario that we're looking at looks like this.
We have an input which is and an output, together, the total amount of characters, if you count all the different characters here, adds up to 82.
So the context window of a large language model is the net sum of the characters on the input and the output.
It's not just the input, it's not just the output, it's the sum of both.
That's the key thing.
And that is like the Large language models, short term memory, and this is very important as I'll demonstrate in a second.
So you can think of it as a, as your short term memory.
So all these models have different context window sizes.
This is very important if you're going to be building one of these systems.
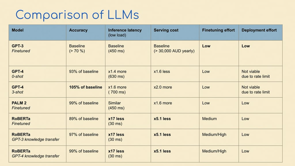
GPT 3, the original one I showed you just before, had, has, had about 4,000 tokens.
A token, by the way, is not a word it's a sub word, it's a sub byte word, but.
It's roughly analogous to a word, GPT 3 had 4, all the way down to GPT 4 which came out around May has 32,000 and Claude 2, which came out this month has 100,000 tokens.
This is why this one's so good, but we'll get to that in a second.
So for all of you guys in the audience, I'm not sure if you're aware that there's this Web Directions has this video portal where all the videos, I believe, that have ever been of presenters like myself that have ever talked, have they their talks stored on this web directions portal called Conffab.
Conffab has the video and that it also has a transcript here of what the speaker talked about.
So I'm gonna grab, to demonstrate, for the importance of a context window, I'm going to grab the transcript of this talk and plug it into the original chat GPT.
Okay, so we're going to go back in time to the original chat GPT.
I'm going to paste it in here.
I'm going to say something along the lines of, give me a summary.
Now I'm sure all of you who have played around with this technology extensively have may have encountered a similar error message to this.
If you paste in documents that are too big, That have got too many words in them, you'll get a message like this.
You've exceeded the large language model's context window.
It's short term memory.
It's like really important.
Now let's go up to the latest and greatest one.
GPT this one I think is the latest.
If we ask it for the same summary, let's see what happens.
Okay, so the latest version of GPT 40613 can handle that much words in it's working memory.
Really important if you're going to design an app using GPT based technologies.
And last but not least, we have Claude, which is the this new model that has a context window of 100,000 tokens.
If we paste in the same conversation from a Conffab and ask it for a summary, it's able to do the same.
Okay, so that's context window.
That's really important that you all are familiar with what that means.
The next thing is system prompt.
Just like I explained to you at the start, how the first thing they did was create a sequence to sequence model that can predict the next word from the math.
The next step that they did was train GPT 3 on question answer datasets.
And it turned out by doing that, it made GPT 3 really good at following instructions.
So that's why you can tell it to do, write poems or whatever.
But it's so good at following instructions that there's, they actually provide a hidden thing called a system prompt.
So the system prompt is a hidden instruction that's hidden between any message that you send GPT.
You can't actually see it, but it's hidden there.
This is what the model is following when it's carrying out any one of your questions to the thing.
So another way of thinking about the system prompt is that it is like you're telling chat GPT to imagine what it should be.
It works like this.
Your system prompt is hidden above whatever you want to ask chatGPT to do.
The system prompt gets appended to your question that gets pushed into GPT and then it produces a different answer.
And I'll demonstrate this for you too right now using the OpenAI Playground.
So what I'm doing here is directly giving GPT the system prompt that you can't usually see.
That's hidden.
I'm putting it above the message and then I'm going to ask him a question like you normally would.
So there ChatGPT answered with emojis.
It gave us Earth, moved to a black thing.
Earth, let's try one more.
There's telescope.
Okay, so the, in a nutshell, it's saying that but look, this seems, sensical.
It's using the right emojis for moon.
It's using Earth.
It's saying that it was transformed.
It's trying to explain how it got round.
It's doing what I instructed it to do.
And I tested this just before coming in here, but this feature was actually added this morning to ChatGPT for everyone.
So if you if you have a Plus account, so if you come down here and click this button go into your settings, go to beta features, and add on custom instructions.
You now have access to the system prompt that you never had before.
So you can go in here and change the custom instruction and make it whatever you want to be.
I'm a computer scientist, you tell it a little bit about yourself.
And you tell it how you want it to respond, and now, it will, you're changing the hidden message before, whenever you add input into the thing.
There you go.
So that's system prompts.
Last but not least is vector databases.
Okay, so we talked about the fact that a large language model has this thing called a context window.
And you can think about that as its short term memory.
It also has the ability to have a long term memory, and these are called vector databases.
The context of how they work is beyond the scope of this talk.
I'm not going to dive into how a vector database works.
But in a nutshell, all you need to know is that you can think of a vector database as the long term memory of an LLM based system.
And the data gets, so if it's going to store the data into its long term memory, it stores it into a database and the data gets represented as numbers.
That's essentially the gist of what it's doing.
So why do you want to give it long term memory?
These systems have a propensity to hallucinate.
So if you've ever asked for a question, it sometimes gives you an answer that seems very confident about it'll tell you, how is the Statue of Liberty made?
It'll say, all right.
It was made in South America and be very confident in its answer.
But we don't, obviously, if you want to deploy this to an enterprise grade solution, if you're deploying this into a company, you don't want it to be hallucinating information.
So one way to solve that is to incorporate a long term memory and you can do that with a vector database.
So how you do this is as follows.
You have your base GPT model that we've talked about how you make already.
You add a system prompt.
We've talked about that as well, that the sort of hidden message that you use to control your GPT model and the system prompt.
So say the user asks, why should data science, why should a data scientist worry about UI UX?
Say, that's the question.
We push the question into the system prompt is then sent to the vector database.
We query the vector database, get that information that's relevant.
So say there's some documents in there that are relevant to the question.
Pull the documents back as another prompt into the system prompt and then feed that into GPT.
So in a nutshell, you take the question, you put it into the prompt.
You ask the question to the vector database.
You get back the documents that are relevant.
So you may have some documents that are relevant to that question.
You insert those as text back into the prompt and you feed that back to GPT.
And it turns out that this technique it's called RAG.
Significantly reduces hallucination for large language model systems and helps drive them to have long, longer memory.
And I'll quickly give a demo.
We've just got enough time for one more demo.
Web Directions has this portal called Conffab, again, with all the talks that have ever been given at this conference.
And what I did is I went and grabbed the text from three of them.
I grabbed the text from the design patterns talk, the data science UI UX talk, and the open source talk, and fed that into a vector database.
What you have to do is you have to encode the data you loaded in, and I did that.
In this step, so here I load in the data, so I load in those files to try to extend the thing's memory, to give it long term memory, and here's a sample of the data that I loaded in just before.
You can see here, I hope that you all had a good lunch, is from right here.
Then you have to convert these things into what's called vectors or embeddings, so you convert them into numbers essentially.
And put them into the, and put them into the database.
I used Weaviate for this.
And then you query the database.
So you query the database just to test that it's working.
And then last but not least, you, you do the step that we just talked about before here.
So you have your question come in.
Your question gets inserted here.
You then ask that question to the vector database to pull back the relevant document.
You insert the, that document into your prompt.
And then feed that to GPT to get an answer.
So I did that.
In this step here, the system prompt was, you're a helpful document summarization agent.
You take in questions and you and you take in input data, which is the document from the vector database.
And the answer the answer isn't saved here.
So we'll show you that next time.
All right, last but not least is this is a very advanced technique.
It's called fine tuning.
I mentioned at the how, explaining how to make a GPT that one of the steps they took was to take a question answer dataset, and they trained GPT 3, the original model that could do the sequence to sequence prediction.
They checked, they trained that on the question answer dataset.
You can do the same thing at your own company.
So what you would do is you would get questions that are relevant to your company, answers that are relevant to your company.
And train GPT on those questions and answers to make it specific to your company.
So you can give it long term memory by vector databases, and you can also make it very bespoke on your company by doing the fine tuning.
I don't have enough time to go through this as well, but just letting you know, bookmark that in your mind, that's a, it's an additional technique.
That you can use to make this relevant to your business or company.
So just to summarize we talked a little bit about how large language models work.
We talked about four different techniques that you can use to build one of these things if you're looking at deploying the technology.
Context window, which is super important.
You need to know how much data you're manipulating with at any one given time.
A system prompt, this is the thing that makes it imagine what its role is.
Vector databases, this gives it long term memory.
Fine tuning to make the thing very bespoke on the, on, on your company's specific use case.
And that's it guys.
I hope you all got something out of that talk and if you'd like to connect with me, feel free to connect via the QR code that's on the screen.
Cheers guys.
Large language models are the key technology diving the generative AI revolution.
In this session we’ll learn more about how they work, and what they can and can’t do (yet). We’ll touch on fine tuning, training your own models, open source and proprietary models to come away with a sense of the best strategy for specific use cases and organisations.