A (maths-free) Introduction to Generative AI
Introduction
Kaz Grace, head of the Designing with AI Lab at the University of Sydney's Design School, introduces his talk emphasizing the importance of understanding the capabilities and limitations of current AI technologies.
AI and Interactive Systems
Kaz discusses the lab's exploration into the interaction between AI and interactive systems, focusing on real-time, fluid ideation processes alongside AI.
Generative AI: Basics and Evolution
Kaz addresses the concept of generative AI, exploring its origins and how it differs from traditional machine learning, using the example of an ice cream stand to illustrate predictive analytics.
Recent Strides in AI Mimicking Human Capacity
He reflects on the recent advancements in AI that enable it to echo human creativity and output, citing examples from his community involvement in Computational Creativity Research.
Understanding Generative Models
Kaz breaks down the shift from predictive analytics to generative models in AI, focusing on the balance of input and output information and the move from correctness to plausibility in model outputs.
Categories of Generative Algorithms
He discusses different categories of generative algorithms, including autoencoders, generative adversarial models (GANs), diffusion models, and Transformers, explaining their unique functionalities and applications.
Practical Applications and Research Opportunities
In conclusion, Kaz highlights the practical applications of these models, their composition into systems, and extends an invitation for collaboration in the field of generative AI at the Designing with AI Lab.
Thanks, John.
So I'm not supposed to baffle people with maths and engineering.
Okay.
I'm going to need to change my slides a little.
No, thank you, folks for, coming back from the coffee break.
I'm Kaz Grace.
I'm the head of the Designing with AI Lab at the University of Sydney's Design School.
And I think it's particularly important right now that everybody has just a bit of an intuitive grasp of what these technologies, right at this point on the hype cycle, this point on the hype wave, I think it's time for us to try and just get a little bit of an understanding of what these things can and can't do.
Whether you're building something yourself or whether you're trying to decide whether the person selling something to you is as credible as they say, it can be useful to have a grasp of how these things work a little.
So I thought I'd take you all back to school.
So the exam will be this afternoon.
It will be about an hour and a half long.
And I'm going to see if I can make these lights flicker, like as viciously as possible.
And I'm definitely taking the water away… Okay, sorry.
First I'd like to acknowledge that some of the work that I'm going to be showing today as Whoop, yep, cool, as well as the, as the work that I'm going to show today, as well as all of the students and everyone who's come to put this all together, are conducted on the lands of the Gadigal people who's unceded country we're meeting on today.
So in the spirit of that sort of 700 centuries of gathering and sharing and learning, we'll conduct ourselves, in that tradition.
And I've got my slides back.
We're getting through the acknowledgement of country, which I thought was pretty okay there.
At the Designing with AI Lab, we explore the interaction between AI and interactive systems.
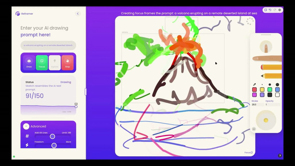
So here's the thing that we've, built over the last little while.
We're exploring how someone can draw, can ideate in a sort of shared sketching way with an AI.
And what's really nice about this is that it's very real time, very fluid, and because you're working with vectors, with line drawings, you can pick up and move around anything that you're, doing.
Oh, the little jangly product music is coming out of my laptop.
Please ignore that.
We don't need that for now.
So the key difference here, as opposed to the very cool stuff that you might see in Midjourney, etc.
Is that this is about working with AI, rather than AI working for you.
Which we think is a sort of undersold segment of how this stuff might work in the future, I'm not going to talk too much about the, work that we do.
I just wanted to put this up here to establish my place in this ecosystem as someone who makes and plays with these tools and has a, team of folks who are both in the productizer, in the, research space and the, tool maker, vein as Andrew was talking about earlier.
What I really want to talk about is how can we, as folks who aren't mathematicians, understand what's going on here?
Understand what does it mean for a system like this when you draw a box and you say volcano?
What is, how does it actually draw something that looks a little bit like a volcano?
What is actually going on under the hood?
I won't be going through the, mathematics of, or any of that, as I said earlier, but I really want to tackle this question on what is generative AI?
Where did it come from and how does it differ from the stuff that we thought we understood in the space of machine learning until now?
Because machine learning until a couple of years ago was pretty much understandable.
I run an ice cream stand.
I want to know, from a data driven perspective, when should I roster on a second server?
I've got a pretty solid intuition that has something to do with the temperature of the day, and I know that when I sell more than about 500 bucks worth of ice cream a day, that's when I can profitably put on a second server.
I've got a whole bunch of data points, I can draw a line through them, say yeah, no, it looks like there's a bit of a relationship here.
So I go approach a predictive analytics consulting firm who charged me 1.
7 million dollars to do something like this and, fit a decision making curve-you think I'm joking-you fit a decision making curve, to the data that I have and say that, look, If it's less than 18 degrees, you should never bother putting on that second server.
If it's more than 24, 25, you should always put on that second server.
And the truth is, in between that, it's going to be a bit pick and miss.
You need to decide on your risk profile.
You need to decide whether you'd prefer to favor customer service and not have people hanging around waiting for ice cream, or whether you'd prefer to favor slashing and make sure that you're never overpaying for stuff.
This is what we understand as predictive analytics.
This is what we understand as machine learning.
Okay, so the data is probably a bit more complicated and the consultants are probably a bit more expensive.
I probably low balled that.
But what happened?
Because now we're at this.
Hey, can you design me an ice cream flavor, that's got a machine learning theme?
Oh yeah, sure, says ChatGPT.
Neural crunch.
Now the truth is.
I did a research project for a couple of years on food and surprising recipes and data and I'm also a bit of a cook so I can tell you this is a really garbage ice cream recipe.
It's got too much stuff going on.
There's, crunchy binary bits which are chocolate, there's almonds, sorry, algorithm almonds, there's caramel sauce that somehow represents data, and there's raspberry ribbons, and, sprinkles.
That's too many things.
It's like a 12 year old at a Sizzler dessert bar.
You just put all the stuff in it.
But this is technically extremely impressive, even if culinarily rather juvenile.
How did we get there?
What happened?
the truth is that this stuff didn't come out of nowhere.
AI has been getting better at making stuff for a while now.
I'm, involved in a community called the, Computational Creativity Research Community, who's really interested in how can AI autonomous systems be used in the generation of stuff.
And we've been tackling these problems for, I'd say, 18, 15, 18 years now, in a serious way as a group of researchers around the globe, initially based mostly out of the EU, but we've gotten a bit everywhere.
And the president of the Association for Computational Creativity said at the conference a couple of years ago, oh sorry, a couple of weeks ago, Look, really the only thing that's changed is now it works.
Which I think is a nice perspective on that.
It's good to have been in this space for a while and I hope I can impart some of that knowledge on to you.
But yeah, we really have in the last year or two made great strides when it comes to echoing or mimicking human capacity.
How did that happen?
So actually the point where I thought Or we might be onto something here.
It was about 10 years ago.
This is handwriting recognition work from 2013 from the PhD thesis of an absolute genius fellow by the name of Alex Graves.
And this was about taking some text and turning it into handwriting.
And this thing, 10 years ago, could not only generate handwriting in a variety of styles, could not only mimic your style, given a bit of your handwriting, but it could also clean up your handwriting while still presenting it in a recognizable style.
So these top lines here, they're a human sample.
Then underneath that is the network, not just imitating that style, but imitating a neatened up version of that style.
So this is AI augmentation at a human level.
From 10 years ago, in a very specific domain, right?
Maybe neat handwriting, I have terrible handwriting, so I'd like to say this, maybe neat handwriting isn't as much of a driver of your value in society as it perhaps used to be.
But this was the point where I looked at this and thought, yeah.
Something's coming, right?
This is going to get different.
It took 10 or so years for the world to reach that, for the tech to reach the point where it wasn't just working at strokes, chicken scratching on a canvas, but can work across a whole variety of domains at human or near human performance.
But what happened?
How did the technology go from labeling stuff To making entire things just from the label.
Isn't that kind of the opposite?
And so this is the bit where I get to be a little bit lectury, and we're going to talk about the etymology of some words.
Just for a hot second, I promise.
It turns out that the word analysis comes from the Greek ana, as in up, and lysis, as in loosen.
Literally, it's a cognate word there.
So it means to loosen up, or more specifically, to untangle, to pull apart.
That's what an analysis process is.
We can contrast that with synthesis, synced together, tithenae or thesis, to place.
So synthesis is putting stuff together.
Those are opposites.
This, by the way, explains why it's really hard to get engineers, or scientists and designers to talk the same language sometimes.
The fundamental way that they approach the world is not just different, but opposed.
Are you trying to take things apart or put things together?
And at the end of the day, that has huge psychological implications for how we approach problems.
But yeah, how did the same tech get from doing the top one, taking stuff apart, to putting stuff together?
I like to think that we can understand that without a slide full of integrals, with so many big squiggly S's it looks like I'm showing you a 15th century manuscript.
I think we can get to an understanding of how this stuff goes, without going to the level of the mathematics.
If you'd love to go to the level of the math, come find me afterwards, I could chew your ear off, but perhaps let's not.
To understand what's changed, let's think about this from a system's perspective as a black box, the model, the machine learning model, the thing that's learned from data, with inputs and output.
So we can say that what predictive analytics looks like is something along the lines of, you have a bunch of documents, those are your inputs, and for each document you want to say news or not.
Now that got a little bit of a complicated use case in the last, year or so, largely because of, bad actors trying to, impersonate this.
But let's say we're trying to compare things like this article on caged eggs from The Guardian, with this recipe for buttermilk pancakes.
You'd hope that a system could say, this one ain't news.
Unless there's something particularly newsworthy, in that.
But this one is not news, whereas that first one is.
We all understand this is a predictive problem.
This is an analysis problem.
We're classifying things.
That falls into bucket A, that falls into bucket B, and we could say what all the buckets were before we started.
Then, what about this kind of problem?
Can you come up with the title for a document?
So here we have, a recipe.
Let's say we're just working with recipes for a second and, okay.
Can you say that the title for this is buttermilk pancakes ? Here, most of the information that you need is still in the input, right?
Like it's pretty straightforward if, if you have a big database of recipes, you can probably figure out the patterns in how and what they're called.
All of the information that you need is there.
It becomes a little bit more, challenging if you're looking to label news articles.
Because news articles often have a little bit of rhetorical flourish in the title.
This is a particularly long title.
I like that 'in a flap', gotta get your bird joke in there somewhere.
But even given that, with a little bit of an understanding of news article titles, with a little bit of domain knowledge that's not present in the document, that has to come from somewhere else, you could probably give titles to articles without too much trouble.
Most of the information is present.
So what if we go to a slightly more complicated problem, where you have most of the document, so this is that article on phasing out caged eggs again, you have most of the document and you're asked to produce just the last sentence or two.
Now, you have to know a little bit more about the domain, you have to have a little bit more information on hand, a little bit more expertise, but still most of the information that you need is still there in the input.
In this case, again, we're looking at a bit of rhetorical flourish.
That last sentence says, 13 years is gonna be about the time that it'll take to phase, this stuff out.
I think they're talking about a 2036 deadline for phasing out, battery eggs.
Or, about 9 lifetimes for the average caged chicken.
So there is a strong rhetorical, emotive, affective point being made with that last sentence.
Which is quite a bit more complicated than just, summarizing everything that came before, which is what ChatGPT tends to do when you give it a long writing task.
The last paragraph is just all of the things that it's said already.
So this is a bit complicated, especially to do well, but still most of the information is present in the input.
So what if we go to a much more complicated thing, and now we're basically at ChatGPT, can you do the opposite?
Can you go from title in to document out?
Now you have to add a lot of information.
Now you have to provide a lot of context.
Invent.
Hallucinate a lot of context.
Because all you have is the focus of the, of the article, you don't have the content.
So if we look at these things as a spectrum, from pure classification, through adding a bit, to adding a lot, to making the whole thing up, it's no longer just opposites.
Am I analyzing, or am I synthesizing?
We can think about this instead, as how much information is in the input versus the output.
What is the ratio of stuff that's there in front of me versus stuff I have to bring to the table.
We're anthropomorphizing the model here for a bit.
So there's really only two things going on here.
The change between the old way, the classification way, and the new way, the generative way.
The first one is that you do have to give up the notion of getting the answer perfect.
It's easy when you're doing, ah, is this a yes or a no, or even are you going to guess a number, are you going to guess the price, are you going to guess the temperature.
It's easy to say, yeah, you're right, or no, you're not.
Now we have to have this idea of, are you in the right space?
You're not going to create the same article, given the title, as was in the training data, but you can probably come to something that is plausible.
Maybe something that a reasonable observer would say fits that title.
So we have to change from correctness to plausibility.
But really, the main thing that I want to talk about is that idea of the ratio of information, in the inputs versus the output.
This is not, at least from this lens, an opposite, it's merely a case of how much information has to be in the black box in the middle versus how much information is coming from the input, is coming from the document or whatever you're giving the thing.
And I hope that thinking about it that way makes it a bit easier to target this idea of how is it making stuff.
The box just has to be bigger.
So generative models are still just, although it is technically amazing, just predicting a plausible answer to a question that you've posed them through training.
The only thing that changed is that question requires them to bring a lot more expertise, to use that word loosely, to the table.
So how do you actually predict a whole thing?
How does a model actually learn to do that?
This is the bit where, if you get to this point, okay, you understand the structure of how these models work, what's in, what's out, this is the bit where you usually hit a wall of integrals.
You end up, you go around, you look at blog posts, someone says, it's super easy to get started with this thing, look, you just do this, here's the cost function, and you go I need to hire a mathematician, and that's very hard.
They're quite expensive, and they're really hard to find, and a lot of organizations do not have the ability to understand whether the person sitting in front of them is credible in that field, because I don't think a lot of us have had to hire mathematicians in the past.
So let's see if we can do it without the integral signs I want to go through, I want to go through a couple of categories of these sorts of algorithms, starting fairly arbitrarily at autoencoders, because I could go all the way back to the thing that was doing the handwriting or way back before that to generative, models, et cetera, from the history of AI, but we've got to start somewhere.
And this one I think is easy to understand.
So autoencoders, what I would call variational autocoders, at least, are the first major kind of generative model that started producing things that we go, oh, hang on, that looks pretty good.
These are all small images, but this works by training the model to reproduce something.
So the input is the same as the output.
How does that work?
That seems rather silly, right?
Like, why would you want a model to It's not just a copy paste function.
It works by making the box in the middle restricted in some way.
So it can't just copy all of the training data.
It has to learn patterns in order to reproduce it.
So here we have picture of a cat in, picture of a cat out.
Now, it is possible to not exactly reproduce the input, but you can give it like categories or labels or even prompts or something as well, but let's leave that for now and just focus on reproducing the input.
And the reason why this is valuable is that if you're using at least a variational autoencoder, and I won't go into what the difference is, you can then throw away the input bit and then just ask it to generate more images.
In this case, I guess cats.
Just ask it to generate more stuff, run the model randomly to reproduce something plausible, rather than to reproduce a specific image.
And in doing that, you've given yourself a generative model.
So it's trained to reproduce.
But then you can just ask it to hallucinate.
This is a little tougher to control with prompts, etc.
But it's able to make human level or human looking stuff.
We can then move on to one you've probably heard of over the last couple of years of GANs, generative adversarial models.
And they can produce things with a lot more sort of large scale images with lots of interesting structure in them.
It's easy to produce just a small image of a face.
It's quite a lot more complicated to produce a large landscape.
The way these work is really quite similar to the autoencoder, except they have two models.
The best way to think about this is an arms race between a forger and a detective.
I guess one of those art detectives?
I am from the art cops.
I don't know how that actually works, don't look into the metaphor too much.
But, imagine you have one model that is now generating our images.
Except in this case, instead of, reproducing a specific image, it's actually starting from random noise.
And making images from that, how though does it know how to do that well?
that's where the second model comes in.
And this is a model called the discriminator, that's the cop, that is determined to not be fooled.
Are you a fake cat?
Or are you a real cat?
So it is trained on contrasting images of real cats to the things that have come out of our generator.
And its job is to say, You're trying to pull a fast one, buddy.
That's a fake cat.
So how this works over time is that at first the discriminator is incredibly bad, but it's okay because the forger is incredibly bad too, and they get better together.
Stabilizing this kind of training is mathematically a nightmare, and the GANs used to do this thing where they just make the same cat over and over really well.
But, they got better.
And eventually they are able to produce things like that, large landscape.
This was the dominant space, in at least vision models for quite a while.
What we've moved on from, to from there, is diffusion models.
You might have heard about things like stable diffusion, which implies of course that previous versions of diffusion weren't all that stable, which, yeah, that was a whole problem.
Still a bit of a problem.
Ask, me about how in the coffee break about how we managed to end up with elephants with three, four trunks, just by, messing around with things.
So the trick here was that instead of going from noise to image, they did it step by step.
So you'd actually go from noise to something that is mostly noise but has a bit of cat ish ness to it.
And then you'd do that over and over again.
So you'd have, over time it would produce a better image.
So diffusion then just, because you could throw more CPU, cycles at it, you'd tell it a, prompt and you'd also tell it where in the process you were, like which step you were.
It produces much better images than the GANs did.
Now I won't spend too much time on LLMs, because I know Paul's going to cover that in much more detail.
But the key difference in working in a text domain to working in images has to do with how the data is structured.
Images have spatial structure.
But it doesn't really matter that much what order you look in things.
Text has order.
It has temporal structure.
And as a result, we really need to focus on that.
Transformers work by modeling attention.
They're a bit more sophisticated than us.
We can really only pay attention to one thing.
At least I can.
Transformers can pay attention to multiple things at multiple times.
If that's a bit confusing, let me give you a specific example, pretend you're translating, in this case, English to French.
I'm going to have to try and pronounce French here in a second, so apologies to any French speakers in the room.
Let's say you're trying to translate the United States of America into, l'Etats Unis d'Amérique.
That was garbage.
Maybe it was okay.
The trouble there, of course, is that it's easy to get started.
The first word translates nice and easy.
Then things go a bit south.
If you're just looking at one word and trying to translate the next one, it turns out different languages order things in different ways.
Any German speakers in the room know that you guys like to pile all of the verbs up at the end of the sentence just to make it really hard to figuring out what's going on.
So this presents a problem for a one word at a time translator.
Now imagine you're trying to generate a whole recipe or a whole document or a whole interaction with a customer.
Where you pay attention to and what you do next really matters based on specific combinations of what came before.
And that's the magic of Transformers.
So that's how you can go from, write me a thousand word essay on the different kinds of, generative AI to a specific piece of content.
And incidentally, that's why things like ChatGPT love putting in titles and headings and list bullets and stuff like that, because they act as signposts for their own generation.
It does better when given that kind of structure.
To wrap up a little bit here In practice, these sorts of models that I've talked about are composed into pipelines and systems and it's usually a lot more complicated than just chuck a GAN at the problem or whatever.
But I hope I've explained a little bit how these things can be such amazing mimics.
How it is that they can produce what seems like human level stuff just using prediction.
So I'll wrap by saying, at the Designing with AI Lab, we're always looking to partner with folks.
If you do, generative AI anywhere in the design or creativity or associated with media, et cetera, then we would love to hear from you because we're trying to put together a group of partners who are looking at actually research problems that exist in this space, so reach out to me or grab the code for that thing I showed earlier on if you're, keen to do that.
It's all open source and otherwise I'd love to chat to you over the rest of the day.
Kazjon Grace will take us through the landscape of modern AI technology.
From Large Langage Models and how they enable machines to understand and generate human-like text, to Diffusion Models which provide a powerful framework for modeling uncertainty and generating high-quality samples.
Along the way we’ll touch on Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), all with the goal of equipping non experts with a broad understanding of the technologies of AI today.