LLMs in education
Introduction
Thierry Wendling introduces himself as the head of AI and machine learning at Atomi. He sets the stage for his talk about a case study using language models at Atomi and shares insights from this experience.
Atomi's Teaching and Learning Platform
Wendling describes Atomi as a teaching and learning platform that provides text lessons, short videos, and interactive assessments aligned with the curriculum to aid teachers and students.
Interactive Lessons and Assessment Tools
He explains the concept of interactive lessons on Atomi, which blend text and video content with quizzes of varying complexity to enhance student learning and understanding.
Challenges in Assessing Short Answer Questions
Wendling discusses the challenges of automatically marking short answer questions without AI assistance and the initial approach of having students self-assess based on sample answers.
Implementing AI for Auto-Marking
He shares the recent implementation of AI to automate the marking of short answer questions, enhancing the student experience with real-time feedback and the ability to dispute marks.
Natural Language Processing in Assessment
Wendling discusses the application of natural language processing in assessment, framing it as a text or sequence classification task and explaining the model outputs.
Insights into Taking AI to Production
He shares insights on what it takes to bring AI solutions into production, emphasizing the importance of choosing the right tools and models for specific tasks.
Transferring Knowledge from Large to Smaller Models
Wendling describes the process of transferring knowledge from large language models like GPT-3 and GPT-4 to smaller models, achieving high accuracy with lower costs and faster speeds.
Future Steps in Automarking
He outlines future steps for automarking, including expanding subject coverage, providing formative feedback, and personalizing feedback based on student profiles.
Closing Remarks
Thierry Wendling concludes his presentation, expressing openness to questions and further discussion on the topic.
Thanks for the introduction.
Good afternoon, everyone.
So yeah, I'm Thierry, I'm head of AI and machine learning at Atomi.
And yeah, today I'm going to speak about a study case of something we've built at Atomi using language models and some learnings we had about that.
So yeah, so for those who don't know, Atomi is teaching and learning platform so a platform that can be used by students or teachers or schools to take lessons that are aligned with the curriculum.
So yeah, what we do specifically is we generate a lot of content that are curriculum specific in the form of text lessons or short videos and that enables teachers to create engaging lessons quite easily for their students and classes.
In addition, we provide testing tools in the form of interactive assessment for students to test themselves and test their mastery of a topic and subject.
We also use data and analytics to share the progress with students so they can prepare to the exams like HSC and also share insights to the teacher so they can better manage and support their students and classes.
An important type of lesson that we, we have on the platform is what we call interactive lessons.
And essentially we are blending together a mix of text lessons and short engaging videos.
And then as we flow through the lessons, we have quizzes with different question types of different degree of complexity.
So we'll usually start the the learning path with easy questions like multiple choice or drag and drop or fill in the blank or exact answers.
And and as a student start mastering the topic a little bit better we get into like more complex type of questions.
One interesting type of questions that It's quite efficient to, to test out the knowledge of the student on a topic, but also to be able to test out their ability to construct like clear answers with good syntax and everything is what we call short answer type of questions.
So again, we will blend this into interactive lessons with, a text lesson to introduce the topic, maybe some video to illustrate something and then flowing over that type of question.
Typically we will prompt the student with a cognitive verb yeah, explain this or illustrate this or describe or give example of this.
And expect the student to answer with its own natural language, which, again, is quite good to be able to assess their ability to reason and explain something clearly.
And of course, initially, it, we couldn't automatically mark and assess that type of answers without the help of AI.
So what we did initially on the product is ask a student to mark himself or herself based on a sample answer that our content creators will provide in addition to the question.
And yeah, this question type actually has a lot of benefit.
Like it's good for the student to, to, ask them to mark themselves and based on a correct answer and understand why they have it correct or not, but there is some limitation.
The student will obviously not necessarily mark themselves accurately and also they don't get immediate feedback on whether they had a good mark or not.
They don't get any explanation.
So it has some benefit, but it's not the best to promote mastery and really accelerate the learning of the students especially on difficult topics.
So what we've done is we used AI to automate basically the marking of the short answer questions.
And yeah, we enabled that on the platform actually last week.
So this is all very fresh.
And the experience now looks like that, so the student will still answer with its own natural language and now have the ability to check its answer and get like pretty much in real time a mark and still a sample or reference answer, so it has the ability to improve understand why we the mark was like that.
And of course, for a good user experience, we enable we give the student the ability to dispute this mark and tell us what he he or she thinks they had and we can surface that to the teachers as well.
So how did we do that with AI?
Essentially, it's the field of natural language processing.
This is all like text data and essentially we can frame this task as a text or sequence classification task where we use a language model to map some text inputs.
In this case, a question, a student answer, and a reference answer to give as much context to the model as possible.
And then the algorithm, the model will output one of three marks in this case to limit the complexity of the task.
So something like correct, partially correct and incorrect, and it's ultimately a marking label as well.
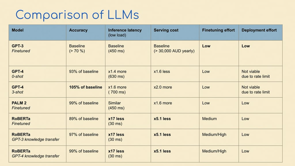
So we did a comparison of language models because there's nowadays there's a lot of large language models that achieve state of the art on many natural language understanding tasks and we compare them in terms of accuracy specifically for this auto marking task.
So we built up a small data set for that, for test, for build development and testing.
And we also compare them in terms of like inference latency, serving cost.
And wanted to add a little bit of insight on our learnings on fine tuning effort and deployment effort.
So essentially the insight I'm hoping to share today is yeah, what it takes to take this to production basically.
And so a first, an option of choice, I think when you start a project like that is and especially if you don't have a lot of machine learning experience and engineering resources, you probably start with going through something like OpenAI GPT 3 because it's nice and easy.
So we did that and yeah, it's pretty much API code, so pretty easy.
We started with zero shot so without leveraging any internal data.
And realized that the accuracy was not that great for this task.
This task is a little bit difficult.
It is a little bit more difficult than a traditional text classification task, where, for example, when you try to classify tweets in terms of their sentiment, here you have questions that can be potentially be open ended.
There's not one, one or correct answer.
There's a spectrum of correct answers.
So you actually need the model to be able to not just do some semantic similarity, but also do some rezoning.
So natural language understanding, and this is where the large language models shine basically.
So GPT3 zero shot was not great.
GPT 3 few shots was much better, but a much more cost efficient way to do this is fine tuning, basically.
It gives better accuracy you reduce the length of the prompt and yeah, it's just more cost efficient in production.
So we got really good accuracy, reasonable latency, sub seconds, so pretty fast.
Cost is not negligible, it was significant and fine tuning and deployment effort are low with, thanks to OpenAI, for example.
Then two weeks ago, GPT 4 was made generally available especially the API access was enabled.
So that was great.
So we included it in the comparison here and we started with zero shot which was surprisingly already really good.
Zero shot GPT 4 was matching the quality of fine tuned GPT 3 to 93%, so quite high.
That's without using any internal data on that task.
So pretty impressive.
Latency was a little bit longer and cost was also significantly higher and same amount of fine tuning effort.
But one thing with GPT 4 is it is extremely rate limited.
So it was for us not a viable production solution, at least not as of today.
The other thing is like currently you can't fine tune GPT 4.
OpenAI says that by the end of the year, we should be able to do that.
Another thing is like with OpenAI, you never know what to expect.
They change their mind every month it's a little bit risky to rely fully on them, to be honest.
Yeah, GPT 4, not able to fine tune.
So we tried a few shots and that was by far the state of the art on this task for us.
The quality was really above everything, especially on question, on like mathematics questions and things like that, where there's a little bit of reasoning to be done to be able to grade a student answer, basically.
Less latency was much higher, cost was much higher, two times the price, if quality is that good, maybe it doesn't matter to your use case.
But in any case, it's not a viable production solution for us because of the rate limit.
We also compared the GPT equivalent at Google, which is Palm2, which is available on Google Cloud Platform through the Vertex AI API.
And that was very similar to GPT 3.
We were able to very easily through the interface, do some fine tuning and assess.
And yeah, that was very similar to GPT 3, but the serving cost is much higher because you have to host this really big model yourself in your account, in your GCP account.
Pretty big compute instance like GPU instances and that's not negligible.
Finally, we tried something with open source.
We got some models from the famous open source hub Hugging Face.
And we tried smaller models like you might have heard of transformers like BERT or RoBERTa or DeBERTa.
So essentially language models, but much smaller and yeah, all open source and you ability to fine tune and deploy very easily as well.
A small model like RoBERTa was, by doing some fine tuning, we were able to match the quality of GPT 3 by 89, 90%, which is pretty good, pretty good starting point, but for us it was not it was not enough.
The benefit though is that the speed was like 17 times faster, okay?
So if you have high traffic in production, if you have high concurrency and if you have like performance SLAs, that is not negligible and obviously serving cost was like five times lower as well.
Again, if you have some strict production requirements, this is definitely an appealing option.
Fine tuning takes a little bit more effort because it's less managed.
You have to play with some parameters yourself.
And deployment is actually not hard thanks to things like Hugging Face, Inference Endpoint.
So in a few clicks you can deploy a model to an API.
All in a pretty decent compute instance as well.
Then we found a paper from Microsoft where they were transferring the knowledge from a large language model to a smaller one.
And we were like, Oh, that sounds interesting.
We're going to test this out.
And because we have a little bit of machine learning and data science expertise in house, we're able to test that quite quickly.
And that was quite surprising.
We first transferred from GPT 3 to RoBERTa.
And got a quality which was up to 97 percent of the fine tuned GPT 3 quality.
Speed and cost are remaining the same.
Way faster, way cheaper.
Fine tuning effort is slightly higher, but still reasonable if you found this paper from Microsoft.
But once you have it, it's like not that hard.
And finally I think yesterday my data scientist shared this result with us.
Like he tried to transfer the knowledge from GPT 4 to RoBERTa and he got really good results like matching 99 percent of the accuracy from fine tuned GPT 3.
So GPT 4 is a good teacher to smaller models, basically.
And yeah, it can be leveraged for doing a lot of annotation and labeling.
And getting a reasonably fast and cheap solution in production.
Yeah, so that's it.
Briefly, this is the paper from Microsoft that we used on the way they frame it is like reducing labeling costs using large language models.
They mentioned GPT 3, but really it could be anything.
GPT 4, PALM 2, llama 2 is out now.
So you could test out anything and yeah, the motivation is like getting something in production, which is cheaper, easier to maintain, easier to debug and et cetera.
They mentioned different labeling strategies and the one that was really performing really well for us was mixing, doing some labeling with the large language model.
And also relabeling some cases for which the GPT 3 was not confident for with a group of human experts, basically, which is called active labeling.
So that worked extremely well for us, very well.
So again, you would label some data with a large language model.
You would extract the cases where confidence is not high.
You relabel them with your experts.
It is not much.
It's in our case, it was a few hundred examples, and then we had a high quality dataset, and we were able to deploy a smaller, much smaller model with really high quality quite easily.
So that's it for this use case.
So what's the next step for us in terms of automarking?
So currently we are only covering English, physical education, math, and science.
Our objective is to be able to cover all subjects.
Of all curriculums across all different years.
And the next step is also, we are actually actively working on this already, but being able to not just instantly give a mark to the student, but explain why, basically.
So formative feedback is really important for us and for the students and teachers.
And we are actively working on this, so yeah.
Getting to a point where I say, hey, you, your answer is partly correct.
Here is a sample answer, but this is precisely why you're partly correct.
You're missing this and that, or your answer is accurate, but syntax is not great, or just not a very clear answer.
Really good feedback for the student to, improve iteratively.
The final step is personalizing this, the feedback even more based on the student profiles, its recent activities and strengths and weaknesses and where they are in terms of preparing exams like HSC, basically.
So that's it for today.
Thanks a lot for listening.
We'd love to take any questions and thank you.
What lessons did Atomi learn in adopting natral langiage processing and large lamgage models in their learning platform? Atomi co-founder Thierry Wendling shares valuable lessons and insights from their journey, including considerations for model adoption.