A prompt engineering deep dive

Introduction to Prompting in AI
Tanya Dixit begins her presentation by discussing the significance of prompting in AI, particularly in the context of call center analytics, and stresses that there is no one-size-fits-all approach to prompting.
Call Center Analytics Use Case
Dixit introduces a use case involving call center analytics, covering aspects like call summarization, sentiment analysis, compliance detection, and opinion mining.
AI and Transcript Analysis
She explains how even imperfect transcriptions can be valuable for AI analysis, demonstrating the robustness of language models in extracting semantics and facilitating use cases.
Approaches to Prompt Engineering
Dixit discusses two approaches to prompt engineering: the direct prompt approach and the embedding-based approach, explaining their suitability for different NLP tasks.
Design Patterns in AI Implementation
She highlights various design patterns in AI implementation, including the use of multiple LLM calls and the importance of prompt design in achieving accurate outcomes.
Choosing the Right LLM
Dixit addresses the process of selecting the most appropriate large language model (LLM) for specific tasks, considering factors like cost, token count, and cloud platform compatibility.
Effective Prompt Engineering
She delves into the intricacies of prompt engineering, emphasizing the significance of instructions, context, and output structure in creating effective prompts for LLMs.
Tweaking Prompts for Optimal Results
Dixit demonstrates how tweaking prompts can significantly impact the quality and relevance of AI-generated summaries, underscoring the iterative nature of prompt engineering.
Ask Your Data: Enhancing Data Interaction
She introduces the 'Ask Your Data' use case, illustrating how companies can interact with large datasets using natural language, facilitated by AI technologies.
Advanced Prompting Strategies
Dixit explores advanced prompting strategies like chain of thought prompting, which involve breaking down complex problems into smaller, manageable sub-problems.
Conclusion and Prompt Evaluation
In her closing remarks, Dixit advises on evaluating prompts based on criteria like output validity, stability, and safety, and introduces her company, Crayon, which specializes in NLP.
Yeah.
Hey everyone.
So thanks John for the introduction.
Yeah, so today we're going to talk about prompting, but before we do that, I just want to set a little bit of context using a use case, which is a call center analytics use case.
The reason for that is, prompting in itself, like there's no golden prompt.
It really depends on the LLM, the version of the LLM you're using, and, specifically the problem that you're trying to solve.
So we'll set some context, we'll go over a general NLP tasks, have like a mental model of that, and then deep dive into prompt engineering.
So let me introduce the use case.
As you all know, call center analytics, it's an important use case for, a lot of companies.
And, some of the things that they want to look at is call summarization.
So summarizing the transcript of a call in order to provide, capture the main points, the outcomes of the call, making it easier to review calls without actually listening- someone have to listen to it, to the entire call.
Then sentiment analysis, understanding the tone of the text and identifying the intent as well.
Compliance detection, which can detect whether or not sales agents are complying with specific guidance, using appropriate language, following protocols, et cetera.
And using, the transcript, you could also, detect or understand the probability of the sale and, of the sale, basically, as well as opinion mining, which is like sentiment analysis, but much deeper, like opinions about your product, your service, your company itself.
So these are the use cases that we've come up in our interactions with clients.
So the example.
Let me present you the transcript.
So this transcript is actually something that we, like it's engineered, it's not the actual transcript.
And as you can see that there are some words that have been changed.
Colliding, and you can see, some details are changed.
This is to actually represent that even if you have a transcription that is not accurate, you can still do a lot with LLMs.
And, recently we've also been working with a use case where, it's a different language, so the transcription is not that good.
But using the LLMs, you can still understand that the, you can get the semantics out of it pretty well and then go forward with your use case.
So yeah, there, there is summarization, there's sentiment analysis and there is the offering detection or basically like compliance detection, all these classification use cases.
Looking at that, we can identify like different sets of NLP tasks or problems here.
One is unsupervised sequence to sequence tasks, which is summarization, translation.
Then the other one is future classification tasks with explanation, which is sentiment analysis and opinion mining.
Unsupervised tasks like, anomaly detection, which clustering enables as well.
Supervised classification tasks, like compliance detection.
Mapping that onto the LLMs, so there are multiple approaches that we can take.
I'll talk about two approaches, direct prompt approach and embedded based approach.
Yeah.
So let's talk about the direct prompt approach.
So the direct prompt approach is most suitable for the, these two tasks.
The first two tasks here, unsupervised sequence to sequence tasks and few zero or few short classification tasks.
The design process that we generally take is, this is, so this is from Microsoft, actually.
How would you go about, actually starting to develop a prompt, right?
You would probably first try out a few prompts with a smaller set of your data, right?
The prompt flow would be developed, on the basis of a small set of your data, and you would try out a few prompts, debug, run, evaluate, and then if you're happy with that, you go to a bigger set of data, right?
And you would evaluate that against the metrics that you've identified.
Some of the metrics are quality, relevance, safety, etc.
And then if you're happy, then you productionize the solution, right?
And even before you do all that, you also identify an LLM, which I'll talk about in the following slides.
Now, it's prompting is, it's not like just about one LLM call.
Maybe what you're doing is you're using, you're making multiple LLM calls, right?
Let's say you didn't get the right output from one call, you can actually use LLMs to post process that as well, and then get it in a format that's executable directly, right?
And sometimes that might mean that the first call is made to a smaller, weaker LLM and the second one is to a, to one that, that's better at reasoning or maybe, generating something that, that is exact or that is a better output, basically.
So these are the kind of design patterns, there.
The other approach is an embedding based approach, which is mostly for yeah, that's, so that's for unsupervised tasks.
So the tasks that we discussed here, and supervised classification tasks.
What that allows us to do is, so I, think we already discussed that, like using chat GPT or GPT 4 to create data.
Use that as training data set for your smaller models, right?
So you could actually, that's a really interesting way to cut your costs and to, yeah, basically a good way to cut your costs and run it, lower the latency of your calls as well.
So this approach, in this you generally would transform your text into a vector.
So you would capture it as embeddings, which would capture the semantic nuances of that.
Embeddings reflect relations between text in a multidimensional space.
And, for example, something that says global warming is causing climate change and climate change is a result of increased global temperatures.
We can understand this is, related.
And embeddings do capture that.
And if you find out vector similarity using that, you can actually see that these would be pretty similar vectors.
So once you have these embeddings, you can actually use traditional techniques like, support vector machines, random forest, for tasks such as, supervised tasks such as classification.
In a recent use case, we've actually come up with a hybrid approach.
We're doing clustering along with a few LLM calls too.
So we're doing clustering to identify similar texts and then doing LLM calls to identify, what's the topic in that text.
These kind of, approaches reduce the cost of your solution as well as the latency.
Now, before moving on to prompts, I want to discuss a little bit on LLMs.
Like, how do you identify the LLMs that you're going to be using for your use case?
Because there are a lot of them, and your prompts would depend on the LLM, and not just on the, large language model, but also on the version of that.
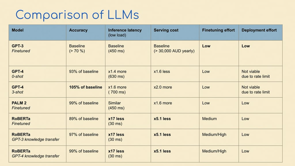
A few comparisons here.
There's GPT 3.5 Turbo, DaVinci, the embeddings model from OpenAI, the Ada model.
Falcon, J2Ultra, J2Summarize.
The, cost of these, they keep changing.
And a lot of people have already touched on the cost, so I'm not going to touch on that.
In terms of number of tokens, it's, number of tokens are really important, not just to understand, what you can do with it, but also, we have noticed that once you go beyond a certain context length the quality of the output reduces a little bit.
In order to, if you want, let's say, to get, exact output, like that's, the output is something that you need to get exact and you need it to be repeatable, it's always good to break up your text into like smaller chunks and then send it.
Even if it's a powerful model, even if it can handle more context, the quality might drop actually.
Then number of parameters is a consideration.
Generally we've seen higher number of parameters means a more powerful model.
Sometimes that's true, sometimes that's not true, because of the way that the model has been trained and your specific use case, again.
And the cloud that it runs on is also a consideration for us because, we have clients on Azure, some on AWS, and, GCP, so it just depends on where the, where you can get access to it as well, unless you're hosting it yourself.
And being open source or not is a good thing to think about because, because of the changes in the API, like if, you want complete control of the model, then you would want to go for an open source model.
Okay, moving on.
Okay, now let's come to prompt engineering.
So what does a prompt exactly do?
So we've all, we all know about, attention mechanisms and how that works.
But a prompt doesn't necessarily work in the exact same way because there are multiple things that are happening when you're working with an instruction tuned LLM.
On an intuitive level, it serves as a query, along with some context to an LLM.
When you send a prompt, you would have an instruction, and then you would have some context, and you'd have space to give it output.
So that's what a prompt is, right?
A prompt works best on an instruction tuned LLM.
Because of the way that it's, it has been tuned to accept input in a certain format.
And that's what you're giving it.
And again, like the prompt that you create depends highly on the LLM and how it has been trained.
Yeah, let's come back to the use case.
I've already introduced this.
Just to have another look before we go to example prompts.
Again, this is a transcript and we're going to go, we're going to look at summarization and a few prompts that I've I tried, with DaVinci, 003 and, GPT3.5 Turbo to summarize this .
So the first, iteration, it's on DaVinci 003.The temperature is one.
So okay, so one thing is that we know the prompt matters, the LLM matters.
Now these parameters also matter.
Parameters like, parameters like, this temperature.
Temperature is, is something that's really important and you'll know why.
So let's, just focus on that for now.
So the prompt is simple.
Summarize the text, colon.
And then, the transcription is supplied along with it, right?
The first completion, the first time I run it, this is the output that I get.
This text is about a customer discussing a discrepancy in their latest bill, blah, blah, it goes on, and, look, and when I run it the next time, you can see the output has changed.
It changes, a little bit, initially it's talking about a 20 percent discount for a year, and then the next time it doesn't, it talks about the same things, but in a different way, right?
Why is that?
One of the reasons is that the temperature is one.
When you give, so temperature, decides the creativity of your output.
If it's zero, your output would be, like, pretty stable.
You can get, the same output running again and again.
If it's one, you'll probably get different outputs.
That's one parameter.
Again, we make temperature zero and run it again, and you can see that it's the same text, the same output.
If you're looking for a really stable output, dependable output, just make sure your temperature is zero.
Okay, so this was DaVinci 3.
Now let's run it on GPT 3.
5 Turbo.
Yeah, so the one, DaVinci 003 is like pretty powerful.
It's 175 billion parameter model, and has been trained on a huge amount of text.
As well as, GPT3.5 Turbo is smaller, and it has also been trained, but it's been trained a bit differently.
And like it's, for suited for smaller tasks like chat based tasks, whereas DaVinci can do a lot more.
So if you look at the completion, it actually starts with you too.
So it's trying to complete the, conversation and then it starts to summarize.
The prompt is the same.
The thing that has changed is the model, the LLM, and you can see the, transcription, sorry, the summarization has changed as well.
And if you, Okay, let me, so if you go here, you can see that the customer, it ends there, right?
Why is that happening?
Because look at this max length tokens 100.
That's the max length of the output and the model is stopping after it has produced 100 tokens and at this point it's a bit of an issue because it doesn't really finish.
So we have to engineer the prompt now.
Change the prompt a little bit so that it finishes within the 100 tokens and still gives us an output that we can directly use because we don't want to post process this output, when we're using a production level use case.
We don't want to come up against issues like this.
As well as, I, want to get rid of this, 'you too' as well, because that's not part of the summary.
I make the temperature zero, make sure my output is stable, yeah, I'm happy with that, it is stable.
Because I get the same output twice, I run it twice and it's the same, but still the same issue.
The customer agrees to the new electricity.
And nothing.
Because max tokens, 100.
Okay.
So maybe I change the max tokens.
I make it 200.
How does that, change my output?
It makes it actually a bit worse.
It starts just asking questions, replying on its own, and, the prompt is the same.
It's not summarizing it.
It's making it worse.
What do I do?
I need to tweak my prompt.
Let's look at the prompt now.
I say that this is my instruction.
"Summarize the following transcription in one paragraph.
Input text, transcription.
One paragraph summary, colon." You know these, even these colons make a lot of difference.
I've tried, like I spent two hours trying to get the summary in one of the use cases and I didn't put the colon and it wasn't right and once I put the colon it worked.
Like these things make a lot of difference.
And as you can see, I also changed the stop sequences, but it doesn't matter here, it doesn't encounter the stop sequence yet.
So stop sequence basically means that stop generating when you encounter this sequence.
So when you encounter line break, stop generating.
But, as you can see now, the output is stable because I ran it twice, same output.
And I'm getting an actual summary and I'm not, generating text that I don't need.
Yeah, what are the learnings from this?
Basically making the prompt really, clear that this is my instruction, this is the text you're inputting, now give me this output, one paragraph summary.
And iterating as we saw that we had to do a lot of iterations, not just with the prompt, but, also, these parameters of an LLM that differ from models to models, but they generally stay the same, like you have temperature mostly, max length, these top, probabilities, like all these parameters generally stay the same from model to model.
Okay, just to summarize, we, did initial testing with the DaVinci model, it is more advanced, and DaVinci is more costly as well, it's ten times costlier than, GPT 3.5 Turbo, and we got a, gave a simple instruction, we got concise summaries without much prompt engineering, but when we did it with GPT 3.5 Turbo, we had to engineer our prompt a little bit, had to alter the prompt structure as well, and adding, basically, we achieved a stable output after doing that.
So as you can see, it's the, and, we also, we didn't look at the quality of the output, but, it's similar quality summary that we're getting from both models.
It's just the level of effort changed a little bit.
Okay.
Now, let's look at another use case.
Ask Your Data is a, use case that a lot of companies have been working with, so they have huge data sets, and they have PDFs, PowerPoints, or documents across the company, and they want to do a lot with it, and, so this use case, what, it means is you have a lot of data sources in your files, in your databases, and you can interact with them with natural language instead of having to query it using SQL or other techniques.
So, this one is from Microsoft, so it's on Azure Cognitive Search, you put a query, the query would search your knowledge base and then return the knowledge back to the LLM.
You'd have a prompt there and you would get a response from the LLM.
Now why am I introducing this?
Based on this use case, we would look at two prompt engineering design patterns that you can use for your use cases as well.
So the first one is direct or few shot prompting.
So direct prompting, we just did direct prompting.
The one that we were doing with summarization, that was direct prompting.
Let's look at few shot prompting using this.
So the, the, pattern that we're doing right now is retrieve, then read.
So what it does is user has a query.
The query goes to Cognitive Search.
It, based on that query, retrieves a set of documents and then sends those to the LLM.
The large language model, takes in the query of the user as well as the return documents and then returns a response.
So that's the workflow.
In order to do that, the, let's look at the code.
Let me just, that.
So yeah, let's look at the prompt that they're using for that.
For the LLM to enable that.
Yeah, okay.
The prompt is, "you are an intelligent assistant helping X, or whatever company's employees with their healthcare plan questions", and it gives a set of instructions, and then it says, each source has a name followed by colon and the actual information.
And it's asking to return the information from the documents that have been retrieved, right?
And, as you can see, it actually gives a sample conversation.
Question, what is the deductible for the employee plan for a visit in, Bellevue?
And sources, it gives a set of sources and answers.
So this is, me, or like the, you, the engineer, giving an example of the, input that the LLM is going to get, and, returning also an answer.
So this is an example of a few shot prompting.
So you give an example to the LLM, this is how you're supposed to give the out, this is how you'll receive the input, and this is how you're supposed to give the output.
And, it's basically showing it, okay, try, this is how I want you to work.
It's, like an example of that.
Okay.
So that's one paradigm.
Let's look at the second one, which is chain of thought prompting.
Chain of thought prompting is, it's basically more, it's a bit more complex.
So in, in that paradigm, what we ask is, we give a prompt that is a chain of, instructions and it's, not just instructions, it's, reasoning.
And then sometimes it's actions, like that's a different paradigm, but it's a chain of, yeah, it's a chain of thought.
I don't know.
Yeah.
Let's look at an example to, look at that.
Basically, it's breaking down a big problem into smaller sub problems and then, working with that.
Yeah.
Again, ask your data use case.
Let's do, let's break it down into small problems.
The user has a query.
Now, the query directly goes to the LLM, not to Cognitive Search, like it was in the last example, the LLM reads the query, understands it, and then decomposes it into subqueries.
The subqueries each get their own answer from Cognitive Search and they give that back to the LLM and then it recomposes all the answers and gives the answer back to the user.
Let's look at the example prompt here.
And it's all on GitHub.
I can show you the links.
So the example is, again, it's, it.
It is, the prompt is also an example, so it's a few shot prompt as well.
So question, what is the elevation range for an area that the eastern sector of the Colorado Oregonee extends into?
So now, the next step is thought.
I need to search, find the area that the eastern sector extends into, and then find the elevation range of that area.
And then it goes into action.
So it performs an action, which is a search, and then it has some observation.
And then collates it, again, then it has another thought, another action, another observation.
So as you can see, it's a, chain of thought, and it also has actions in it.
So this is actually, the React paradigm that, was talked in one of the presentations as well.
And it is actually able to handle a lot of, sorry, it's actually able to handle a lot of, a lot more complex tasks that would be possible, than would be possible with just a single prompt.
Yeah, so that is another paradigm.
And then, yeah, so as you can see that there's so many things that can be done with prompt engineering and it depends again, on a lot of factors, so generally, the way to progress in this area would be each LLM has a prompt guide, generally they have prompt guides, and it would be good to have a read through that, like that's always, it always helps me, and then looking at different characteristics, like the number of parameters, that I'm working with, how much data it has been trained on, what's the kind of data, what's the kind of tasks it's been trained on, the context length of the LLM, as well as, what kind of prompts that, use, other people have used with it.
And then trying a few standard prompts and then working with them always helps.
Now how would you evaluate, let's say I tried a few standard prompts, like how do I evaluate that the output is good or not?
So you look at the validity of the output.
If it's hallucinating a lot, that is generally, not a good sign.
Look at the format of the output.
Sometimes, if I ask, give me a summary, sometimes it returns in points, in bullet points instead of a paragraph.
I might have to give another instruction.
Then, the stability of the output.
Am I getting the same output when I run it multiple times?
And can I tweak that?
Because that's very important for production level use cases.
As well as the safety.
In some use cases, it's very important to consider safety because you're working with a lot of users as well as yeah, safety is important.
And yeah, just to introduce, yeah, just a little bit about Crayon, the company that I work for.
We have a lot of NLP expertise across the globe and yeah, feel free to reach out to us.
And yeah, that's, me.
Thanks.
Any sufficiently advanced technology is indistinguishable from magic, and the results some people can get from LLMs and image generators and prompts does seem like magic. But is there more to it than just intuition and taste? Can you learn to be better prompt creator? Let’s find out! (hint, you can).