Effective CSS refactoring
Without proper rules and strategy, CSS is a language that lends itself to misuse.
CSS is a very efficient language and it features a somewhat simple syntax.
We just write selectors and declaration blocks, the structure them, assign them and override them pretty much however we want.
This leaves, the door open for many potential issues like bloated code, greedy or over specified selectors, duplicated code and more.
These issues could also be the result of rushed development with a strict deadline, uneven skill levels within the team, or lack of standards or code review on a project among others.
Whatever the case may be, code base quality decreases over time.
Technical debt keeps piling up as the project grows with more features being added, resulting in unexpected and unwanted side effects that make development increasingly difficult and time-consuming.
At that point, we should consider refactoring CSS.
Going over and improving large parts of the code base however, isn't an easy task.
You might be thinking, you just delete the faulty code, replace it with a better version and deploy the shiny new component.
But there are more details in between.
And today we'll take a closer look at these important details and more.
But before we get to refactoring, we'll have to start at the very beginning and ask ourselves a question: how did we end up with the subpar CSS code base in the first place?
We don't have to look too far for an answer.
CSS makes it easy for us to accidentally create issues-specificity, cascade, and source order dependency can lead to over specified selectors, unnecessary overrides, and the need for undoing styles.
And there is also the global nature of CSS.
Styles from some greedy selectors can leak into the different parts of the code base and cause bugs in seemingly random places.
These kinds of issues are also known as "regressions".
Upcoming features like cascade layers aim address these faults by handing some control over to us.
However, we still need to rely on our knowledge and follow best practices, which also brings me to the next next point.
These issues can also be caused by errors and oversights on a project team or individual levels.
For example, uneven skill levels within a team, different preferences and code styles, poor understanding of the project structure and existing code, lack of documentation and standards, just to name a few.
But don't just take my word for it.
The team at Netlify have refactored their CSS code base just last year.
They pointed out that decreasing code quality and difficult maintenance were the main reasons for refactoring.
They've also noted that the lack of internal standards and documentation made the issue even worse.
What are the impacts of subpar CSS?
Well, we might notice that feature development is slowed down by bugs and regressions, or we might even have difficulties reusing styles because of the over specified selectors and strict HTML structure.
Or the code base could be bloated by duplicated or unused code.
As you can see these issues not only affect the end user, but also the team behind the project, and also the management.
It makes maintenance and feature development difficult, time-consuming and more expensive as a result.
This is a good argument to bring up when advocating for CSS refractoring.
It is a more complex process than just deleting and replacing code.
It takes some prep work before we get to that point.
It's a good idea to start by auditing the code base and setting some measurable goals for refactoring.
Having some data on hand is also useful when convincing the management to invest resources.
These goals could be, for example, decreasing overall selector specificity, removing duplicated code, optimizing CSS file size, making selectors more usable and so on.
We can also use these goals for progress tracking and comparisons after refactoring has been completed.
There are many great tools out there to get you started.
Many of them are free to use.
My favorite tool for auditing CSS is CSS Stats.
It gives us a general overview of the code base and we can draw useful data which can help us pinpoint weaknesses and improvement opportunities.
There is also Wallace CLI, if you are looking for a useful terminal command that you can run on your machine or integrate into a CI pipeline to keep track of the CSS code base during the project life cycle.
Wallace team also offers a free tool, similar to CSS Stats, which could also be very useful for quickly checking the state of the CSS code base and getting some useful data for refactoring.
After analyzing and getting some general sense of the CSS code base state, we have several options on how to deal with the issues we've, deleting everything and completely rewriting CSS from scratch is rarely a viable option.
Rewriting is an expensive and time consuming process.
It puts more pressure on the developer as they have to maintain the legacy code base while working on the new one, making sure that features between the two code bases are in sync.
Rewriting is a viable option for scenarios where a more substantial changes i required, like in the case of a complete project redesign or rebrand, or when refactoring is a more expensive option, like on a project that has severe issues and requires a total overhaul.
On the other hand, refactoring allows us to continuously work on improving the code base and deploy these improvements in chunks that can be easily tested and reviewed.
These changes are small in scope, and usually don't introduce breaking changes or add new features.
Refactoring also allows us to switch seamlessly between refactoring tasks and regular feature development tasks.
It is also a cheaper and more flexible option, but it's still difficult to convince management to invest resources, as refactoring usually doesn't yield any visible changes.
However, there is still an indirect benefit for both clients and customers as healthier codebase results in easier and less expensive maintenance and faster feature development with fewer bugs and regressions.
Refactoring CSS should be done from time to time when there are no substantial design or content changes in the pipeline for the foreseeable future.
It wouldn't make sense to advocate for CSS refactoring if a complete redesign or migration to a new tech stack is planned.
Project managers and clients should be aware of refactoring from the get-go.
Ideally they would make sure that refactoring is included in a maintenance budget as a way to prevent future issues.
Teams should keep track of weaknesses in their code base and proactively address them in between developing features and doing maintenance.
Let's assume that we got the green light for refactoring, and we have pinpointed weaknesses in our CSS code base and marked some components which need to be refactored.
Depending on the code based state the overall amount of work may vary.
In a healthier code base, only a small portion of the code base will need to be refactored.
And in the less healthy code base, a larger portion will need to be refactored.
It's a good idea to first sit down with the team and discuss overarching goals, outline some tasks, outline the refactoring process and try to anticipate any challenges that might slow down the progress.
Keep in mind that refactoring should be performed and planned in a way that doesn't block maintenance and feature development, as management will still expect us to deliver features and bug fixes without delays.
That can be achieved mostly by keeping the task scope as small as possible.
It makes the tasks more manageable and easier to test and integrate with the code base.
Carrie Roberts coined the term "refactoring tunnels".
So let's see why this analogy fits with our tasks.
Let's say we want to refactor styles for every input element on the project.
That includes text, email, password, date, and others.
This task has a large scope and the team cannot see the end of the tunnel right away.
A lot of things can break along the way and unexpected issues can slow down the progress.
For example, some inputs might, might be dynamically loaded by a third-party plugin and some other inputs might require a specific CSS class or HTML structure for JavaScript functionality.
We might even miss a few inputs due to human error.
As the scope grows, so does the number of unexpected issues, regressions and additional work.
It gets more difficult to keep up and it comes to the point when no one can tell when the task is going to be finished.
We can spend days or weeks working on it and keep running into walls, gain more technical debt and make the code base even less healthy.
The main code base could also be updated with some new features in the meantime, causing much conflict and making the integration difficult.
We ended up giving up on the task, or starting over, wasting time and resources in the process.
Let's compare this example to a task with a smaller scope, improving just the inputs on the login form is a smaller and more manageable task.
It is also easier to test and verify.
Even with potential issues and challenges that could slow down the task, there is a high chance of success.
Even if we run into the previously mentioned issues with JavaScript and third party plugins, we are always focused on this narrow scope.
We can always see the end of the tunnel because we know the task will be completed once these exact components have been refactored and all the related issues have been fixed.
Management cannot keep track of the progress on their own, as refactoring yields little to no obvious visual changes.
We need to have transparent communication to keep the management and other parties updated on the refactoring progress and results.
The dev team at Trivago highlighted the importance of establishing transparent communication channels between the development team and management.
We've seen how planning and preparation are a key part of the refactoring process.
Now we are ready to start working on the code.
This also requires a surgical approach to make sure that refactored code is safely integrated with the current code base and is free of the overarching issues.
We'll use an incremental refactoring strategy.
Carrie Roberts outlined this great approach more than five years ago, and it is one of the safest, most effective and robust CSS refactoring strategies that I've used.
Let's take a look at the example we'll be working with.
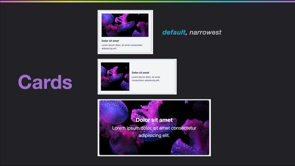
Here we have a title and a simple grid layout with card components inside it.
We'll be referring to this code base as a legacy code.
Let's focus on the card component and get the general sense of the markup and styles.
Here we have a card class selector and a shared button and CTA class selector.
We can immediately expect to see some high specificity and complex selectors.
Not only that, card components styles are difficult to reuse and extend as they enforce a specific HTML astructure.
There are also some cases of bloated code and undoing typography styles.
Element selectors, and leaking selectors also influenced card component styles.
The card component uses a shared button.
There is also a grid and heading element.
These selectors leak typography styles that are being reset in the card selector.
We are essentially writing more code to achieve less styling by undoing these styles.
First, we need to choose any low scope component to start with.
In our case, we have a choice between a grid and a card component.
Let's assume that the general less specific components like grid are used more frequently.
So the card component is our safest choice.
In a nutshell, this is what the card component markup and styles look like.
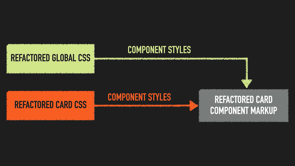
CSS weaknesses are present in both the card styles and global styles.
So our refactor card component shouldn't make any use of them.
To make our new markup and styles independent of the current code base, we need to develop them in isolation.
We can set up a new environment with the CSS flavor of our choice, but we can also use a simple online editor like codepen to quickly develop component markup and styles.
We also want to make a clear distinction between legacy and refactored parts of the code base.
So we'll use an 'rf' prefix.
That will allow us to keep track of our progress and let other team members know which components have been refactored and which are still a part of the legacy code base.
For this example, we'll use block element modifier methodology, and avoid enforcing specific HTML markup to make the card component more reusable and extendable.
Your approach and solution may be different depending on the improvements you want to make and how you choose to implement them.
We finished developing the card component away from the legacy code base.
We need to replace the legacy HTML markup and add the refactored CSS to the current codebase.
We don't want to remove legacy styles right away.
By making too many changes we'll lose track of the issues that might stem from these two conflicting code bases.
For now, lets just replace the markup and add refactored CSS to the existing code base and see what happens.
We made sure that the refactored code is flawless and follows the agreed standards and best practices.
However, when we integrated these components back into the main code base, the leaked styles started effecting it and causing issues.
The legacy card component that we replaced had some slapdash styles applied to deal with the leaky styles.
But we don't want to reintroduce these workarounds and overrides.
So what else can we do?
We can create a new CSS file called overrideCSS or defenceCSS to prevent styles from leaking into the new components.
They should be a temporary file and should contain all hacky and high specificity code, which only needs to stop regressions and style leaks.
It is helpful to leave some comments, to keep track of the overrides as this file can also act as a makeshift to do list.
It also documents style leaks, and weaknesses that need to be addressed at some point.
When legacy components have been replaced with their refactored counterparts, and when all integration bugs have been fixed with the overrides file, we can safely delete the legacy component styles.
The next thing we need to do is test and deploy these changes.
In some cases we might even consider doing AB testing to check if the refactored component has an impact on user experience.
Regardless of how we choose to deploy the component, we want to avoid introducing issues and regressions in the codebase.
Using automated visual regression testing tools like Percy or Chromatic on a pull request level can speed up testing and allow developers enough time to address regressions early.
These tools usually take screenshots of individual pages and components, compare them and notify developers of any changes that happened in the merging process.
As we all already know by now, refactoring doesn't result in obvious visual changes in most cases.
So the visual regression testing process can be as simple as checking if any changes happen at all, and making sure that these changes were intentional.
Now, all we need to do is repeat this process for all components marked for refactoring and components referenced in our overrides file.
Ideally, we want to end up with an empty overrides file once we're done.
You might have noticed that we created highly scoped styles for general components like buttons and titles, and haven't reused the existing ones from the legacy code base.
Developing these components in isolation will sometimes result in duplicated code.
However, it is easier to deal with duplicated code in isolated components compared to fixing the issue in an entangled and messy codebase.
Let's use a button component as an example.
If the legacy button component isn't marked for factoring and is okay to use, we should just replace the refactored classes with legacy classes and remove the refactored button styles.
However, if the legacy button component is marked for refactoring, we just go through the same refactoring steps and replace it incrementally.
Analyzing CSS codebase, planning, defining low scope tasks and using incremental strategy paired with automated visual regression testing results in a seamless and effective refactoring workflow.
This ensures that the improved components can be safely integrated back into the main code base.
Refactored components are also protected from style leaks and other weaknesses until they get also addressed.
For large-scale and more complex refactoring projects, it's important to keep track of the progress.
Project boards, GitHub issues, and regular management tools can do a great job.
However, they are not ideal for giving us a quick overview of the progress.
This is where our "rf" prefix on CSS class names comes in.
This prefix not only allows developers to separate the refactored CSS code base from the legacy code base, but also to do a quick checkup on a per page or per component basis.
No matter how easy and effective incremental refactoring strategy is, prevention is still better than the cure when it comes to CSS.
So I would like to take a few minutes and share some general tips about writing high quality CSS.
The best tools that will help you do that are discipline, attention to detail and a general understanding of CSS.
We need to be constantly aware of the bigger picture and understand what role our CSS plays in it.
On paper, UI components should be robust, extensible and reusable.
You can achieve that by learning how to use specificity and cascade to your advantage.
Learn how to use advanced patterns like object-oriented CSS.
Utilize single responsibility principle, and compose styles efficiently.
Make sure to keep up with the latest CSS features, practice and continuously improve your skills.
And most importantly, learn from mistakes.
I highly recommend checking out CSS guidelines, which covers this and much more.
This is a great guide for both junior and senior developers.
Additionally sites like front-end mentor can help you improve and test your skills with UI coding challenges.
It removes the tedious prep work that is usually required when practicing CSS like finding a good free design, preparing assets like images and fonts and setting everything up.
All you have to do is pick a design, get all the assets and start working right away.
Some improvements should be also done on a project level.
One such example is establishing rules and internal CSS standards.
Clearly defined standards and code style can result in many such benefits as unified and consistent code style and quality, easier to understand and robust code base, streamlined onboarding and code reviews.
And lastly use automated CSS linting tools like to enforce basic rules and establish a consistent code style.
Linters cannot tell us how to structure the selectors in the best possible way and write high quality CSS.
However they can help us enforce some rigid and predictable rules and help us onboard new team members.
In conclusion, CSS code based quality decreases over the project lifecycle.
Refactoring is needed to keep the code based, robust, usable, and free of bugs and regressions.
We should analyze the CSS code base for weaknesses, outline tasks and make sure that they have a low scope.
Then we can use an incremental refactoring strategy to develop components in isolation and merge them back into the code base while fixing any issues we encounter using overrides file.
We can use visual regression testing and AB testing to make sure that the refactored components meet the performance and usability standards and do not introduce bugs and regressions.
Last, but not least we should establish transparent communication and keep all parties informed about the progress and improvements.
Thank you for your time.
If you have any questions or feedback, feel free to reach out on Twitter.
Enjoy the rest of the conference.
CSS refactoring is not an easy task. It requires a detailed analysis and audit to discover weaknesses and issues in the codebase. Choosing an effective refactoring strategy is also a challenge – The scope of changes can range widely per task, and the substantial changes can introduce bugs and regressions in the legacy codebase. In this talk, we’ll cover these topics and more – we’ll learn what makes the CSS codebase unhealthy and how we can combat regressions and catch them early in the development process.