How to read a WebPageTest waterfall chart
Hello, I'm here to talk to you about a tool you may or may not have heard of.
And that is WebPageTest.
This talk is mainly about a very specific part of WebPageTest and that is the waterfall chart.
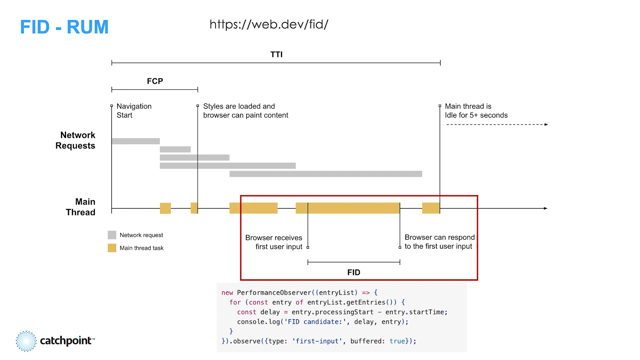
Now the chart may look intimidating at first, but once you understand it, the visualization really unlocks a heap of information for you at a glance, allowing you to quickly debug issues, certify that issues have been fixed, and understand exactly how a browser loads a page.
There are a couple of bits of assumed knowledge for this talk.
First is a WebPageTest URL.
For those who are unsure, it's this.
This will bring you to the public instance of WebPageTest, where you can test your site's performance for free.
Second is that you have run a test.
Don't worry though.
If you haven't run one, I just so happen to have written a whole blog post about it right here.
It's a shameless plug, I know.
So first let's cover a little background info.
What is WebPageTest?
WebPageTest is a synthetic performance testing tool created by Pat Meenan back in 2008 while he was working at AOL.
It was originally an IE plugin called Pagetest before evolving into the online version we see today.
WebPageTest was recently acquired by Catchpoint in 2020.
Pat, along with the rest of the Catchpoint team will help maintain and grow it in the future.
But for the past 12 years, the public instance of WebPageTest, including all the test devices have been sitting in Pat's basement.
This image is from 2014, I assume it may have changed a little in seven years.
WebPageTest allows you to run web performance tests from any of these locations in the world.
You can configure the test agents to test your site using a whole host of browsers with many different connection speeds.
The data you get back from the tool is invaluable for spotting and fixing web performance issues.
Enough of the history of WebPageTest - let's dive right into the waterfall chart UI.
Here's a basic web page test waterfall chart.
The test is from my own blog.
This chart is essentially a visualization of the raw data you get back from various browser APIs.
I've split the image into seven sections - I'll go over each one very briefly.
Number one: the Key.
Here we see a series of colors - first, a set of browser and connection events like wait, DNS, connect, and SSL.
Next, a set of color-coded files by their mime-type.
You'll see two color tones for each.
I'll come to what this means a little bit later.
Last, in pink to the right is the JavaScript execution time.
Each of these colors corresponds to an event or request you see in the request timeline.
Number two: the Request List.
Here, we see a list of assets found on this particular page.
They are in the order that the requests go out over the network.
The HTML in this instance is at request number one right at the top, but this isn't always the case - redirects and OCSP lookups can sometimes come before the page HTML.
Number three: the Request Timeline.
Here we see the waterfall.
It's much like you would see in the network tab in your developer tools.
The color coding we saw earlier in the key applies here.
Each asset is on its own separate row.
The time in seconds is seen along the top and the bottom of the image.
This could be in milliseconds for some tests.
There's a whole lot more going on in this image that I will cover soon.
Number four: CPU Utilization.
Here we see a line graph of how much load the CPU of the test device was under at any point in time during the page load.
It ranges from zero to a hundred percent utilization.
It's always good to keep an eye on this chart, especially on low spec devices.
This is to see if the CPU is becoming a bottleneck for performance.
Number five: Bandwidth In.
This graph gives you an idea of the data flowing into the browser at any point in time during the page load.
The absolute scale isn't particularly accurate, but it roughly relates to the max bandwidth allowed on the connection.
In the example here, max bandwidth is 1,600 kilobits per second, and this equates to a 3G connection.
You mainly want to use this graph to check that the browser is doing useful work rather than time being wasted during the page load.
There is a much more accurate option available called a 'tcpdump'.
This is located on the Advanced Settings tab when you configure the test.
You should enable this if you want more accurate results that you can examine using tools like Wireshark.
Number six: the Browser Main Thread.
So this image isn't taken from my blog - since it's only a very small static site, it's nowhere near as busy as this.
This is actually taken from one of the popular news websites here in the UK.
Each of the colors corresponds to a particular task that the browser's main thread is doing at any point in time.
The y-axis corresponds to the percentage of time that the task is taking up.
This graph is great to spot where the CPU is becoming a bottleneck and what task is causing it.
Also note that these colors may look very familiar if you've used the 'Performance' tab in the Chrome dev tools as this is where the colors are copied from.
And last, number seven: Page is Interactive, or Long Tasks.
So this bar has now been renamed to long tasks.
You may see it in older waterfall charts as 'Page is Interactive'.
The measurement hasn't changed - just the name.
This thin bar gives you an indication of when the browser main thread is blocked.
If the main thread is blocked for 50 milliseconds or more, the color will be red.
If not, it will be green.
Note that a blocked thread may impact on inputs like button presses, but browser scrolling is likely to be unaffected, as this is handled off the main thread.
So now if we pull all this together again, this UI hopefully makes a little more sense.
You can think of this graph as a story of how the browser loads a page.
So chapter one: it's first connecting to the server.
Chapter two it's downloading and parsing HTML.
Chapter three: requesting additional assets.
Chapter four: pixels rendered to the screen.
And the final chapter where the story ends is the finalized page, with all the assets loaded.
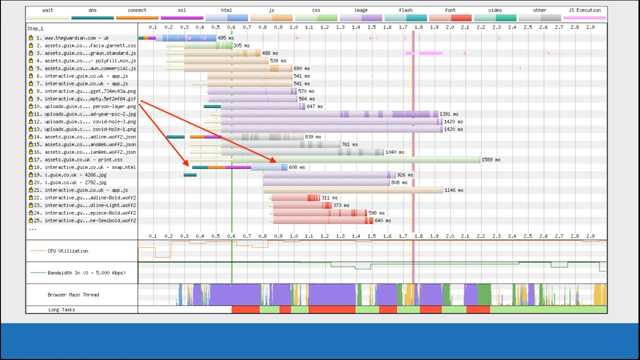
Let's pull out some specifics for the waterfall you can see here.
So first let's focus on request number one.
We see a connection to the server.
The HTML has been downloaded and parsed.
Then additional page resources found and queued for later request - note the pink lines mixed in with the blue asset color of the HTML -this is JavaScript execution happening during the HTML download and parsing phase.
Or in other words, this HTML page has two large sections of inline JavaScript within the page source.
Next, on request 14 we see an additional TCP connection established under HTTP/2.
This must be due to the asset requiring a CORS anonymous connection, since this domain has already been used to download the other assets on requests two to five, using the connection established in request number one.
Next, request 18.
Another TCP connection, and the color of the asset is in blue.
This is a request for another HTML page, most likely triggered by some JavaScript execution.
Now, the reason why I say it was triggered by JavaScript is because notice the TCP - where the TCP connection starts.
It lines up with the inline script execution within the HTML on request number one.
So there's a very good chance that this is where it was initialized from.
Also notice how busy the CPU, Bandwidth, and Main Thread graphs are.
This page is really working this device in all areas.
That's not necessarily a bad thing.
That's a lot of useful work happening, for example.
The observant among you may have noticed a set of lines in different colors vertically down the page.
These lines are specific events that happened during the page load.
In the example on the slide, we see Start render in green at 0.6 seconds.
Here the first pixels are painted to the screen.
DOM interactive at 1.75 seconds is in orange.
HTML has been parsed and the DOM has been constructed.
Document complete or the onload event is fired at 5.5 seconds.
So static image content is loaded, but changes triggered by JavaScript execution may not be included.
There are other lines that aren't on this chart, but can be seen in the key above the waterfall.
So look out for those two.
And finally, the Request Details panel.
Each horizontal row is an asset request.
If you click anywhere on the row, a panel will pop up with a heap of information specifically about the selected request and the response back.
Basic details like the protocol and timings all the way through to request and response headers.
If you're looking for all these details in a large JSON blob, then the 'Raw Details' panel will give you this.
Using this panel for each request, you can really dig down into the details.
So now we've gone through the basic layout and what it all means, let's look at some more advanced examples and point out some of the features.
Using WebPageTest, it's easy to examine the difference between HTTP/1.1 and HTTP/2.
It's a good example to focus on as it's really easy to spot the differences.
Both tests are from testing GOV.UK on a desktop Chrome using a 3G connection.
First let's look at HTTP/1.1.
Notice the multiple TCP connections.
Notice how eager the connections on requests three and four.
This is the default browser behavior for HTTP/1.1, where it creates multiple connections early in anticipation for downloading multiple assets.
There's one DNS lookup shown in red, which is then reused for the other TCB connections shown in green.
And what's known as 'download chunks' can be seen heavily in requests 5-7 and 17-18.
So what are download chunks?
So this is where the two-colored shades I mentioned earlier start to come in.
The lighter color at the start is the time at which the browser sent the request to the server.
The dark chunks are data coming back from the server for this particular request.
You might be asking what the yellow weight bars signify?
So this is a point at which the HTML has been parsed, but the request for the asset has yet to be made.
You can see this in the waterfall by looking at where the blue HTML ends and the yellow wait bar starts.
In this case shown here, the wait time is probably because there are no free established TCB connections to make the actual request.
Also notice how the bandwidth chart has empty sections missing from it.
In this example, we have separate TCP connections fighting for limited bandwidth, but even with multiple TCP connections, the bandwidth isn't fully utilized.
This is what I meant before by the term 'useful work'.
By making sure the network connection is fully utilized during this important loading phase, it should in theory improve performance by maximizing the number of bytes received by the browser.
Now let's compare the exact same page, browser and connection under HTTP/2.
First thing to mention is how overall the waterfall looks a lot cleaner.
There's now only a single TCP connection on request number one, and this is used for all asset downloads.
There's not as much download chunking, as prioritization is happening over a single connection.
Under the hood, Chrome sets an exclusive flag for the stream dependencies on each resource.
So it downloads the assets in order from a long internal list.
Here's an interesting observation.
We seemingly have a single rogue DNS lookup on request 17, but it has no associated connection and SSL negotiation or the orange and pink colored bars.
This is actually HTTP/2 connection coalescing in action.
The assets domain and the root domain are different domains, but they are on the same infrastructure.
They both share the same IP address, and SSL certificate.
So the browser can use the existing TCP connection and SSL negotiation that was established on request number one, therefore all assets will download over the same single connection, even though they're on separate domains.
Note the bandwidth from 1.1 to 3 seconds is maxed out.
We don't have gaps over this time period like we did on the HTTP/ 1.1.
This is useful work being done by the connection.
If I quickly flick back and forth between the two, you really get to see the difference between the waterfalls.
Here we see that WebPageTest has exposed the internals of how the browser downloads a page under specific conditions.
If I were to run the same test under Firefox or Internet Explorer, this picture would look very different.
Briefly going back to the subject of download chunks again - there's a very simple way to see the data that powers these chunks visualization.
Clicking on the request you want to examine, you'll see a 'Raw Details' tab - this tab was mentioned before.
The tab gives you all the JSON related to this particular request.
Scrolling down this tab, you'll see a chunks array.
This array contains multiple objects.
Each object contains the timestamp of when the chunk completed (not started) and the number of bytes downloaded within this chunk.
WebPageTest works backwards from the completed time.
It then looks at the number of bytes downloaded and the available bandwidth at the time to calculate the chunk width to be displayed in the visualization.
Next up: Error/Status Codes.
WebPageTest will make it very obvious when it encounters the status code other than 200.
So just a brief note on this chart in this example - it's very easy with JavaScript and asset-heavy pages for a chart to become hundreds of requests long.
In this example, many requests have been omitted from the waterfall to make it easier to read.
These omitted requests can be identified by the three dots highlighted in green.
(Look for the customized waterfall link under the waterfall diagram to do this).
Back to our error and status codes.
Requests 1-10 are fine.
They're all '200' status codes.
Requests 99 and 101 are error codes (and the red background may have given this away!) In this case, they are '400' response codes, which refer to a bad request.
You can see the status code is seen in brackets after the request timing data.The timing value seen is the time taken to complete the request.
This includes a TCP connection negotiation if required, but excludes wait time.
Requests 123 to 130 are '302' status codes.
And these are seen with a yellow background.
The '302' code is the 'Found but temporarily moved' status code.
Notice how the browser still has to set up expensive TCP connections in a few instances, just to receive this '302' status code.
This is certainly something to watch out for when using third parties.
Next up - in a recent edition prompted I believe by Andy Davies - each request comes with a document value in the 'Details' panel that tells you where the request was initialized from.
Requests 2-5 are initialized from the root document as the text is in black.
Requests 11 and 28 are for a new HTML document - as notice that the asset is in blue.
Also note that the text is in blue to signify it has a new document value.
So this request was initialized from somewhere other than the root document.
This is most likely an iframe.
Notice further down - requests 47-49 also have blue text.
These are assets being downloaded by the iframe.
The blue request text doesn't only happen with iframes, it also happens with service workers and all the assets that they download.
And here's how it displays in the 'Details' panel when clicking on the requests.
Top image, we see the root document.
Bottom image is a third party iframe from Google with a different document value.
I mentioned the pink lines for JavaScript execution earlier.
The JavaScript execution can be seen in pink on the request row that triggered it.
In this example, we see a solid block of pink, but is this very intensive JavaScript running or just short but fast repeating execution?
Looking at the 'Page is Interactive' (or the Long Tasks) bar below it gives an indication in this example, since it's solid red.
But a recent modification to the JavaScript visualization has made this feature even more useful.
Now, when JavaScript execution is rendered, you don't always see a solid block of pink.
The height of the pink bars indicates how quickly the JavaScript ran.
So fast but frequent JavaScript execution will have very short height bars, so they no longer dominate the view.
This functionality is only available in Safari and Chromium-based browsers.
Firefox doesn't expose this information.
Wouldn't it be great if you could add your own custom markers to the waterfall chart to see where certain events happened during the page load?
It's actually quite simple.
Just use the 'mark method' in the user timing API and add it to your page code.
These marks will be shown on the waterfall as vertical purple lines.
Note that these user timing marks don't show up in the default waterfall chart on the public instance of WebPageTest.
But if you have your own instance, they can be enabled by default.
The only way to see them using the public instance is to view the waterfall using the 'customize waterfall' link below the waterfall chart, which I mentioned earlier.
And this is a view you can see in this slide.
The reason for this is because many third parties leave these marks in their code, meaning there'll be a lot of noisy looking waterfall charts when using third parties.
And the last point on this, the actual timings of each of these events is shown just below the summary table for the test run.
So let's quickly look at some scenarios and see what we can learn.
Now, you may have seen this pattern in previous slides I've shown, I just haven't pointed it out to you.
When running a test using Chrome, the resulting waterfall will have a common pattern.
This pattern is called the 'stair step'.
The top step can be seen in red, the bottom step is seen in black.
So what's happening here?
This is essentially a separation between the assets in the head and the body.
It's a prioritization strategy that Chrome uses to improve performance.
Chrome will dedicate most CPU and bandwidth to getting the page head set up before then concentrating on the assets in the body.
This example (under HTTP/1.1) - notice the TCP connection on request 15.
This request is for an image that's located in the body, but it's been requested at the same time as an asset in the head.
So Chrome isn't completely ignoring the body, but resources in the head are the priority.
So I mentioned earlier about the CPU graph at the bottom of the waterfall chart.
So here's an example of what can happen to a waterfall chart when the device is CPU-limited.
It looks fairly standard until you look closely, then you'll notice the gaps between the requests.
These gaps on requests 24-26 show a large amount of inactivity that has a huge impact on performance.
If you examine the CPU graph directly below these gaps, it points to the reason why it's happening.
The graph is maxed out at 100% over this time period.
But we see the opposite for the network activity.
There's nothing really happening.
Examining the Browser Main Thread, there's some script parsing and execution in orange.
There's some page layout tasks in purple, but nowhere near enough activity to cause the CPU issue seen here.
So something odd is going on.
I'm afraid I don't have an explanation as to why the CPU is so maxed out.
Maybe it was just a low spec device that was having particular issues for this test?
But it shows how useful the other graphs can be when used in conjunction with the waterfall chart.
And finally, an unusual waterfall that cropped up on a government service recently.
I've actually written a whole blog post about this waterfall chart and what was happening.
We use SpeedCurve to monitor our services at GDS.
These tests run every day and look for web performance issues.
On this service, we saw the number of fonts being downloaded literally double overnight from three to six.
And nothing had changed - no releases, no code deployed - it just happened randomly.
Examining the graph, you can see the font size double.
In fact, the historic graph data shows this issue had randomly happened and fixed itself many times previously.
If we look at the waterfall, it gives us some insight into what's happening.
Looking at requests 12-14 for the WOFF2 fonts, you'll see this really strange set of gaps between the download chunks.
Now, it took a while to figure out what the issue was, but a long story short, we weren't serving the 'vary: origin' header with our fonts.
The CDN cache was being poisoned and serving up the fonts with the incorrect headers.
Another device was connecting, the headers for this device were being cached and served to our test browser on a completely separate device.
The browser was seeing these incorrect headers and immediately rejecting the fonts.
You can actually see all this happening in the waterfall.
So requests 12-14 are made for the WOFF2 fonts, very thin slices of data are received back from the server (and these are probably the headers), the browser immediately cancels the requests, and this can be seen in the waterfall by the light red color disappearing.
Almost immediately after this happens, the browser makes a request to the fallback or WOFF version of the fonts.
This then doubles up the number of font requests and increases the bytes being sent to the browser.
The dark red patches that now look to be floating are likely to be data that is already in one of various buffers between the server and the browser and is already in transit, so it couldn't be canceled.
This is just an example of how much information you can get from a waterfall chart once you understand some of the internals.
Without SpeedCurve and WebPageTest, this would have been almost impossible to identify and fix.
As we come to the end of the talk now, you may be interested in: "Where can I go if I want to find out more information?" Here's a list of links and various resources.
If you want to find out more about WebPageTest.
There's some shameless plugs in there from me, as well as some talks from Pat Meenan and Andy Davies.
I'll share these slides with you after the talk.
So let's talk has been based on a blog post I've written called: "How to read a WebPageTest waterfall chart." I did the research and pulled the information together for this post, but I've had lots of input from the folks from the web performance community, with corrections, additions, and general advice.
So a big thank you to all these lovely folks.
All their Twitters are listed, and they're well worth the follow if you don't already, I hope you found this talk useful.
Thank you for listening.
WebPageTest is one of the most well known and important tools in the web performance community. It’s been actively developed by Pat Meenan since he worked at AOL in 2008. It has become the go to tool for both very simple to very advanced debugging of the web performance of a website. One of its most well known charts is the waterfall chart.
In this talk I’m going to introduce the waterfall chart and also go into detail on how you can examine and read it. The more you understand about the chart, the the more WebPageTest as a whole will be able to help you fix a slow performing website.
Link to Matt’s ‘Nooshu’ website’s blog entry on:
How to run a WebPageTest test
Link to Matt’s blog entry on the:
Vary Unusual Waterfall use case
Matt’s list of additional resources:
- Using WebPageTest – Rick Viscomi, Andy Davies, Marcel Duran (Book)
- Velocity 2014 – WebPagetest Power Users – Part 1 – Pat Meenan (Youtube video of Pat’s Velocity 2014 NYC presentation/tutorial)
- Velocity 2014 – WebPagetest Power Users – Part 2 – Pat Meenan (Youtube video of Pat’s Velocity 2014 NYC presentation/tutorial)
- Velocity 2014 – WebPagetest Private Instances – Part 1 – Pat Meenan (Youtube video of Part 1 of Pat’s Velocity 2014 NYC presentation/tutorial)
- Velocity 2014 – WebPagetest Private Instances – Part 2 – Pat Meenan (Youtube video of Part 2 of Pat’s Velocity 2014 NYC presentation/tutorial)
- Using WebPageTest – Scripting / API / Private Instances – Andy Davies (Link to the London web performance org’s 2016 presentation from Andy Davies)
- How to read a WebPageTest Waterfall View chart – Matt Hobbs (Blog post from Matt’s website)
- How to read a WebPageTest Connection View chart – Matt Hobbs (Blog post from Matt’s website)
- How to run a WebPageTest test – Matt Hobbs (Blog post from Matt’s website)
- How to use WebPageTest’s Graph Page Data view – Matt Hobbs (Blog post from Matt’s website)
List of Twitter handles for peeps Pat recommends:
- Pat Meenan (@patmeenan)
- Andy Davies (@AndyDavies)
- Barry Pollard (@tunetheweb)
- Ryan Townsend @RyanTownsend)
- Simon Hearne (@simonhearne)
- Boris Schapira (@boostmarks)
- Joseph Scott (@josephscott)
- Mike Herchel (@mikeherchel)
- Šime Vidas (@simevidas)
- Rick Viscomi (@rick_viscomi)
- Radu Micu (@radumicu)
- Jeff Posnick (@jeffposnick)
- George Liu (@centminmod)