Designing distributed applications
Hi everyone.
I'm Andrew Betts.
I run developer relations for Fastly.
Today, we're talking about edge networks of which Fastly is one, and we have the opportunity to think about better ways to build distributed applications.
I think a lot of the process of designing modern software architecture is trade offs relating to levels of abstraction.
We can think of it as a choice between control and convenience.
And let me briefly explain that.
In a full stack of components, that power a Web application, or if you must a native app, running on a proprietary platform with a walled garden app store operated by monopolisric technology giant, traditionally you have to manage hardware, operating system, server processes, and your actual application code.
And pretty quickly we realized that the constraints of hardware are not very useful at the code layer and as developers, we don't really have much of a need to configure those things.
So we added virtualization and that gave rise to infrastructure as a service, which uses virtualization as the abstraction point.
But we were all still doing a lot of boring stuff like patching operating systems, even though they're kind of pretend operating systems anyway, that aren't really there.
And then Heroku very wisely said, let's stop all this nonsense.
And we got platform as a service and we stopped worrying about operating systems.
But at this point, we start to see real constraints creep in.
Limitations that affect the way you are actually able to design your architecture.
And this is where we start to see that trade off between the ultimate control of everything about your application and the convenience of not having to worry about stuff that really is a long way away from the concerns that you want to worry about.
Heroku actually published a sort of manifesto on this they called the 12 factor application architecture to try and show that most use cases were still viable within those constraints.
And this set the the parameters of many of today's Web applications.
But running web servers is still expensive and more importantly boring.
So we now move up another layer of abstractions to functions as a service or' serverless', as some people like to call it.
And we don't even have to worry about processes or run times anymore.
We just write code, the business logic, and we only pay for infrastructure when we're actually using it.
This serverless world brought us even more constraints on things like per request processes, maximum run time, and their memory usage per request.
Restricted run time per invocation.
And we had to learn new abstractions for things like state management.
But we gained the benefit of seamless and almost limitless scalability.
Interestingly, coming from a PHP background myself, I've always been quite familiar with the idea of per request processes, so serverless kind of feels like a new take on an old idea to me.
Anyway, it seems pretty clear that the design factors that we learned to love from Heroku prepared us pretty well for migrating to serverless.
With this new serverless philosophy, we've achieved huge advances in agility and scale.
No idling costs, looser coupling, nothing to manage apart from the code, easier and quicker to iterate and build new things.
But consider this.
None of these benefits directly impact the end user experience.
We still mostly run our application logic in central locations like New York as I'm illustrating here.
And at most you have a pretty dumb network of caches run by a third-party vendor, which replicate the fully formed content in locations closer to your users.
Or if you must, you end up creating complex, explicit, intentional architectures to spread and balance loads around the world.
And even though, though these are all serverless components, you still have to manage, orchestrate and provision all of this stuff.
And the more we try to create these proprietary solutions, the more brittle that architecture becomes.
And once again, we're back to managing the boring stuff that gets in the way of shipping the amazing app that's going to change the world.
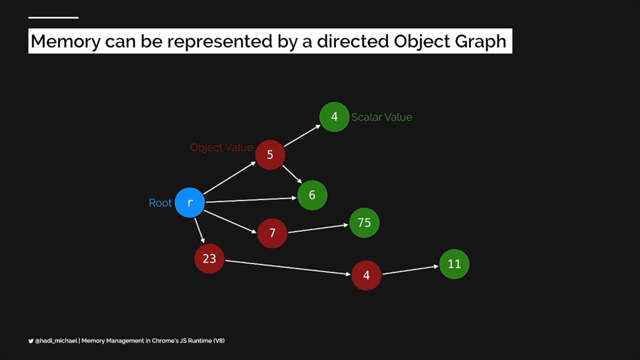
So let's revisit that stack of stuff we started with most of which we've now abstracted away.
And that abstraction means that running the code in more than one place is now something that is no longer an impractical idea.
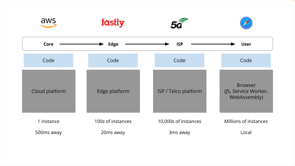
So we could conceive of a kind of a pipeline, a chain of processing locations, strung, strung out between the core of your infrastructure and the device in the end user's hand.
Each made up of a full stack of components, but crucially components that you don't have to manage, nor do you even have to provision or even decide that they need to exist.
Now we can decide where in this pipeline, it makes sense to run our logic.
As we move along the pipe, we find a larger number of parallel instances and different benefits and constraints.
So for example, the core infrastructure, your, your AWS, or, or GCP or Azure, that's gonna be the cheapest place to store very large data sets and global state.
Whilst the device in the client in, in the end, user's hand the client device, that's the cheapest place to do processing cause it's free.
But of course, on the client device, we only get access to one user's view of the system.
Now at the edge, things are a little bit muddier.
We might have access to state, but it is probably a cache or replica, or perhaps it's a shard or a distributed data store that can propagate updates asynchronously.
With service workers, we now have a second way to run logic on the client and using Web Assembly we can extend the capabilities of client devices and also write logic that's portable to other stages in the pipeline as.
Boundaries are blurring everywhere-between the client device and the edge networks like Fastly that have maybe a few hundred points of presence around the world there's also the possibility that you might see smarter ISPs or 5G networks, introducing processing capabilities into cell towers or local exchanges, which means your app is running on tens of thousands of points of presence that you don't control.
But that shouldn't really scare you, after all we're used to running code on the client device.
And there are millions of those, assuming you have a successful app, and you definitely don't control those.
You know, if you did, life would be a lot easier.
So in summary, where we ideally put logic in this pipeline is a function of things like the number of users that are affected or would benefit from this logic, whether you need access to state and what kind of state and whether that state is local or global or whether it needs to be up to date or complete.
Is it transactional?
For example.
What kind of CPU or memory resources you need to complete the task and any regulatory, privacy or security considerations that might override anything else.
In terms of benefits to the end user, the further we move our processing down the pipe towards them, the lower the latency for the user.
So here's a, here's a simple example running on Fastly's Compute@edge that takes an input, it interprets it as markdown and on the, on the Fastly server, it converts that mark down into HTML, and then it returns the HTML to the client device.
Now from my home broadband connection here, the average round trip time to my local compute@edge node is under 10 milliseconds, which allows us to performantly execute this logic on every keystroke.
And importantly, the response time is so fast that it's actually faster than, than a frame of, of a, of a 60 frames per second video.
So this low latency is fast enough to be easily perceived as real time by the user.
And we can actually expect this kind of performance virtually regardless of where the user is, because edge networks like Fastly are designed specifically to provide points of presence near all major population centers.
Now a toy example, like this is great for demonstrating the potential of offloading some kind of workload to the edge, but actually let's consider the pipeline tradeoffs and think about whether we, we are running this particular workload in the right place.
'Cause this is simple, right?
This is small self-contained logic, it's non proprietary code.
The input and output both go to the client side.
So this logic really makes sense to be on the client itself.
But let's imagine that instead of generating HTML from markdown provided by the, the end user, the function is generating it from data that loads from a CMS, the CMS, the content management system that sits in my core infrastructure, and it acts as a global data store.
The edge meets, the edge server meanwhile, that can hold a cache of any API responses received from the CMS or any other system that forms part of my infrastructure and that potentially allows many different pages to be built using the same set of core data in different combinations.
For example, let's say two users request the same article.
They might receive pages that contain data from the same backend API calls, but with subtle differences based on their preferences, their permissions, their identity, their the ads that we want to show at the time.
Imagine your React app, doing server side rendering for each user individually, or your e-commerce site pulling product inventory data and composing it into pages at the edge.
None of this actually requires any major departure from the way we already think about Web application architecture's today.
Here are some other ideas for use cases where we can shift tasks further along the pipeline and benefit from edge processing.
You can think of this as like kind of the outer layers of the onion.
If you think of your, your architecture in terms of layers, we're just peeling back the outer layers and pushing them from the core to the edge, or indeed from the client to the edge.
So it's stuff like personalization, authentication and authorization collecting data from real user monitoring or other kinds of tracking beacons that you have on Web pages or devices.
Facades are really good use case for the edge as well, where you have you have a, a, a, an application like a, a REST API or something really old, like a SOAP API, and you want to expose it to the world in a more modern format, like GraphQL.
Like that requires some kind of compatibility transform.
That's a great thing to run at the edge as well.
So far so good.
But to go further, we really need to, to rethink the architecture quite fundamentally.
What would happen if we let go of this idea of the system being all knowing.
And the idea of, of, of kind of 'perfect' being the standard that we want to achieve.
I guess we already have in many ways by embracing things like edge caching in the first place.
So, you know, in a conventional kind of dumb CDN where the CDN will cache copies of your pages, they might get out to date and we sort of accept that we might serve out of date content to users and that improves performance.
And that's a trade off, but I think it's actually worth properly wrapping your head around this as a design goal, rather than a, a kind of unfortunate side effect of accepting that trade off.
In 2007, a, a guy who's working for Microsoft at the time, Pat Helland wrote a blog post in which he asserted the, what Computing is, is ultimately just memories, guesses, and apologies.
It's brilliant and very short piece of writing that unfortunately seems to have gotten lost in the ether, but you can still find it in the internet archive, archive.org, and I highly recommend it.
And given the subject matter is kind of ironic that it's that the internet has forgotten it.
But [laughs] if we, so if we do this, if we let go of this single global, consistent view of the world, what does that unlock?
Well, for example, we can start accepting write operations, much faster, traditionally edge networks, like Fastly don't do writes, right?
We.
We are there to accept, 'read' requests, 'get' requests, and to very quickly pull things like images, style sheets, and static webpages out of a cache and serve them very fast.
And then 'write' operations would go back to the core infrastructure where the application logic is.
So imagine instead of that, all writes are accepted locally by whichever edge surver is the first server to handle the request.
That that right is then persisted to local representations of state.
And then those local representations are synchronized as needed with core infrastructure or other edge servers in other locations.
And this is particularly interesting for use cases where the writes are updating data that is typically needed to be up to date in the same geographic area where the writes are happening.
For example dating apps like Tinder or ride sharing apps like Uber they're good examples of use cases that can be sharded like this.
They still enjoy some kind of view of the global state.
But mostly they're concerned with working with the data that is geographically local to them.
So, you know, let's say if you swipe right on Tinder on someone who's on the other side of the world from you and they did the same.
Maybe you wouldn't immediately match, but we could reconcile that discrepancy later asynchronously and the trade off is that most of the time you get a really fast performance using the same principle, apps like, say, COVID data collectors could submit data to a local edge server and receive a rapid response.
While the edge then aggregates and contributes that resulting data back to a centralized aggregator.
Now I remember being blown away when I visited CERN, the particule accelerator in Switzerland and they told me that in the instant of a particle collision, the sensors in the particle accelerator generates so much data that barely 1% of it could be extracted quickly enough to be saved.
The rest has to be filtered out by the sensors themselves, which means the sensors actually have to make decisions in hardware before handing the surviving data to the aggregator.
Now, I really love this and especially since CERN is where the Web was born.
They're still at the forefront of figuring out how to move processing to the edge.
Now with crushing inevitability, I am obviously going to go all like universe brain on you at this point and suggest we could just get rid of the core infrastructure entirely.
Are there any large scale apps that can exist with no centrally coordinated state where all the logic runs at the edge, where all the state is stored and managed at the edge?
Sure.
Why not?
And actually there are some pretty good reasons for doing this.
Let's say, take apps whose primary purpose is to provide a means of storing and organizing personal data like Gmail, Pinterest, Dropbox, and so on.
These kind of apps benefit from locating the primary data store for each user close to where that user is physically located.
And with edge cloud platforms, maybe we don't need to spin up separate storage instances in each location.
Instead just allow the edge platform to move the data to where it's being used.
A friend of mine who works for a newspaper, that's a Fastly customer, they suggested to me that as the daily news cycle moves around the world, Fastly should just move their primary database, or we should at least manage where new editorial content is stored.
Because in practice, the people who are writing new content and the audience that's reading that content are generally in the same part of the world at the same time of day.
Now this is something that would be ridiculous to try and do if you had to manage all of that infrastructure and all the orchestration that would be involved in doing that yourself, like the trade-off's just not worth it.
But if the platform does it for free, then there's really no reason.
There's really no reason not to I.guess.
Regulation.
Regulation is a big consideration that we have to apply to decisions about the global architecture of our applications and where a country or a territory legislates to require data.
For example, to be stored in country, edge networks, provide a cheap way to make that a practical option, even for relatively small websites.
And let's think about some things like rate limiting rate limiting is really interesting.
You want a user any one user to be able to make, let's say a thousand requests per hour, but that's globally, right?
Not per edge location.
So somehow you need your whole global architecture to coordinate, to increment a single global counter for each user.
And you really don't want to be in the business of making that work.
But edge networks are designed to solve these kinds of problems.
And we employ people who are good at figuring this stuff out-low latency, but the data storage is still distributed globally.
How do we do that?
Who cares?
I mean, this is a general purpose problem, so it doesn't help you change the world with your world changing app to try and understand the internals of services like this.
But as long as it works, that's all you care about.
This is a glimpse into like one scenario where one edge location might wanna directly communicate with another as part of a specific request or transaction that takes place across a globally distributed application.
You could also imagine using the same principle for like relaying chat messages between users who happen to be connected to different edge locations or streaming game updates for users who are connected to a multiplayer game session.
This is all pretty exciting stuff.
And it gives us an idea of how future applications will benefit from Edge Computing.
But how can we boil this down to a set of design ideas or principles similar to Heroku's original 12 factors?
Well, let's start with these original 12 and bold and, and sort of filter these down a little bit to just the five that I think are critically important in an edge application.
I'm gonna restate those, like this: invoke the logic stateless.
Use backing services like origins and databases.
Expect concurrency.
Expect failure.
And emit events.
These are the sort of cornerstones of serverless.
And to these I'm suggesting that we add a couple more.
First consider remote state.
Let's say that an edge native application assumes that persistent state is controlled remotely, but cached locally.
It updates local representations of remote state and makes use of mechanisms in the platform that reconcile updates to that state asynchronously.
And no single view-an edge application does not need to have a complete and up to date understanding of the world in order to operate correctly.
It's okay to guess, basically.
Thinking in terms of these design principles, I think it helps to drive our application development towards a future of Edge Computing and the benefits that brings-things like more efficiency, more reliability, more environmental awareness, better regulatory compliance, and of course, a better user experience.
These principles are very much just my opinion.
And I love hearing all the other takes that people have on this, this, this, like this Edge Computing world, this is where the experimentation is happening.
It's where the mistakes and the game changing innovations are happening.
And it's a, it's a super exciting place to be.
I'll finish with with one of my favorite tweets.
And huge apologies to any Web designers watching, but I think there's a positive story to tell here which is the Web design industry has has been around for a long time.
It's done a lot of experimentation.
It's learned a lot and today it knows what it's doing.
We know how to solve problems with design and UI.
And sure, maybe the UI we produce is less creative, but it's also objectively more successful.
Edge Computing is still more like this kind of phase, where we are like, "Hey, horizontal scrolling.
That might be good.
Or how about a lime green interface?" Some of this stuff won't work.
But now is a really great time to to be involved and be helping to write this chapter of the story.
And that's all I have.
Thanks for listening.
You can reach me on Twitter @triblondon, abetts@fastly.com and the slides are available to download.
In this talk Andrew will present a number of new concepts for building decentralised apps and help to show that maybe, there’s a solution that would suit you. Modern web apps increasingly share a common set of best practices. In 2012, one of Heroku’s founders published “The 12-factor app”, a thesis on application design that describes pretty well how most scalable applications are built today.
But much has also changed – with a wealth of powerful ‘serverless’ technologies to choose from, application design has evolved. Now, the ‘edge cloud’ is starting to become a mainstream idea, with even small organisations able to harness the power of executing complex applications simultaneously in hundreds of different datacenters to minimise end user latency. Even for things we thought we had to run centrally.
This talk will review the most popular architectural principles of web applications today, and examine how suitable they are for operating an app at the edge.
Executing at the edge is not only very cool and the Latest Thing, it is also a boon to efficiency, is environmentally aware, and a great way to increase the reliability and availability of applications too.