The Expanding Dark Forest and Generative AI
Introduction to the Expanding Dark Forest and Generative AI
Maggie Appleton introduces the concept of the dark forest in the context of the web, drawing parallels to the dark forest theory of the universe, and discusses the impact of generative AI on writing and trust in online spaces.
The Dark Forest Theory of the Web
Explains the dark forest theory of the web as an analogy to the universe's dark forest theory, describing the web as a place where visibility can lead to vulnerability, causing users to retreat from public spaces to safer, more private communities.
Challenges of Authenticity and Interaction Online
Addresses the difficulty of maintaining authenticity online, focusing on the proliferation of inauthentic content and the risks of antagonistic behaviors in public online spaces like social media platforms.
Generative AI and the Future of Online Content
Discusses the role of generative AI in content creation, its potential to saturate the web with indistinguishable human-like content, and the implications for information quality and user experience.
Moving to the Cozy Web: Retreat from Public Spaces
Explores the trend of moving away from public internet spaces to 'cozier', more controlled environments like personal websites, newsletters, and private chats to escape the downsides of the public web.
Impact on Human Relationships and Information Quality
Maggie discusses the potential risks and changes generative AI may bring to human interactions and the quality of information on the web, highlighting the decreasing costs and increasing speed of content creation enabled by AI technologies.
Scenario: Content Overload from Generative AI
Illustrates a scenario where generative AI could lead to an overwhelming amount of content on the web, affecting how content is moderated and perceived, and posing challenges for maintaining content quality and relevance.
Debating the Value of AI-Generated Content
Explores critical questions about the value and implications of AI-generated content versus human-created content, especially in terms of authenticity, social context, and the potential for human connection.
Possible Futures and the Need for Human Verification
Discusses possible future challenges in a web dominated by AI, including the need for humans to prove their authenticity and the potential for a 'reverse Turing test' scenario where the roles of human and machine in proving intelligence are reversed.
Epistemological Challenges in a Model-Dominated World
Considers the epistemological implications of relying on model-generated content as a source of truth and the potential cyclic reinforcement of AI-generated knowledge without real-world verification.
Feedback Loops and Reality Distortion
Discusses how the increasing use of AI-generated content can lead to a feedback loop that distorts shared truths and factual accuracy, potentially leading to canonical misinformation on the web.
AI in Scientific Research
Examines the concerning trend of AI tools being used in scientific research, potentially leading to inaccuracies in published papers and the risk of scientific misinformation spreading due to the uncritical use of generative models.
The Retreat to the Cozy Web
Explores the move towards more private and controlled digital spaces as public trust in the open web deteriorates due to the overwhelming presence of low-quality AI-generated content.
MeatSpace Premium and Authenticity Verification
Predicts a growing preference for in-person interactions to verify the authenticity of digital identities and content, potentially leading to more localized and less accessible communities.
Future Scenarios: Mediated Web and AI Collaboration
Speculates on future developments in AI integration, suggesting a potential shift towards a more filtered, AI-mediated web experience that could help manage the information overload but might also intensify filter bubbles and polarization.
The talk I'm doing today, the Expanding Dark Forest and Generative AI.
This is going to be about, writing on the web, trust and human relationships.
So small fish, and inevitably AI, sorry.
I know this is like a very AI heavy conference.
I feel like we can all do an AI detox after it's over.
But for the moment we have to engage a little bit more in the big monster in the room.
As a small footnote.
Everything I say in this talk is up to date as of a week ago, which means that it's probably going to be completely irrelevant by next week, so we can only speculate for the moment.
This is a QR code that will give you all the slides from this talk and notes, so don't worry about having to take photos of things.
I do have to update it after I finish up here.
It's like of a previous version of this talk and I did add a few extra things for this one.
So give it a day and it'll be better, but for now it'll give you the basics.
I'm going to talk about a few things.
I'm first going to tell you what the dark forest theory of the web is.
I'm then going to talk about the current state of generative AI, as of this week.
I'm then going to ask, do we even have a problem here going to lay out some hypothetical problems, and then we can question if they're valid or not.
And then lastly, I'm going to talk about possible futures, so how we might deal with these hypothetical problems.
First, the dark forest theory of the web.
To explain this, I first have to explain the dark forest theory of the universe.
So this is a theory that tries to explain why we haven't found intelligent life in the universe.
Is my slide going to advance?
Oh, it is.
Okay.
So here we are in the universe.
We are the pale blue dot, and we are the only intelligent life around, as far as we know.
And we've been beaming out messages, trying to find other intelligent life for about 60 years now, and we haven't heard anything back.
So the big question is why, right?
And dark forest theory says that it's because the universe is like a dark forest at night.
It's a place that seems quiet and lifeless, because if you make noise, the predators come eat you.
So it stands to reason that all the other intelligent civilizations in the universe have either died or learned to shut up.
And we don't know which one we are yet.
So yeah, if you draw attention to yourself.
So the dark forest theory of the web builds off this.
So it's a theory that was proposed by Yancey Strickler 2019 in this article.
And he described what it feels like to be in the public spaces of the web right now.
And Yancey pointed out two main vibes, let's say.
The first is that the web can often feel like a very lifeless automated place, devoid of real humans.
It's full of sort of ads and clickbait and predatory behaviors.
That make us retreat away from its public spaces.
Here we are on the web, and we naively write a bunch of very, sincere, authentic accounts of our lives and thoughts and experiences on our live journal, and we're trying to find other intelligent people who can share our beliefs and interests.
But it feels like we're surrounded by content that was made by inauthentic inhuman beings, right?
It's like bots, marketing automations, growth hackers, pumping out generic clickbait that isn't really trying to connect with other humans.
And we've all seen this stuff, right?
It's like low quality listicles, like productivity rubbish, like growth hacking advice, banal motivational quotes, dramatic clickbait, this may as well be automated.
Even if real humans made this, they didn't really make it from their human soul, let's say.
They're really trying to communicate sincere and original thoughts.
And get their ideas across to other humans, right?
They're trying to get you to click and rack up views.
And this flood of very low quality content makes us retreat away from the web, right?
It's very costly to spend time and energy wading through this stuff.
The second vibe of the dark forest is that there's a lot of unnecessarily antagonistic behavior at scale.
So when we're putting out our kind of holistic signals, trying to connect with other humans, we risk becoming a target, specifically from like the Twitter mob that might come eat us.
So there's a term on Twitter called getting main charactered.
And I'm, using the word Twitter here.
I know it's X, but to me it's Twitter cause I'm old.
So every day there's one main character on Twitter and your goal is to not be that character.
So they're the person that gets piled on for saying the wrong arbitrary thing.
So I don't know if people remember this.
This is exactly one year ago it was the garden Woman.
So this woman tweeted about how much she loves every morning waking up and having coffee with her husband, who she loves so much, and talks to him for hours and isn't it great?
Doesn't this seem like a really nice tweet you couldn't take offense to?
What could go wrong?
So one person said, that's cool.
I wake up every morning.
And fight my way through traffic for an hour to get to work, must be nice.
Someone else, again, I wake up at 6am, I work for 10 hours, this is an unattainable goal for most people, even though it was not a goal.
Someone else complains about their morning routine and then says, must be nice to be a trust fund baby with not a care in the world.
Twitter, in, in its greatest form, will take anything and make it, toxic and attack you for it.
I think it was summed up well by this TikTok.
I don't really care if something good happened to you.
It should have happened to me instead.
So this might seem like a dumb example, but it's, indicative of the energy flows of Twitter and pretty much all our social media platforms, right?
Publishing to the open web makes you a target for criticism and not the constructive kind.
People will probably take what you say in bad faith.
Or out of context, or they will amplify it to unintended audiences.
And this is how we get cancellings and pile ons . John Ronson has written an entire book on this, called You've Been Publicly Shamed.
It's a little bit old at this point.
But it explores how cancelling and publicly shaming each other has become a mainstay of social media.
And it has real material consequences for people.
People lose jobs, they're alienated, they lose their community, they suffer emotional trauma.
And this makes the web a very sincerely dangerous place to publish your thoughts in public.
So all of this makes it quite hard to find people who are being sincere online, who are seeking coherence, and who are building collective knowledge in public.
I know this is not what everyone wants to do with the web.
Some people want to make dance videos on TikTok, and that is completely okay.
But I'm interested in at least some of the web, enabling this kind of productive discourse and community building.
And I'm expecting some people here feel the same, rather than primarily being a threatening inhuman place where nothing is taken in good faith.
How do we cope with this?
We are wandering around this dark forest of Facebook and LinkedIn and Twitter, and we realize we need to go somewhere safer.
And what we end up doing is we retreat, primarily to what's being called the cozy web.
This was a term coined by Venkatesh Rao, in direct response to the dark web theory, and he pointed out that we've all started to go underground, as it were.
We move to semi private spaces like personal websites, email newsletters, RSS feeds.
And these help, but they're sometimes still a bit too public, so we retreat even further into private group chats.
These are Slacks, Discords, WhatsApp, Telegram, and this is where we end up spending most of our time, and where we're able to have real human relationships with people who will take our words in good faith, who will allow us to have productive discussions, who aren't going to attack us if we say the wrong thing.
But the problem is, none of this is indexable or searchable, it's hard to access, It's hard to have collective knowledge build up in these private databases that we don't own.
And good luck finding anything on Discord.
Sadly, my theory is that the dark forest is about to expand.
Because we now have generative AI.
Right?
Machine learning models that can generate content that before this point in history only humans could make.
They can do text, images, videos, and audio that mimic human creations.
I'm sure you've heard of some of these large foundation models, we have different ones for text and image and video and audio, we of course now have multi models, multi modal models that are blending these, and of course things like ChatGPT, at this point I don't think I have to explain to you how ChatGPT works or its implications, I think this is quite an educated audience, lots of high quality text that is indistinguishable from human created text, right?
All based on Next Web Prediction, which sounds simple, but actually leads to quite complex, behaviors.
We could of course now generate images too.
These are some from mid journey, which is always very beautiful.
And this is an extra creepy, video from Synesthesia.
[ syntheised person says ] "hello web directions, I'm not a real person I know I seem creepy, but maybe you should get used to me, because I'm about to take over YouTube".
Clearly we still have some work to do on this one, frankly.
Very uncanny valley.
I'm not going to focus as much on video and image implications in this talk.
I'm mostly going to focus on language.
I know deepfakes are a huge problem, but I'm, like, full up on problems.
Someone else is going to have to do that talk.
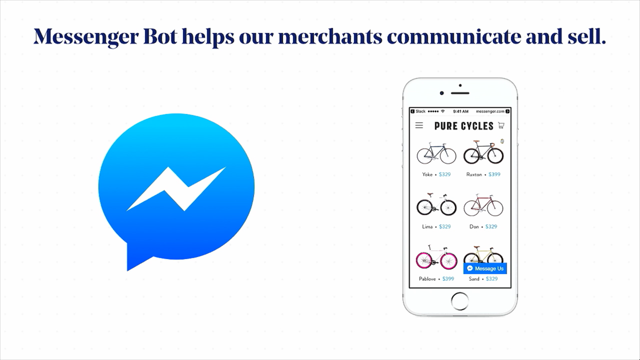
Generative AI products at this point are very easy to use and widely accessible, right?
They don't require technical skills and they're being built into all the products we already use, like Adobe and Notion.
But the product category I'm most nervous about is something that's like pure content marketing and generators.
So I'm going to pick on one called Blaze today, but there are plenty of others, Copy AI, Jasper, that pretty much work the same.
And they, create, social media content for you in half the time, who wouldn't want that?
Who doesn't want more content on the internet?
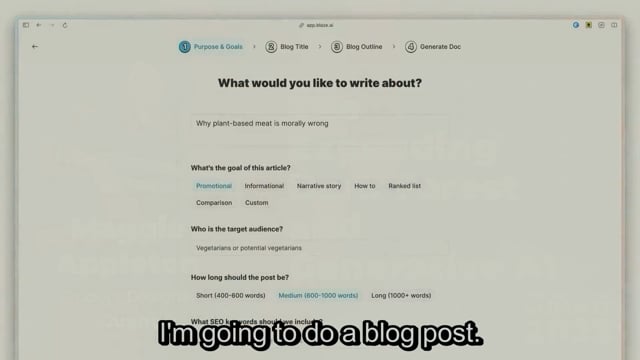
So just to show you how they work, you pick what kind of content you want to make, like a blog post, or a case study, or Google Ads.
I'm going to do a blog post.
And I type in what I want to write about.
I've written, I want to write about why plant based meat is morally wrong.
I do not believe this.
I'm very vegetarian.
But this seems like a nice kind of click baity, moral outrage topic to write about.
And I can pick, my target audience and what SEO keywords I want to optimize for.
So it lets me pick a title, some nice customization here.
It gives me a few options.
And then it writes 700 words on, the moral implications of plant based meat, right?
This is now ready for me to publish, maybe it just gives me a base to work off.
Which if I'm someone lobbying against plant based meat, this is quite handy.
I can generate a hundred of these, they're already optimized for keywords, I can just shove them on the web, hard day's advocacy, done.
The quality and truthfulness of this is clearly questionable, but we'll get to those problems later.
The point is that this is very easy to do at scale, right?
Essentially, this murders Google Search.
Every article in the first hundred pages is just, SEO optimized, generated crap.
Even better, at the end, it prompts me that I can take this same article and reuse it and turn it into a bunch of Instagram posts and a YouTube script and some more blog post ideas.
It's just this endless wheel of content generation.
And there's plenty of other tools that do this, right?
AI linked post generators generate the next tweet.
YouTube content on autopilot.
And the examples I showed, they actually have a quite simple infrastructure.
You take a single input and you feed it into a giant black box mystery, black box mystery, which is a language model, usually from OpenAI.
So you do a single input and you get a single output.
And we don't have a lot of control or transparency about what's happening in the middle here.
We're limited in how sophisticated this output can actually get, so it doesn't seem that scary yet.
But we've figured out some better architectures recently.
So here again we have our black box language model, but now we can give it access to some external tools, right?
We can give it access to searching the web, we can give it a calculator, because it's not very good at maths.
We can give it a calendar because it doesn't understand time.
We can give it access to code and APIs.
Also language models are quite forgetful.
They don't have what we call a large context window, so we can hook it up to a long term data, memory with a database.
And then it can remember a lot of stuff over time.
We've also found that language models perform much better if we get them to reflect on their output and improve on them in loops.
So there's lots of prompting techniques like chain of thought, where you tell it to think step by step, you get it to critique itself, you get it to observe what it knows and then plan the next step.
And all of this adds up to what's being called an agent architecture, where you have one language model that acts as the agent, it has a choice of all these tools, and given the goal that you've assigned it, it like makes decisions and picks what tool to use.
And it's very good at this, and it can then do much more sophisticated and complex actions based off this.
It chains them all together in these observation, planning, reflection loops.
These agent architectures mean we're about to enter a stage of sharing the web with rather sophisticated non human agents.
They're very different to the current bots that we've known before.
They have a lot more data about how realistic humans behave, and they're rapidly going to get more and more capable.
And we're soon not going to be able to tell the difference between them and real humans on the web.
And I want to say sharing the web with these agents isn't inherently bad.
They could have good use cases like automated content moderators or search assistants, but I think it's just going to get complicated.
Why is this a problem, right?
What's even at stake here?
I'm just going to focus on how this will affect human relationships and information quality on the web.
Anything else, like how we might all end up unemployed or dead soon, is well above mt my pay grade.
The cost of creating and publishing content to the web just dropped to almost zero.
Humans are super expensive and slow at making content, right?
We need time to research and think and like clumsily string words together.
And then we demand time to take breaks and eat and sleep and shower.
And then we demand people pay us like extortion at hourly rates.
And generative models require none of these things, right?
They don't need time off.
They don't get bored.
They cost like fractions of a cent to generate a thousand words.
So given that these are cheap, easy, fast to use, and they can produce a nearly infinite amount of content, I think we're about to drown in the In a sea of informational garbage, we're just going to be absolutely swamped by masses of mediocre content.
Like every marketer and SEO strategist and optimizer bro is just going to have a field day filling Twitter and LinkedIn and Google with masses of this keyword stuff generated crap.
And this explosion of noise is going to make it really difficult to find quality content.
And find any signal through that noise.
We can tell this is already happening because spammers and scammers are really lazy.
And this is a, recent Verge article that pointed out that the phrase, "as an AI language model", which is something that chat GPT outputs quite a lot, shows up all the time if you search around on like Amazon or Google.
So they can't even be bothered to remove this very easy phrase that you could control F, delete, out of it, which kind of shows us how much care they'll put into future work.
I did a very quick search earlier today for this phrase, filtered for the site LinkedIn.
16, 000 hits.
Honestly, these are incredibly boring.
People are just trying to create, engaging LinkedIn posts with chat GPT and then not removing this phrase.
The motivation for doing this isn't that hard to understand, but let's think through, a hypothetical scenario, with, Nigel here.
Nigel has written a book called Why Nepotism is Great, and he would like to promote it to the world.
He's a book fluencer.
And he spins up an agent.
Not different to a real book agent you might've hired in the before times.
And then he tells it to promote his book, right?
And he gives it access to all his social media accounts and hooks it up to something like Zapier so it can automate the stuff for him.
And so the agent's great, okay, I'm going to strategize a bit.
And then I'm going to schedule a bunch of tweets based on the book's content.
And I'm going to do the same thing for LinkedIn and Facebook, right?
And then I'm going to schedule like a newsletter that's going to go out every week for six months.
I'm going to set up a Medium account.
I'm going to reuse that newsletter content.
I'm going to make a bunch of addictive TikTok videos.
Maybe I'm going to author a 24 part series on YouTube.
And then I'm going to make a bunch of podcast episodes using Nigel's voice.
You can totally do this, And then I'm going to go reach out to everyone else who writes about nepotism and engage with them and make friends with them and get them to comment on my stuff.
Like, all of this is very possible at the moment.
And none of it's that different to what Nigel would actually do, so it might not get picked up by kind of content moderation filters or spam filters, but without an agent, of course, Nigel would not do this, he doesn't have the time and energy and motivation.
Maybe 1 percent of people who are Nigel like could do it, but most wouldn't.
But now, 99 percent of people have the capacity to publish this massive content to the web.
And obviously we have a lot of spam on the web now, that's easy to filter out and ignore, but I think this like scale and quantity is going to be very difficult for us to deal with.
And I actually think a lot of these people's agents will write better, more compelling content than they might have, so it actually gets into a difficult quality question of whether we want their stuff on the web.
Now imagine how this could play out.
If you had a political lobbying group with quite a lot of money who wanted to maybe deploy thousands of these agents to serve their particular wants and needs, could get pretty dark.
So it's been, yeah, I've been, going through the dark stuff.
We're just gonna take a deep breath.
There's some good news.
The good news is this might actually not be a problem at all.
I think this is only going to be a problem if we want to use the web for a very particular purpose, like facilitating genuine human connections and relationships, right?
Or pursuing collective sensemaking and knowledge building.
Or, grounding our knowledge of the world in reality, okay?
If you don't care about these things, don't worry about generative AI.
It's gonna be fine.
We have, we'll have much more engaging content on social media, you'll be much more entertained.
But the thing is, I'm quite keen on a lot of these outcomes.
I write on the web a lot, and I'm a big proponent of other people publishing their personal knowledge to the web.
Like I bang on about this thing called digital gardening, which is about having your own personal wiki on the web and putting your knowledge out there.
And the goal of all that is to make a web that is a space for collective understanding and knowledge building, and it requires us to find and share and curate really high quality content for one another.
And I'm really worried that generative agents threaten that.
So when I talk to people about my worries, I always get this question.
Why does it matter if a generative model made something rather than a human?
In most cases, language models can actually be more accurate than humans.
We have benchmarks to show this.
They have access to more data.
They can answer questions more correctly than we could, off the cuff.
And surely having more generated content on the web might actually make it a more reliable, valuable place for all of us.
I'm sympathetic to this point.
But I think there are a few key differences between content generated by models versus by humans.
I think it's important to clearly understand them.
So first is their connection to reality.
The second is the social context they live within.
And finally is their human relationship potential, and I'll go into each of these in depth.
So first, their connection to reality, is different to our connection to reality, because we are embodied humans in a shared reality filled with kind of rich embodied information, right?
Taste, smell, touch, all all the important things.
And we read other people's accounts of this reality and compare it against our own, and then we write our own accounts, right?
And this is like the big cycle that we're all participating in of trying to understand the world together as one collective group.
And this is the core of like science and art and literature.
And what we've now done is feed that enormous written record into a bunch of large language models.
And they've encoded those patterns into their networks.
And this has become a kind of representation of the written record of all humanity.
And now that model can generate text that's predictably similar to all the text it's seen before.
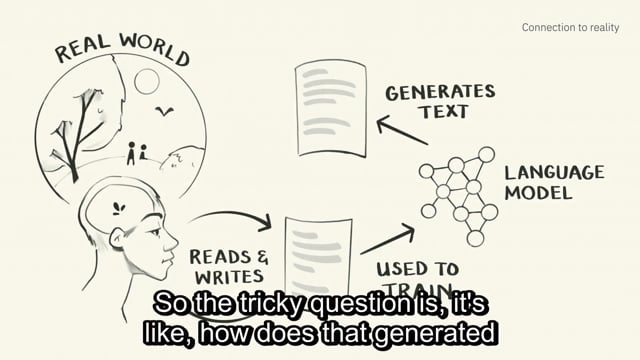
So the tricky question is, it's like, how does that generated text relate to that reality it was vaguely based on a few steps ago?
And in some sense, it's fully unhinged.
The model cannot check its claims against reality because it cannot access reality.
Even if you can take a picture of reality and show it to the model, it cannot go investigate reality in the way you can, right?
Cannot run like a scientific lab experiment if it needed to, right?
It's a bit like a fuzzy memory of reality.
It is based of what we've written about the world, but it can't validate its claims.
So we politely call this hallucination, right?
When language models say things that don't reflect reality.
It's a really smart person on some mild drugs who doesn't really know like where they are in space and time, but seems to be really good at answering kind of questions on the SAT.
The next reason that generated content is different is because of its social context, in that they have a very strange relationship to our social world.
Everything you and I say and know is situated in a social context.
Everyone here has a much higher level of technical literacy than, my writer friends or my aunt, and I'm going to talk to you very differently because I know we have a shared understanding of the world.
And we're always trying to guess the amount of shared context we have with other people we're talking to.
So people from different cultures or different times in history will have less shared context.
If I met someone from Shakespearean England, we'd speak very different dialects and we'd have very different understandings of like truth and health and science.
And I would have to relate to them very differently.
Everything is situated in our social context of what we know about the other person.
But a language model is not a person with a fixed identity, right?
They know nothing about the cultural context of who they're talking to, and they take on very different characters depending on how you prompt them.
So they are not speaking from some stable social place.
But strangely, they do represent a very particular way of seeing the world, right?
They were trained primarily on English speaking text from the web.
So they represent the the generalized views of a majority English speaking Western population, who have written a lot on Reddit and lived between about 1900 and 2023, which in the grand scheme of history and geography is like an incredibly tiny slice of humanity and possible ways of seeing the world, including ones that don't exist yet.
They obviously do not represent all cultures and languages and ways of being, and they are taking an already dominant way of seeing the world and generating even more content, reinforcing that dominance.
And we just don't have enough data from people who lived in the past or who live in minority cultures with less written content to represent them in our current models.
Hopefully this improves with time, but it's really hard to do without lots of training data and we just don't have that for most things that aren't the English speaking web.
Lastly, generated content lacks the potential for human relationships.
Human made content has the potential for you to email someone whose article you've read and get coffee with them.
We'll get a beer with them, right?
You can reply to their work.
You can become friends.
You can become intellectual sparring partners.
I've had this happen with tons of people.
There is someone on the other side of the work who you can have a full human relationship with.
Some of us might argue, this is the whole point of being on the web.
So this is a still from the film Her, which is now the canonical reference point for parasocial relationships with AI.
This is in it, Joaquin Phoenix has this wonderful relationship with his personal AI, and he talks to it every day, and he loves her, but he grows increasingly distant from the humans around him, and then eventually, the AI grows bored of him and leaves.
And some people aren't getting that this film is supposed to be a warning and not a suggestion.
Lots of services, like this one, like Replica, are popping up that give you an AI avatar to talk to.
They might be framing it as a girlfriend.
You'll notice it's often a woman with a real man in a lot of their promotional activities.
And I feel like they're maybe failing to consider the potentially unfulfilling outcomes of forming an emotional bond with an AI.
AIs obviously cannot fulfill all the needs that humans have for one another, right?
They cannot hug you, they cannot come to your birthday party, they cannot truly empathize and tell you about their experience of being grounded in the real world.
And in the same way, generated content cannot lead you to fulfilling real human relationships.
So that all sounds quite bad.
Again, deep breaths about what we're heading into.
I now want to talk about possible futures, roughly over the next five to ten years, because I'm not going to speculate beyond that.
This is going to be a non comprehensive, non mutually exclusive list of themes and trends that I think might emerge.
And a lot of these will just happen in parallel.
So the first is that I think we're going to have to get pretty good at passing the reverse Turing test.
How will we prove we're human on a web filled with fairly sophisticated generative agents?
So the original Turing test had a human talk to a computer.
And another human only through text messages.
And if the computer seemed plausibly human, it passed the test.
In the original, the computer is the one who has to prove competency.
In the new web, we are the ones under scrutiny, right?
We are the ones who have to prove that we are real humans and not agents.
This is going to be challenging on a web flooded with these sophisticated agents.
We can employ a bunch of tricks in the short term, like using unusual terminology and jargon, but We can write in non dominant languages that the models weren't trained on, and we can hopefully do higher quality writing with more research and critical thinking that distinguishes us.
But I don't know how long that will last.
The next possible future, I apologize for this phrase, but it perfectly captures the point.
I'm not going to explain it, but you can Google it later.
But we're going to enter a phase of human centipede epistemology.
The point here is that if content from models become our source of truth, the way that we know things about the world is simply that a language model once said them.
And then they're forever captured in the circular flow of information.
In our current model, the training data is at least based on real world experiences, right?
But now we're going to take that text, generated by the model, and train new models based on it.
And that tenuous link to the real world becomes completely divorced.
This is already happening.
Models are primarily trained on web text, and web text is becoming increasingly generated.
And our shared truths are already on shaky ground.
Someone recently noticed that if you ask Google if you can melt an egg, it's AI search summary said yes.
And then it turned out Google was pulling that fact from Quora, who had actually used, chat GPT to generate an answer to this question because they noticed it was popular on Google.
It's not hard to imagine how these kinds of hallucinated answers can become canonical facts on the web through this kind of ridiculous feedback loop where everyone's using a generated model to generate answers to everyone else's questions.
This phenomenon is especially worrying for the scientific community, and they have good reason to be.
We're already seeing evidence that scientific researchers are using language models to help them write papers.
This was a paper published in September in Environmental Science and Pollution Research.
Genuinely published, got through peer review.
And it includes the phrase "Regenerate response", which is the little button at the end of chatGPT, which suggests they might have copied and pasted the answer out, out of chatGBT, but we do not know for sure.
This is another one from August on fossil fuel allocation that includes the phrase "as an AI language model".
Again, these papers got past reviewers and copy editors.
They were published in real journals.
It doesn't mean the science in these papers is totally false.
Maybe the authors are using it to fix up one paragraph or two.
But because we don't know exactly what they were doing with ChatGPT, we fear the worst case scenario, right?
That whole papers are being generated without rigorous cross checking.
There are at least some people who are being transparent about this.
ChatGPT is listed as an author on at least four research papers so far.
This is in February.
So probably way more by this point.
And that's, for the people being transparent, but there is a real risk that people with worse intentions could just go ahead and create a bunch of scientific paper mills, right?
They could just use generative models to write papers that claim things that haven't actually been tested.
And usually there are findings that like benefit particular commercial or political interests.
And there've already been studies done, giving academic reviewers, both chat GPT generated abstracts and human written ones, and they can only identify the chat GPT generated ones about 30 percent of the time.
So that's a little bit worrying.
And this whole thing really takes the replication crisis to a whole new level.
So another, obvious thing that's going to happen is retreating further into the cozy web.
So right as the dark forest grows and we all go underground, we spend much less time on the open public web as it degrades in quality.
And we'll of course keep using private channels like Discord and WhatsApp, but we're probably going to have to be a lot more stringent about gatekeeping to keep our automated agents.
Like you make sure that the people you let into your group chat are genuinely humans.
It's going to be the challenge.
I think authors will increasingly put quality content behind blocks and paywalls because they're going to realize that putting it on the open web means it will be scraped by companies building large language models, which means that their ideas can be taken out of context, they can show up incorrectly in a warped hallucination, Or someone else could train a model on their writing and then use it to generate more content in their voice.
And of course none of this has any kind of profit or benefit for the authors themselves.
They have no motivation to keep their content on the open web.
And it's very possible that all the best quality writing and all the best authors will just go underground onto these private paywall things, leaving only really poor quality generated content out in the open.
We'll also see more websites with lots of content on it, blocking, scraping, and API access.
So Reddit announced a few months ago that they are effectively shutting off API access by charging just extraordinary amounts for it.
Twitter obviously led the way on this back in January, by saying it was going to cost a minimum of 42,000 a month to access their API.
We're moving towards a place where the web is not open by default.
Next, we have the MeatSpace Premium.
MeatSpace Premium we will begin to prefer and preference offline first interactions, or as I like to call it, me We will start to doubt all people online, which means that the only way to confirm someone's humanity is to meet them offline, for coffee or beer or whatever, and once you do, you can then confirm the humanity of everyone else that you've met in real life and you form a kind of trust network of people.
I think this has a lot of knock on effects.
People are more likely to move back to highly populated cities, more in person events are going to be more preferable.
This obviously disadvantages people who can't move back to urban areas, either because they have disabilities or they have young children and they can't get out much, or they're taking care of elderly relatives, or they just don't have the financial material means to move to these expensive cities.
I think this sadly undoes a lot of the kind of democratic, connective, equalizing power of the original web.
A natural follow on from this is why don't we just put it on the blockchain, right?
It's still around.
So there's a lot of people trying to create on chain authenticity checks for human generated content on the web.
This means a third party will verify your humanity in real life and then give you some kind of cryptographic key and then you sign all your content with it and then that's linked back to your identity.
This is actually a real project called WorldCoin, funnily enough, started and founded by Sam Altman of OpenAI, who might have seen what he was doing.
This orb scans your eyeball, and then uses that to confirm your identity, and then gives you a cryptographic key to go sign things online with.
Yeah.
Yeah, it's still being funded, it's still running, haven't heard much yet.
I'm also expecting any day that Elon's going to announce the new purple check that confirms whether you have your humanity or not.
I don't think it's actually gonna include verification, I think you just pay him 30 a month, and then you check a box that says I'm a human, and you're like, you're all good to go.
Okay, so those were all a bit negative, but there's obviously some hope in this future, we can fight fire with fire, Rupert actually talked a lot about this, idea this morning, in his talk mediated web, I called it the filtered web, I think mediated is a better term, but I think it's reasonable to assume that we'll each have a set of personal language models that will help us filter and manage information on the web.
So I expect these to probably be baked into browsers or maybe the operating system level, and they will help you do things like identify generated content, right?
Debunk claims, they might flag misinformation, they could hunt down original sources for you, they could curate and suggest content to you they think is better quality.
We might find it absurd that anyone would browse like the raw web without their personal language model in the middle.
A bit like how you wouldn't like voluntarily go onto the dark web.
Like we're pretty sure we know what's on there and we don't want to see it.
So yeah, the filtered web becomes the default way that we interact with the world.
This obviously has a lot of implications for filter bubbles and, increasing polarization.
Maybe there's ways to mitigate that with product design decisions, but I would not bet on it.
Okay.
We are, almost done.
One question that I want to leave everyone with is which of these possible futures would you like to make happen?
Generative AI is not the destructive force here.
The way that we're choosing to deploy it in the world is.
The product decisions that expand the dark forestness of the web are the problem.
Obviously, if you are working on a tool that enables people to churn out large volumes of text without fact checking, reflection, critical thinking, and then, publish them to every platform in parallel, please stop.
What should you build instead?
I tried to come up with three sort of design principles for building with AI, and I expect these to evolve over time, but this is a first pass.
The first is to protect human agency.
The second is to treat models as tiny reasoning engines and not sources of truth.
And the last is to augment cognitive abilities rather than replacing them.
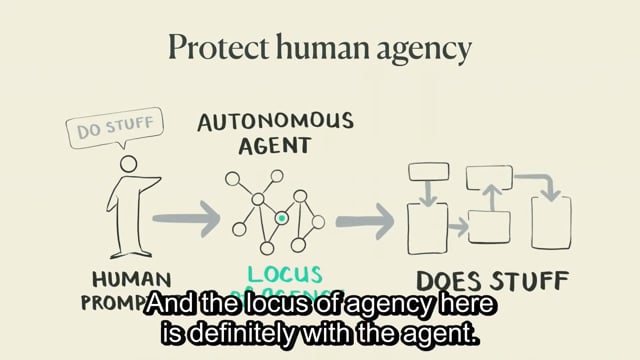
So the generative model system usually starts with a human prompt, right?
And then you hand it off to an autonomous, agent to make decisions.
And the agent like does a bunch of stuff and then reports back.
And the locus of agency here is definitely with the agent.
Right, herein lies the path to self destruction.
This is, what all AI safety researchers are very worried about.
A more ideal form of this is that the human and the AI agent are collaborative partners.
They are doing things together in very short feedback loops, this is often called a human in the loop system, and they closely supervise the inputs and outputs of everything.
And this keeps the locus of agency with the human, there's very limited power for the agent, and it's probably a little bit slower, so it's slightly more inconvenient, but it's a lot safer.
The second is to treat models as tiny reasoning engines and not sources of truth.
So at the moment we've gotten used to treating language models as oracles that like deliver us answers.
But an alternative way to see them is that instead we can start with our own data that we actually trust.
This could be databases of scientific papers, this could be our own personal notes, this could be Wikipedia.
And then we can use that data and use language models to run small specialized tasks over them, summarize this paragraph, extract this data, find comparisons, group these by a certain theme, staged a debate between two parties, and every single one of these is small enough that you can see the inputs and outputs and verify exactly what happened without it going off on these big, agentive loops.
And then you don't treat the final output as like publishable material, you think of it as a tool in the thinking process where you're constantly critiquing and evaluating those outputs.
Lastly, we should be augmenting our cognitive abilities rather than trying to replace them.
Language models are very good at some things that humans are not good at, right?
Search and discovery over millions of documents, role playing different identities and characters to help us learn, rapidly organizing and synthesizing data, and, or turning fuzzy inputs like language into very structured outputs like code.
And humans are good at things that language models are very bad at, like checking claims against physical reality, having long term memory incoherence, having embodied knowledge, having social knowledge.
And then having emotional intelligence.
And so we should use models to do things that we can't do and not, things that we're good at and want to do.
We should leverage the best of both minds, in collaboration.
So a lot of AI researchers are using the metaphor of alien minds to talk about language models, which just makes me think of this and like the chest bursting scene from the Alien flms, which feels quite unappealing as a collaborative partner in my workflow.
So I, like the metaphor of this is a new species, but I want a different one.
And Kate Darling wrote this book called The New Breed, which is talking about robots, but she's saying we should think of robots as animal companion species.
I think this is actually a much better metaphor to extend to AI.
They're like an animal species we're collaborating with.
Where we can expand and augment our own cognitive capacities, but we have to respect their unique strengths and our own.
There's also a big push for this philosophical approach of blending human and AI capabilities among people who work in AI safety research and capabilities research.
So this was an article posted to LessWrong, which I don't love, but it's an infamous site for kind of AI safety research, and it's called Cyborgism.
And it's worth a read if you want to understand a bit more about how people are trying to build systems like this.
And again, if you want to see the slides of this talk or links to any of the articles or papers I referenced, you can, go to the, this link.
It'll have all the slides and transcript.
I'm on Twitter slash X at Mappletons.
And I'm sure a lot of you think I've said maybe, something, utterly sacrilegious in this talk.
And if so, you can go try to like main character me on Twitter or just DM me nicely, whichever one you prefer.
Yes.
Thank you so much for listening.
That's all I have.
Have you noticed how the web we love is becoming an eerily lifeless place? Its public spaces are filling with a mix of bad faith actors and automated predators like bots, advertisers, clickbait attention-grabbers, and angry twitter mobs. Like a dark forest, all the living creatures are quietly hiding out of sight.
Generative AI systems are about to make this situation a whole lot worse: We now have tools that can churn out tens of thousands of words, images, and videos in seconds.
The volume of mundane, low-quality, and uninspired content published to the web is about to explode. How will we find original insights under this pile of cruft? How will we figure out which authors are flesh-and-blood humans we can form emotional and intellectual relationships with? And does it even matter if something was made by an AI instead of a human?