Scaling frontend development
(gentle music) - Hey, I'm Marcin, I work at Atlassian in Sydney, and in the next 20 minutes, I'll be trying to answer the question, how can you adapt your dev practises as your frontend codebase gets bigger, and you have more people contributing to it. So, It's not so much about the performance, like, customer aspect of the scaling, it's the scaling, the dev practises, and the people, and the code.
I'll be sharing my story of the problems we had as our codebase grew, and the solutions we came up with.
And, while every team is different, and what works for one team won't necessarily work for another.
Hopefully the principles I share at least can inspire you in some way.
For some context, I work on Jira Cloud at Atlassian, and I'll be talking mostly about my experience on the Jira Cloud Frontend platform team.
So, I don't get to make assumptions, so who here is familiar with Jira, just show of hands? Okay, most of the room.
But just a bit of context for people that aren't. It's a 15 year old product at this point.
It started life as a bug tracker.
It's kind of grown into a more general sort of workflow engine.
You can pretty much do bug tracking, software development, run a help desk, anything with it that has a workflow.
So, if you haven't worked with Jira, you can imagine from that description that it's a complex piece of software with a large Frontend surface area.
And, if you have worked with Jira, then you know it's a complex piece of software with a large Frontend surface area.
So, how big am I talking? Currently, it's about 1.2 million plus lines of JavaScript in Jira's Frontend, and so that doesn't include external dependencies, or our shared UI library that we use across Atlassian. It's just purely Javascript code and tests. In the last month, 122 different people committed code to the Jira Frontend repository, and so if you're here from a large company like Google or Facebook, then maybe those numbers aren't so huge but biggest product I've ever worked on, and it's pretty Big codebase either way.
So, briefly just a brief history of how Jira Frontend sort of got to this point. And I'm not going to take you through the whole 15 years, as I said, it's 15 years old. It's kind of like last two or three years where most of this change has taken place.
So, Jira started as a single codebase, was a single codebase for a long time.
Frontend, backend was all together in a single repository, and probably about September 2016, We split off a new repository called Jira Frontend, where there was a new feature being developed, and we took it out, and start a new repository, and we lovingly refer to what's left as The Monolith. And, there's other decomposition happening as well on the backend side of things, but I'll be talking about Jira Frontend.
And so, Jira Frontend was set up from the beginning, felt like relatively modern tooling at least relative compared to what we had in The Monolith, like, webpack, React, Redux, JS, and so on. And more importantly, it gave us, like a, decoupled sort of dev loop separate from that, that Monolith.
And, this was around the same time that Atlassian and Jira started on this programme of work that we referred to as a sort of simplification, and it was to address the complexity problems that our users face with Jira by rethinking the UX, and kind of keeping the power that's there because people do use that power.
But, also simplifying the UI for the majority use case. And so, large parts of Jira Frontend we're going to be rewritten in this repository.
So, the lines of code pretty quickly grew from like thousands to tens of thousands to eight hundred thousand lines of JavaScript, when I checked a couple days ago, just in that Jira Frontend codebase.
So, that 1.2 million that includes the legacy code in the other codebase as well. The number of contributors kind of went up in steps, as new teams started using the repository, and we're kind of at that one hundred and twentyish mark. And basically, it's now just growing pretty much everyone that's going to be using that codebase is using it, and it's just growing, as we hire new people.
Now, I just want to introduce a term, it's an overloaded term, Apps, but I'm probably going to refer to it sometimes inadvertently, sometimes on purpose. But in Jira Frontend, we refer to an app as essentially a feature. It's where we've got our top level source directory, every subject under that we'd probably refer to that as an app.
It's essentially like a self-contained piece of code functionality, and if you talked to another Jira developer, then, and you mention apps they'll kind of know what you're talking about. That sounds a lot like packages.
That's because over time, it's kind of developed into like a pseudo package structure Because of our deployment model, it didn't necessarily make sense to have like formal packages at the start, but we're kind of getting to that point, and were going to be actually splitting it into a proper, like, multi-package repo, still a single repo, but multi-package, and by soon, I mean that's what I'd been doing this week if I wasn't here.
So, the number of these Apps, or features, has kind of grown in line with the number of code. And we're up to, like, almost 70 plus, I think, almost 80 of these top level Apps. So, the first problem we ran into as the codebase grew was the problem of ownership. If you're looking at a line of code in the repository, or a file, you want to know who you can talk to about this file.
You can look at the git history, you can look at, like, the annotations, but that's going to tell you who last touched the file. It could be someone that worked on that, like, a year ago, and is no longer on the team, on the team, or with the company.
And so, we added the concept, something called a manifest. Now, this isn't a new concept, other repositories have like owner's files, GitHub has, like, a code owners feature.
But we settled on, like, a JSON file with a bit of additional, sort of, metadata that kind of makes sense in that context that Stride is probably going to change to Slack soon. So, that's really the first, the first of those principles, is establish clear ownership.
Make it really obvious, who you can talk to about a line of code.
And so, because we have this concept of ownership, we can take advantage of it, take advantage of that, that metadata.
And, as you browse around, sorry, take advantage of that metadata.
So, what else can we do with it? So, we have a bot, for some reason this bot is called Gollum.
Developer commits some code, pushes it to Bitbucket server, and makes a pull request. A webpoke fires, and Gollum receives it.
I think maybe that's it.
Like pull requests, pr, precious, and that's a bit of a stretch, but maybe that's where they came from.
So, Gollum looks at the files the pr has touched, and reads the manifests, works out the manifest for those files to work out who owns those. Then applies some rules, and potentially adds some reviewers to your pull request.
So, what kind of rules does Gollum apply? So, here is an example of a pull request with some comments from the bot.
Simple request, I did, where I touched a lot of files in the repository so it's not really a typical pull request.
But, first we have this concept of deprecated apps, where you can say that if you're working on a version two, but you're still serving version one to customers, you can say, this one is deprecated so if someone changes stuff in there, they might, they get a warning that hey, maybe this isn't the right place to be making this change. Secondly, and probably more importantly, if you touch code in an app, where you are not listed as one of the maintainers or owners, then one of those maintainers or owners will get added to the pull request.
And, this prevents that issue, where someone's made changes to code that your team owns, and it's caused a problem in production, and your team didn't even know that code had been added.
And again, like I said, this is a crazy example because I ran a code mod that touched every file in the repository, and so it's added a representative from pretty much every team. So, normally it would be like an extra one or two, depending what you touch.
So, another useful aspect of this is that for code outside of the sourcetree, so we keep all that code for doing all our deployments, and all the dev up stuff in there as well, and we'd like to know if someone's touching, touching those, for example as the Frontend platform team.
And really, the principle that is behind this kind of tooling is what we call radical automation, and essentially we kind of that's sort of pervasive across everything. If we can automate a process, then we do automate it. And, that's just one example, and I'll be talking about a few more of these as we go on.
But it kind of boils down to, what Agent Smith said in The Matrix, which is never send a human to do a machine's job.
It was a great movie, it's a shame they never made any sequels.
So, moving on, what you're looking at here is a typical sort of user experience, when you're in JIRA, you can say I'm looking at a Jira issue in the background there, it's been opened from an agility board There's some navigation on the left.
Now, in Jira, those three aspects are all worked on by different separate teams, but we have to serve that as a cohesive user interface. And, that was kind of the next problem we came across, which is that, we want to build one page from code from different teams, while letting them have relative independence of working. And so, if you consider a typical React/Redux application, which is what Jira is, you've got React, you've got Redux, your state as to your view, view fire actions, there's some side effects. The details aren't really too important, and you could apply this model and scale it to all of Jira, but it would very quickly become unwieldy, especially the state part. And, we did try this initially but it was just too hard to have multiple teams trying to contribute to a single cohesive statetree.
But, if you consider components, and component programming model for Frontend code has kind of become very pervasive in the last few years, and it doesn't matter if you're using React, or Angular, or Polymer web components, anything, this is like a typical React component, it's a button that's got an onClick handler. You can kind of get an idea of what it's supposed to do when you click on the button.
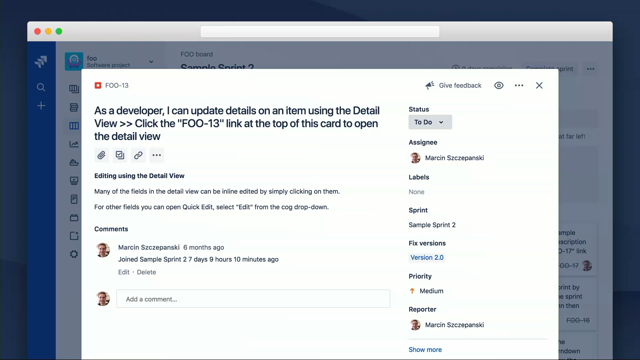
That function gets called, but there's no reason that an issue view can't be a component.
And, it is a component.
You pass an issue key, It takes care of fetching issue data, handling everything about displaying and editing an issue.
And, there are some callbacks that if you're, you, as a consumer of that issue you need to know if the issue has changed.
And so, that's the approach we took, we took that React/Redux model, but we made each of those Apps or features a separate, entirely separate application with just props as the API between them.
And so, this does have some disadvantages in that everything has to go through that prop's interface, so if IssueApp needs to talk to AgilityBoard, they need to talk through software, which contains those, and also, that there's some duplication, like, if they need to fetch issue data unless they're explicitly passing a preloaded issue between them, then they'll both need to make the same call. And, that's kind of our next, sort of scaling challenge, is rethinking that sort of architecture to allow teams to remain independent, while still taking advantage of duplication, and stuff like that.
But the principle underlining that is use composition. As I said, it doesn't matter what programming, what framework you are using, like someone said in a talk yesterday, it's, your customers don't care about what framework, what your code looks like, they just want a consistent user experience. And so, the number of apps grew, and ideal, in an ideal world, it would look like this. These little, you know, unique bundles all looking pretty similar.
But, in reality, it kind of looked a bit more like this.
That with the same general shape, but some of them are pointing in other directions, some were bigger, some was smaller, some were different flavours.
And, this really came about because teams would come up against the same problems, have the same questions but then they, within their team, they'd come up with a solution, and implement it.
And so, as you jump between apps, there will be differences in how these things were implemented, and it's not that any of these solutions were wrong or bad, they were just different solutions to the same problem.
But, we considered that overall to be a problem of maintaining consistency.
Again, that's calling back to a talk yesterday that it'd be nice to look at a piece of code, and not know who wrote it based on the code, all the code should look the same.
And so, our solution to this was a programme of work, I guess you can call it, called Tangerine. Again, there's not really much story behind the name, apart from just that the citrus theme leaves it open to other citrus related projects in the future. There's actually a backend version of the Tangerine programme called Pomelo, which is another citrus.
But, the mission of Tangerine is to build a world class Front-end through a set of agreed on, clearly documented, and consistently implemented principles. And what that boils down to for Tangerine is to decide, document, and do.
And, Ill go into those in a bit more detail. So, Decide refers to two aspects, it refers to deciding which of, deciding, sorry, what to work on, and also deciding on a solution. And so we crowdsourced the first part.
We opened up a Trello board and anyone in Jira, or anyone really could submit a problem they had, or they could submit a problem and a potential solution, and put their hand up to say they are interested in this problem space, we then have a small Tangerine committee, this is not, like, committee driven development, or anything, but we've got a committee that's representative. We've got like people from the Frontend platform team, sort of the architects, and people from other teams within Jira.
And, we also rotate people through, like, so we keep the committees small, but we give people chances to come in and out.
And so, that committee's job is to pick, sort of, the most valuable things from this problem space to work on to work out who to talk to about that problem. Like, run workshops, and things, and then come up with an actual solution.
So, not leaving the decision up to a larger group but actually just sort of working with a team, and proposing, like, a final sort of proposal. And, we refer to that as a Tangerine slice. So, there you go, with the puns again.
That's the document aspect is to basically document the problem and the principle you've come up to solve that problem.
The intention is to publish this on, like, a public website, as, like, our world class Frontend architecture. We haven't done that yet.
That will be coming soon.
We've been busy actually doing these things, and getting our codebase in order at the moment. But, the last part of it is the do.
And, this is the important part, which is the right tooling to implement these principles, and also yeah, actually get them implemented in the codebase.
And, this comes back to that radical automation thing. If you've got these principles but you don't have the tooling behind it to both enforce those principles, and automate, and create low friction ways of actually applying these principles, then they're not going to get done.
They're going to get ignored, or if you depend on people in pull requests manually looking at code, and saying hey, that's not, that doesn't agree with the principle, then yeah, things are going to get missed.
So, I'm going to give you some examples of two extreme opposite spectrum of the kind of things that we have come through Tangerine. The first one is extremely trivial, so just bear with me, while I explain it.
Some code had a blank line after the flow annotation, and some didn't.
And, this seems really trivial, But you know, if you want consistency you got to have consistency, and don't get me wrong this isn't something that the whole committee spent weeks, like, deliberating or anything.
This was just someone that said this is a problem, I think we should do it like this. Spend like 15 minutes just writing it up, and everyone just said Yeah definitely.
Let's go with that first one, and he wrote me a ESLint rule that's auto-fixable, and implemented it across the codebase.
Now, because most people run an editor that does autofix on save, or they run a pre commit hook, just means that you just write code, hit save, and the annotations, how it should be, or how we've decided it should be at least. Now, on the other end of the spectrum, and this is the controversial sort of aspect, is we've got this app structure proposal, which is, we are very opinionated on how you should structure your files within an app, how you should name things, what the different layers are, but essentially anything that doesn't directly relate to the feature you're writing.
We have these strong opinions on, and yeah, like I said, this can be quite controversial, but once you got that tooling in place, and once you can create and maintain that structure with tooling, then for social, for both creating, and enforcing it, then it's one less thing, or a set of things, that as a team that's trying to ship features to customers you have to worry about, or think about, or make decisions on.
And really, that's the principle that kind of underlies the whole Tangerine thing, is be opinionated.
And, like I said, by being opinionated about the non feature aspects of the codebase means teams can focus on those features.
And, obviously, innovation is still encouraged, but you have to take care of applying sort of new ideas to an eight hundred thousand line codebase.
Teams are free to try something new, but then if it's something they think is valuable, then they should sort of go through th sort of Tangerine process, and get it formalised, and then everyone can take advantage of it, and we can do it in a consistent way.
So in terms of the tooling, and that's really what helps us maintain those opinions.
We've got the standard stuff that's like ESLint, Flow, Prettier.
And, we've written some like 50 plus custom ESLint rules, and so, yeah, to help implement those principles. And, most of them are auto-fixable, which means you can write code, and hit save, and your code looks like it should.
And, what was I going to say, so these custom ESLint rules, most of them are on that level of, that simple, you know, should there be a blank line here or not. Just some, like, small examples of some of the rules. So, we've got import ordering.
Again, I think there's third party rules for this, but I think at the time we decided on this import ordering, they didn't support auto-fixing, or something along those lines.
But yes, essentially, you get your absolute imports then you've got your local imports then your relative imports.
We got like a rule that if you've got React/Redux connect higher order component, if you've got like mapstate to props, that should be called mapstate to props, and things like that, and restricted imports is kind of an interesting one, like, there's Atlassian wide analytics library.
And, it's a dependency of the project so you could import it and use it.
But, we want to add some Jira specific stuff to it, and so we want people to go through a wrapper, when they use it.
And so, we've got a rule that says you can't import the analytics library directly in your code.
You have to use this wrapper.
And, you get, that one's not auto-fixable but you get a warning.
And, in terms of the other tools, we've got something called Stricter, which is something we built but it's open source. And, this is kind of like ESLint, but at the project level. So, where ESLint works on a file by file basis, Stricter rules can see the whole sort of project structure, and this is what we use to write rules for enforcing things like that app structure I mentioned, and other things like making sure every file in the repository has an associated manifest, and things like that.
And then finally, because we've got all that, all that consistency, sorry, because we've got all that opinionated, all those opinionated principles around how you should structure things, and we can take advantage of tools like Yeoman to provide generators for people writing code in Jira Frontend to generate whole apps, or generate a view, or part of an app, just based on, just a few prompts, and it'll automatically sort of, out of the box meet the rules, pass ESLint checks.
And so, how have we gone in terms of that consistency, it's looking better, like, you're always going to have bigger and smaller apps, I guess.
There's always going to be slightly different flavours, but generally, everything's kind of now pointing in the same direction, and that's pretty good. So, just to recap on the principles I talked about, and so, the first one, establish clear ownership, definitely as your codebase grows, and you've got people that don't sit next to each other necessarily, or working on it.
It's really important to have that defined ownership to be able to tell, who is responsible for a piece of code.
Secondly, embrace that component model.
It's probably been the biggest change in the last couple of years in Frontend development, is using components, and be opinionated.
So, this is where I, this is the one where, which is why I said at the beginning, what works for one team might not work for another because if you're just starting out, there's probably no point being super-opinionated about things, you're only just going to bog yourself down. You probably want to move fast as a small team, and work out what you actually want to be opinionated about, once you've grown a little bit.
And, lastly is that concept of radical automation, which is, don't send a human to do a machine's job. Sorry, yeah, don't send a human to do a machine's job. If you don't have tooling in place to enforce the rules you decide on for your code base, then they're not going to get enforced, or they're going to get enforced inconsistently. And that's kind of the key part.
So, yeah, these are currently our principles. They've kind of gotten us to this eight hundred thousand lines of code.
Will they get us to the next eight hundred thousand, they'll probably evolve over time.
But, that's where we're at today.
Thank you.
(crowd applauds) (gentle music)
Atlassian Jira’s has a new frontend codebase that is “only” 18 months old, but already contains over 50 top level “apps” and 400,000+ lines of JavaScript code, from almost 200 committers. The problem was that with 50 apps we had 50 different approaches to how to build a frontend application.
We needed to scale our development processes, so in late 2017 we embarked on Tangerine – a program to standardise principles that define a world class frontend application as it scales up, and apply this to Jira.
Tangerine provides the framework for principles that make up a frontend application to be “decided, documented, and done” – all supported and enforced by tooling and automation, and published for the world to see and learn from.
Learn about our journey with Tangerine so far – good parts and bad, our vision for Jira and beyond; as well as the program structure, processes, and how we’ve used this all to take a backlog of ideas and progressively work them into concrete proposals, and have them implemented in Jira.