On the Cutting Edge: a Glimpse into the Future of Web Performance
He - low everyone.
See what I did there?
Performance on the web is really, really important, especially because we don't like our videos buffering and our shopping websites taking forever to load.
So today I'll be talking about not only why it's important, but also how we can solve web performance and especially the role that the 'Edge' is going to play in the future of solving all of these problems.
So the standards for performance are really, really high today, right?
And they feel nearly impossible to achieve.
We all want those sweet one hundreds across the board Lighthouse scores to get as many users as possible, to improve retention rates.
You know all of the reasons that performance matters, but that doesn't make it easy.
In fact, it's really, really hard.
So, well, what makes it so hard?
Even answering the question of what makes it hard or how to even measure performance reliably is really hard.
At CloudFlare for when customers report any sort of performance degradation, we have an entire process around triaging it.
Because how you measure performance alone is really important to the results you get.
And then from the moment that a person's eye perceives how the browser loads their website through the network, to the server, there are so many different things that can go wrong.
Today, in particular, we'll be focusing on things that can happen around the network and solutions to that.
Even at the network layer, there are a few different ways in which performance can be degraded - from routing to, depending on the protocol that you're using and how efficient it is at transferring information.
People keep blaming things on DNS.
So we can throw that one out there too, right.
But to really frame the problem of web performance and where you can get the most bang for your buck, I think it's really helpful to go through this little thought experiment: So given an unlimited budget, could you transfer data from San Francisco to Melbourne in less than five milliseconds?
It seems like with an unlimited budget you should be able to do well just about anything, right?
Fortunately, it's not so simple.
So the distance between San Francisco and Melbourne is 12,650 kilometers.
Our culprit here that we're battling against though - and that's just as fast as humans have been able to get, or the fastest thing that we've been able to measure - is the speed of light.
So the speed of light travels at 300,000 kilometers per second.
So even if we're traveling as quickly as we possibly could, we would get from San Francisco to Melbourne in 42 milliseconds.
So unfortunately, even with an unlimited budget, it doesn't seem like 5 milliseconds is a feasible goal.
So the thing that we're really up against here is the speed of light.
And if we can't improve on it, then we need to think about ways to work around it.
And even that 42 millisecond measurement is really, really optimistic.
I like to think of the internet as having its own weather and geography, really.
So in the time that you connect to a server, even there, there are so many things that can go sideways from ISPs being congested, to literally actual weather knocking a cell tower over, right?
And geography itself is not very straightforward either, even though you might be near a data center that you think you would connect to, routing may end up taking you through another ISP, depending on who the provider peers with and the ISP that you yourself are connected to.
So all of this complicates the matters quite a bit, which is why, even though with the speed of light, you could get through that distance in 42 milliseconds, in reality, the average latency of just a single ping from San Francisco to Melbourne is around 171 milliseconds.
You might get routed around it.
It's a long distance.
There's a lot that can happen.
So the obvious answer is: if we can't beat the speed of light and go faster, well, maybe we can just travel shorter distances, right?
And if you have a user in Melbourne, hopefully they can connect to a data center that's right there.
So if your data center is 45 kilometers away from you, less than even 1 millisecond should be possible.
We figured this out quite a long time ago, but there's been an evolution of getting content closer to the actual end user.
So I'm going to talk through that evolution a bit.
The first generation of getting content closer to the users has been the traditional CDNs, right?
For static assets that rarely change, like images or JavaScript, once you've traveled all of that long distance once, we realized for the future users, you don't necessarily have to do it again.
You can hopefully serve them from the nearest location on any subsequent request.
There is another iteration of that.
So, it's one thing to say, "I want to blindly cache everything", but as we know, one of the hardest problems in computing is cache and validation.
So you want to be very specific about the things that you cache, and there's additional logic that you might want to move up to the Edge or closer to the user itself.
So there are different ways of doing this.
I can tell you at CloudFlare, the way that we started out getting into the business of having more rules or more logic at the Edge was by running this thing called EdgeSight code, where literally engineers such as myself are teasingly crafted a little snippet of code in Lua for every single customer that needed a custom TTL on an asset, or if they wanted to do a Geo redirect, but eventually the industry has reached the same conclusion.
In order for people to be able to fully express themselves on the Edge, they needed to be provided the capability to - well, how do developers express themselves?
- write code or logic there.
So the third generation is where the network itself is actually becoming the computer, allowing you to run Turing complete code and have access to storage, which we'll talk about in a bit as well.
So a few of the solutions out there that adhere to this model are Cloudflare Workers, which I'll talk about today since that's the product that I work on, but there are other similar solutions out there like Fastly's Compute@Edge, which allows you to run WebAssembly on the edge.
And AWS has recently released CoudFront Functions.
So, how are we able to achieve this?
Since we don't have massive data centers in the way that centralized compute does, where there are massive server farms that are able to fit in as many large virtual machines in them as they can.
The edge by comparison is really small.
When you're distributing code to 200 locations around the world, each of those locations can be pretty small - as small as sometimes a few servers.
So even though these solutions all work differently under the hood, they do have a similar component behind the scenes, which is, it relies on the isolate model.
Isolates, unlike Virtual machines are really, really tiny.
And what allows them to be really tiny is that the only thing that customers have to bring is the application itself.
So previous models, like a virtual machine, for example, the host only provided the hardware, everything else you had to bring yourself - the application, the libraries, the language runtime, and the operating system.
So for a VM to start up takes a whole bunch of time and it's really hefty, right?
It has to store an operating system for every single copy that it has.
An iteration and improvement on that, were containers, where you can have a single layer of the operating system, but you still have to bring an entire language runtime with you, which is what leads to the gnarly cold starts that you hear people talking about.
But for us, since we're running code for customers who are looking for performance improvement, you don't expect your CDN to take a few seconds to start up every time.
And so by running in the isolate model, we're actually able to provide the runtime itself and only bring in and spin up the application code every single time.
As a product manager, the first question I have whenever someone is talking about the technology is what are the use cases?
How are people using this?
So as far as stateless use cases on the edge go, and these were the first use cases that we started seeing as we put this in people's hands, a few of them include content personalization.
So whether we're on cookie, geography or weather, if you can inspect the request and serve customized content to the end user, they're obviously going to have a better experience.
Another example is A/B testing and traffic splitting, which I will dive into in greater detail.
Even simple things like header manipulation if you are maintaining a bunch of different origins or have wildly different assets that all need customization.
Managing that through code can be really, really helpful.
Another really great improvement has been authentication on the edge.
So previously, if you authenticated content at your origin, it would be really difficult to scale because it meant that content that had to be authenticated couldn't be cached, but by being able to run logic at the edge, you're now able to authenticate it right there, where it's already cached.
which means that's all load that's taken off your origin and better performance for your customers.
And this is especially important because it impacts paying customers, right?
Who paid for the content, and now they're able to have it be served through a cache version.
Bot mitigation or letting only real users through, through smart identification can even trick bots into wasting time on your website, right?
Since you can be really clever around the things that you put there.
And lastly, if you have an origin that has a rigid CMS running on it, it just gives you so much more control over it.
So let's talk about why it's so beneficial to run these things on the edge.
I think A/B testing is a really great example of that.
So going back to our original diagram, we have the browser, the network and the server.
Now A/B testing started as something that would run on the browser, but here it encountered a really big problem called render blocking, whereby every single time you would access it, the rest of the assets before they were loaded, they would have to wait to solve a previous problem that was encountered through a flicker problem or inconsistent experiences, right?
So you would load the webpage and it would load in green.
And then as the experiment kicked in, it would turn into blue, which would impact your web Core Vitals right?
That's exactly what we're talking about here.
Things like your Time to actual interaction or consistent layout shifts.
Running it at the server also has its own problems.
It's far from the user, which means that it impacts the latency.
It's also harder to update.
So if you are the A/B testing framework itself, you have to rely on the developers updating your SDK consistently.
And so, whereas the first - whereas running it at the browser impacts the experience metrics running in at the server impacts your Time to First Byte.
And this is where the network is really the best of both worlds, right?
Because it can be fast since it's running close to the user, it's easy to update and it can provide a consistent experience right out of the gate.
So let's walk through what an example looks like in code in real life.
Let's say I have an experiment that's running, and it's called experiment zero.
So here, I'm going to define it and I'm going to have a test response and a control response.
And the first thing that I do here is I'm going to inspect the cookie and see if the cookie for either experiment has been set.
So, if it has, then I can control the control response, but if it hasn't, then I can return the test response.
There are also many different things that we can do to iterate on top of that.
For example, this allows us to send logs somewhere that let us know who encountered, which example or rewrite the HTML on the edge, through the different experimentation.
So here, I'm going to introduce you to a couple of different APIs that are really handy when running operations at the edge.
And I can just show you an example of how it works here.
The Cache API allows you to write data directly into the edge cache.
So here, the first thing that we're going to do is define a cache key and the cache key - the way that we're going to look at it is through defining it as a request effectively.
We're going to create a new cache-is instance.
And when a request comes in, we're going to check the cache-is instance to see whether we get a match on the cache key or not.
If there's not a match, then we have to generate a new response.
In this instance, we fetch it from the origin and then we adjust the cache control and put it in the cache so that it can be fetched and matched on next time.
But another thing that we could do is run computationally expensive tasks on it, where we don't have to run that computation every single time, because we're able to store it and put it in the cache.
Speaking of computationally expensive things: One other really useful API to have at the edge is the HTMLRewriter, which is a streaming, HTML parser that's available to you directly at the edge.
The streaming means that it doesn't have to parse through the entire HTML at once before it starts returning any bytes back to the client, it can do so on the fly.
So here we have an example for using the HTML rewriter for internationalization -where I look for an element and see if it has the data, 'i18 nkey' for the internationalization.
I fetched the content from a predefined 'countryStrings' cache table that I have, right?
And then I sent the inner content of the element to the translation, through the HTML rewriter API that provides this functionality for me.
In here as a next step, you can see that determining the language of the request through the language header, which is the 'accept-language' header, then I am grabbing the asset from my key-value store, which is a type of storage on the edge that we will again, dive into in a bit, and then I'm able to call a new instance of HTMLRewriter to handle the response and transform it with the new translated string.
So these are all stateless use cases.
And if you thought that stateless use cases on the edge were cool, wait until you hear about state on the edge.
So you have a couple options here.
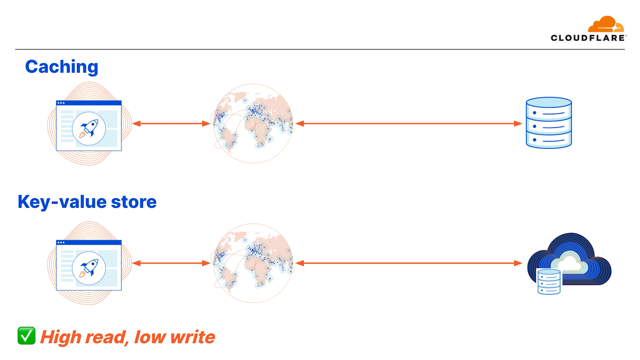
One that we talked about is caching, right?
And here you have a lot more granularity and control than you ever had before.
You're able to move the content itself closer to the user.
So assuming that it's already there, that leg is going to be fast, but the leg that's always going to be slow is the connection to the database or to the origin itself.
One option that Cloudflare provides is also a key-value store.
Similarly, it has a few locations around the world where it's storing the content so that you don't have to worry about configuring or setting up an origin, but it still relies on you caching the content and it's really great for high read frequency and low write frequency.
So once I write a configuration, like an A/B test variation, everyone else can read from it really, really quickly.
But if I'm updating a value such as a counter, the synchronization doesn't allow me to get the outputs that I want as quickly as I need to without incurring additional latency.
But even here we've had really fascinating innovation.
So a really new model of thinking about this, that Cloudflare started out with, but we believe others will adopt as well, is called 'Durable Objects'.
So what's really clever about durable objects is that in reality, data doesn't need to exist in every single edge location at all times.
For example, if I have a user profile on some website, I'm probably most frequently accessing it from a single location.
So for me, it's from San Francisco, or maybe if I'm traveling around my location might move around, but still I'm only accessing it from one place in time.
Maybe someone else will access it as well, but there's almost always a single most common point of entry.
And so what durable objects do is they define the location of the object per the object and move it around depending on what the access patterns are, allowing you to have the fastest performance possible while also being able to maintain the right guarantees that users need.
While today you might still need databases in order to run fully fledged applications in the edge.
We're iterating on this more and more, and this is going to become an increasingly viable option for running applications.
So, what's next?
I alluded to this a bit just earlier, right?
But, well, this is the diagram that we're so used to where there's the browser, the network, at which level you can do some things, and the server.
With things like durable objects, what we're trending towards more and more is eliminating the server and having the network become the server itself, with capabilities around running the actual logic of your application and storing the data for your users in every single edge location, and being able to provide that really quick latency to every single one of your users.
And again, when we're talking about hundreds of milliseconds, rather than micro - measuring the micro benchmarks on your server that vary between zero and 5 milliseconds, this is where you're able to actually get the most bang for your buck by not beating the speed of light, but running applications even closer.
There's one more thing that I want to point out about this model.
One type of performance that we talk about that we're all here to talk about today is the performance of web applications or applications themselves, right?
But another type of performance that matters a lot is the performance of your engineering teams.
The way that engineering for the most part works today is that you have to develop an MVP, right?
You develop it locally.
You then have to deploy it to a particular region that you choose.
Then, if you want to service millions and millions of users, you have to scale this, righ?
And you have to also pick and choose where the users are that are most important to you, literally from the very first decision that you're making.
When you're deploying an application on the cloud today, it asks you: "What region do you want to run on?" Or "Which users do you care about the most?" And then you have to spend time optimizing it, making it faster, through caching, through improving the performance of your application.
What's really powerful about this model is that it turns all of this into a single step of just deploying your application from "Hello, World!" to millions of users around the world.
That way every single user is able to get that 100 perfect Lighthouse score without you having to spend any time optimizing it.
Applications should be really fast out of the box, and we're already starting to see applications trending in that direction more and more.
By spending less time optimizing and more rethinking the entire way in which we're deploying applications given what we now know about how the internet works and where those really big long poles are, that are degrading our performance.
So, thank you so much for taking the time to think about the future of performance and hopefully I'll see you on the edge!
Cloudflare Workers enables deploying a serverless application instantly, from a developer’s computer to the edge – as close as possible (tens of milliseconds!) to every internet user around the world.
This is made possible by running V8 isolates – the same engines powering Chrome, on Cloudflare’s global CDN network, spanning 194+ data centers around the world. For end users this means blazing fast, always available applications due to the reduced latency of requests traveling around the globe, and no cold starts, due to the lightweight nature of isolates, as compared to containers. For developers this means more time spent writing code, and building features, rather than scaling and optimizing cloud configurations.
This talk will cover the landscape of what platforms offer at the edge today, and how edge-based serverless is changing the web stack: from incremental dynamism at the edge, to the evolution of JAMstack on the edge and beyond!
API Links:
HTMLRewriter
Cache
Associated links:
AW CloudFront Functions
Fastly Compute@Edge