Designing for Voice: Alexa, Google Assistant, and beyond
(upbeat synthpop music) - Hi, my name is Darla Sharp and I'm absolutely thrilled to be here.
I love talking about conversation design, and so anybody who'll let me do it exclusively, it's really exciting (laughing).
So thank you for having me.
Today, we're going to talk about crafting conversation, also known as design in the age of AI.
As you guys all know, virtual assistants are a force in product design these days, Amazon's Alexa, the Google Assistant.
And while I'm sure almost all of you have experience designing for screens, I'm guessing most of you don't have experience designing for voice.
And so I'm going to talk, today, about what is conversation design, what does it look like, why do we do it, and then, also, why it's so deceptively simple but actually really quite complex.
So we'll get into some of the nitty-gritty with that as well.
OK, so as John mentioned, I have worked at other companies on virtual assistants, but I currently work at Google.
I work in Mountain View, California at the Googleplex, deep in the heart of Silicon Valley.
If you haven't been there, but you seen the show Silicon Valley, yes, it is actually exactly like that.
I had to stop watching it because it's actually quite painful to see a parody of your own life.
(audience laughing) So I had to, like, step away from that 'cause it was, it hit a little too close to home, but it's actually quite realistic.
I work as a conversation designer.
This field has several names.
You can also hear it being referred to as Voice User Interface designer, or VUI, V-U-I for short. So you'll hear about VUI designers this, VUI designers that. Voice user interface design, that title is the, it's corollary to Graphical User Interface design. And so, often, where you have VUIs, you talk about GUIs as well, which is just this strange acronym world we end up living in where we talk about VUIs and GUIs.
Also, just voice interaction designer? I mean I'm just, I'm an interaction designer at the end of the day. It's just with the emphasis on voice.
These terms all get used interchangeably.
So if you hear, at one company, they're called conversation designers, at another company they're called VUIs.
It's all the same thing.
So I currently work on the Google Assistant. And I don't know how many of you caught Sundar, the CEO of Google's talk at I/O last year, but he talked about how Google, as a company, is pivoting away from mobile-first towards AI-first, which is a really big shift in the paradigm of the company. And what this means is they're investing a huge investment in the Google Assistant world which is a virtual assistant whose goal is to help you throughout your day and be able to access Google's information with the ease of your voice.
And we'll talk more about what that means.
You probably best know the product line for the Google Assistant by this cute little air freshener, right here (laughs), which is the Google Home speaker.
Although, the Google Assistant is now available on a variety of devices, all Android devices, particularly the Pixels which you see there on the left, the Buds, the Google Mini, the Max.
The product line is growing all the time, most recently with the one that was announced at CES in January, which is the Google Smart Displays which won Best of CES 2018 by Engadget which was particularly exciting for me because that's the project I'm working on currently. So the Google Assistant's got a bunch of different products. This one was announced in January.
It should launch later this year.
It's basically the same Google Assistant, just, now, we get to leverage the screen to augment the information that she's delivering. OK, so let's take a step back here for a second and talk about how this fits into the larger ecosystem. Voice-forward interactions are growing and they're growing really fast.
The most simple way that this use got, was used for a very long time was even just transcription, right, so sending an SMS via voice or doing a Google search, but tapping that mic on the far right side to do the search via voice rather than typing. So the question, now, is like, well, why? So it's growing and we've seen these limited use cases as John had mentioned.
Like, there's a great promise for voice, but what's the point when we all have a smartphone four feet within our radius at all times? So why do we need this additional modality? First of all, it's speed and simplicity.
So any of you, if any of you have used the Google Assistant, Amazon Alexa, any of these, you realise how much faster it is to access this information via your voice, even though you have a smartphone.
So do you need to do it without your smartphone? No, but once you try and you see how much faster it is, it becomes very, very addictive.
And then the thing that happens after that is if it fails and you have to take out your phone, you're like, ugh, gah, now I guess I'll take out my phone. And it's pretty amazing how fast that goes. So even in comparison to the phone, let's play a little game of, about how many taps would it take? Right, how many taps would it take to do the following? So this is a pretty straightforward example, right, 15 times 24, not something you could probably easily do in your head if you're me.
And so let's take like for, best case scenario, you've got an iPhone, you have to unlock, you have to swipe up the quick tray.
You've got to find which of those fairly ambiguous grayscale icons is the calculator. You find the calculator, you type it in.
You know, that's at least five taps, six with the equals, and then you have the information, right? Again, not impossible, but that's actually quite a few steps when you think about that.
So then, the next one, let's say, play the latest album by Gorillaz on Spotify, something that you can just say.
But if you needed to do it on your phone, now you have to go into the Spotify app, you have to search by artist, also by relevancy, sort all of the albums, and then play the latest one, something that's actually really quite easy to do via voice. And these types of things are really what voice assistants, in their current state, are pretty good at it, right. These are pretty simple tasks.
They're not something too complex, but they are way faster via voice than when you use your phone.
And then there's this example, any direct flights to Denver next Sunday? So even though the internet has existed for decades now, this is an interaction that has stayed the same pretty much the entire time, which is that you manually have to enter your origin, your destination.
You need to filter, now, by, no, I don't want a flight path that's 20-plus hours. So this is something that, for example, is pretty fast to do via voice.
So speed and simplicity actually have a lot to be said for as being something that's leveraged in this area. Now, there's also ubiquity.
So your phones are ubiquitous, for sure.
They're everywhere.
The internet's everywhere.
You have your phone with you at all times.
But now there's something very cool about these virtual assistants in that they're now spread and quickly spreading throughout, different modalities that are spread out throughout your day, right.
So you shouldn't be using your phone in the car, right? You shouldn't be using your phone in the car. But, with the tap of a button, using just your hands and keeping your eyes on the road, you can now access the same information that you may access in your living room through the speaker or walking to the train in your headphones. And this is actually pretty amazing once this ecosystem starts growing stronger and stronger, which is that this ease-of-use isn't just something that you can access in one place.
At least, this ease of use is something that you can access everywhere.
OK, so that was kind of just the context of like why this is relevant for us today and why these important points are just gonna grow stronger the more pervasive these voice-forward experiences get. So let's talk tactical design considerations for a while. This is where we get kind of more into, what is voice design and why is it complex? So first, the first one is modelling conversation. So what is conversation design? I'm gonna tackle this initially from a linguistics standpoint, which is how I got into this field.
So conversation designers can come from a variety of backgrounds.
Some, most often, come from linguistics, right, where we've studied, what is language.
How do users assemble it in their head? What does it mean to break it apart and put it back together again? There's a lot of tactical knowledge that's involved with studying linguistics that gets applied to conversation design.
But that being said, that's not the only way. You can get into this field and/or be successful at this field.
Some people come from more of a psychology research background, which is also very helpful.
And then there's also just, you know, standard interaction design.
If you work in a product that's heavily complex with information hierarchy, information hierarchy plays a lot into conversation design, and so those skills can be leveraged here as well. But first, let's talk a little bit about linguistics. So this pyramid represents human language understanding in the way that you process language everyday, all day, right now.
So as you are listening, you assess speech sounds, combine them into words.
Speech sounds like morphemes, right, those morphemes get combined into words.
In your head, as you're hearing these words, you're processing the phrases and sentences and assembling them into syntax, right.
Syntax doesn't necessarily mean like, your sentence has a certain correctness about it. It's more just, how is it assembled and is it assembled well? Once you've got that sentence, you derive meaning out of that.
That's when you, for example, can resolve discrepancies between their and they're, like there as in the possessive versus over there or herd like a herd of animals versus I overheard something.
Semantics is where you derive meaning out of those sentences.
And then pragmatics is where you interpret that meaning in a larger cultural context.
So a lot of this is really easy if it's your first language and most of it is instinctual, which is why, for the most part, I'm guessing, most of you think this seems really obvious because most of this is something we do without even thinking about it, right.
While this seems very obvious and easy, it's actually incredibly fragile.
If anything breaks down at any point of this, then the whole thing, the whole interaction can break down. So think about when somebody's said a word funny (laughs) and it's totally distracted you or when maybe a speaker, that this isn't their native language, accidentally mix up the verb and noun agreement and how that kind of maybe confuses you for a second. Or like somebody who may be just culturally unaware is using language that's inappropriate and how disorienting that can be.
So while this seems super obvious, it's actually really fragile.
I had, like, a really quick example with this the other day. I was, we got a ride from the airport and I was asking the driver, like where in the city is my hotel and he said in the, "it's in the CI-ba-dee." And I had no idea what he was saying (laughs). Like, and then, and I was like, it's where? And he's like, "In the CI-ba-dee." And later, I had to Google it and figure out what he was saying, but he was saying CBD, (audience murmuring) in the Central Business District.
And that, like, it broke down at the very top of the pyramid and we were both speaking the same language. So like, this is an incredibly fragile system and it's why, a lot of times, when you're using these virtual assistants, when something is a little bit off, it seems quite wrong. And because it's instinctual, you don't necessarily learn what's happening here. It's why when you're talking to a virtual assistant and it doesn't sound quite right, all you can really think is, that sounded weird. And you can't articulate why, right, because it broke down somewhere around here and you aren't processing these as distinct times in your mind; this all happens at once in your brain.
And that's why it's really hard for voice designers to get valuable feedback.
Because, a lot of times, users are like, that was just weird, that was wrong.
OK, so let's talk about how this breaks out with conversation design.
So there's a misconception that conversation design is just writing prompts, that we're kind of a variety of a UX writer, when we're actually having to do much more than that. So if you think about this pyramid, the front end are the words and syntax.
That's what you hear from the Google Assistant. And then the back end is all the semantics and pragmatics that we have to keep in mind in order to be able to generate what we hope is an appropriate response to your question. So the back end ends up being logic and UX flows and this is predominantly where we spend most of our time. This is how to make the cake, that's how to frost the cake (laughs), but all people see is a pretty frosted cake and they're like, oh, you're so good at making frosting. (audience laughing) It's actually, the majority of our time is spent in this area.
So note, now, what does that mean? How does a back end UX flow correlate to semantics and pragmatics? So this is, what can we do on the back end? Which API calls do we have? How much context about the user do we have? Do we have what they just asked about? Do we know who they are? Are they younger? Are they older? Do they, have they asked for this before? And therefore, maybe we can give them a shorter response. What is very deceptive about conversation design is how much the bottom part influences the top part and how much we're working really hard to compensate for things we can't do on the back end, right. So our back end is fairly limited and is growing every day as far as the powers that we're gonna have to make contextual responses to the user, but we're having to do a lot of decisioning to try and hopefully make what's the appropriate response on the front end. And that's very subtle.
So if you look at the question, what's the weather today? The response is, in Alameda today, it's 72 degrees and sunny, which means we have the user's location.
Right, Alameda, that's where I live.
It's 72 degrees, that's an appropriate way to describe temperature for me, right? And, it's sunny, and that's all I need to know, right? But if, that means on this side, there was a decision. Do we have the user's location? Yes, OK.
Preface that at the beginning of the sentence. If we don't, then we have to go down a whole 'nother part of it.
What's really tough about conversation design is the happy path writes itself and everybody's like, oh, that's super easy. And it is; the happy path writes itself.
It's the no side of that logic tree that ends up getting really, really complicated and really tough and that's where we spend the majority of our time. Because that's where we spend the majority of the time, the paradigm is actually flipped for us.
We spend, first, almost all our time's trying to figure out, what can we do on the back end? What APIs can we leverage? What back end calls can we leverage? What user-contextual information can we leverage? And then once we've got all of the decisioning points, then we go into the front end, which is the syntax and words, and we write the prompts for what the assistant should say. What's also, I mentioned this briefly before, but this pyramid also represents, like, how much time we end up spending on these things. So the back end is what we mostly spend our time on and then the front end is what happens at the end. And actually, that stuff is actually pretty quick to write once we've got the appropriate context.
OK, so part, we talked about human language understanding as far as how we process information, but then there's the cooperative principle which is rules that we innately know that we use to be good, like, conversation allies, right, and this is called the cooperative principal. And the cooperative principle involves four different aspects: quality, quantity, relevance, and manner.
So each of these is, again, seemingly obvious. Why do we need to talk about something that seems so seemingly obvious? Well, one is these are the things that go wrong (laughs) when you talk to a virtual assistant and it doesn't seem right.
When it doesn't seem right, it's because it's violating one of these things that we just know to be true, right.
We know that if you're being cooperative in conversation, you'll align yourself with these four principles. So quality, quantity, relevance, and manner, I'm gonna go through each one of these and give you an example of the Google Assistant doing this wrong.
The Google Assistant is a huge platform.
Armies of people are working on this platform and there are only so many designers.
You guys know that as well as anybody.
We tend to be one of the under-indexed areas of product. And so there's way more engineers than there are designers which means things get through on this platform without us having looked at it, all of, for every single thing, right.
It's just a statistical truth.
So while the Google Assistant did say these at one time, she doesn't anymore (laughs).
But this is an example that I've grabbed of times in the past when she has violated these principles. And you'll see that, when you hear these, it sounds very strange.
So the first one is quality, which means that it's appropriate for the context. This assumes that we're using a shared paradigm for context. And here is an example of the Assistant violating that. - [User] OK Google, open Uber.
- [Google Assistant] I can't open apps.
- OK, it seems like kind of a strange response, right? The user said, "Open Uber," because they know that the Assistant has a capability of calling rides from Uber.
The mental model may be an app, so they're gonna say, OK, open Uber.
The Assistant can't open apps on your phone , which is what she was responding to.
"I can't open apps." The user wasn't asking for the Assistant to open an app on their phone; they were asking for the Assistant to open the action on Google.
And this actually violates a couple of the principles, but definitely the one for quality, which is that this just wasn't, she wasn't, we weren't asking for you to open an app on my phone. I was asking for you to open an action.
Quantity, this is as informative as required. So this is both, neither too little nor too much, right? It's as informative as required.
This is a real response one of our conversation designers got when they asked this question.
- [User] OK Google, how many propositions are on the California November ballot? - [Google Assistant] 14 of the 17 measures on the ballot in November 2016 are citizen initiatives. Voters decided three initiatives in 2014, 12 in 2012, and 11 in 2010.
There were 15 citizens initiatives on the ballot in 2018, which was the last year that this number was higher than 14. (audience laughing) - So definitely not as informative as required, right? It was a pretty straightforward question.
We're gonna to get into this a little bit later, but this also touches on what happens when you port from one modality to another. Oh, my computer fell asleep.
So in this case, if you Googled that information, you probably would have gotten that slice from Wikipedia or something along those lines.
And it was ported straight into the voice-only experience and is obviously totally inappropriate now. And we'll get into like the fallacy of porting, which is like, I think, gonna be the the name of my autobiography.
We'll talk about the fallacy of porting later. OK, and then relevance means that it's unambiguous. So here's an example of that.
- [User] OK Google, what was that last song? - [Google Assistant] Here is some information about the last song.
Estranged from her father for a number of years, teenage Ronnie isn't pleased when her mother ships her and her younger brother down to a southern beach town to spend the summer with him. - So clearly, there is is a movie called The Last Song. They asked, what was the last song? You get a synopsis of the movie which is incredibly ambiguous.
And you had to work that out in real time, right, 'cause it seemed like she was answering the question at first.
And then, finally, it's manner which just means you're not like lying, that what you're saying is true.
And here's an example of that.
- [User] OK Google, can you tell me directions? - [Google Assistant] I can't find that place. (audience laughing) - Just, she can tell you directions, right, but in that case, she's just lying.
So (laughs) here's the thing, it's that there's real rules we abide by and there are real rules that virtual assistants are violating all of the time and that's why that promise of voice seems a little bit deceptive at this point because, at any given point, maybe one of these is being violated.
But now that you know why, then it makes it a little bit clearer as to what was, what made that weird.
Oh, it was violating, you guys can talk about this later, like, oh, it was violating the cooperative principle around relevance. OK, and really quickly, let's talk for a second about cognitive load. Cognitive load gets talked about all the time in voice design.
You'll hear it being used for good and for evil. Cognitive load is the part where it takes real brain power to be assembling this information in real time, especially in the eyes-free use case, like the Google Home.
And what does that mean, and why? So when you are hearing sentences, you are assembling these into syntax trees in your mind in real time.
So this is a fairly simple and silly example. The ambiguous sentence is, I shot an elephant in my pyjamas.
And, I shot an elephant in my pyjamas could have two completely different meanings depending on how the syntax tree is formed. If in my pyjamas is attached to the verb phrase, up there, then you're the one shooting in your PJs.
Right, I'm in my PJs; I shot an elephant.
If in my pyjamas is attached to the noun phrase, right there, which is an elephant, that means you shot an elephant who was wearing your pyjamas.
It's a silly example, but this is what your mind is doing in real time as you're listening.
And you guys felt this with that example around what was that last song.
When you heard, well, The Last Song was blah blah blah blah blah, you associated that with, oh, it was the song that I heard previously. But then once you listen a little bit more and she started talking about a synopsis of a movie, you had to reshuffle this in your mind to get the appropriate syntax arranged accordingly to what was being referred to by what.
And that is real.
The fact that you had to listen, rearrange, and then try and keep listening is a real thing. And cognitive load comes up a tonne in voice-only experiences. One, around porting, right? We have the web.
We could just put the web into the speaker and we'll be good.
But then you guys heard, like it's actually really hard to listen to this thing that has no facial expressions and no awareness of whether you still care. And so cognitive load is good and it's real. But there's also a danger to it because what happens is people say, OK, well then shorter's better.
Shorter's better, shorter's better, no cognitive load. No, none of that.
And this is when people start using it for evil instead of good, which is just to say, oh, I want this to be shorter.
But there is actually a lot of data around like, which you guys, I'm sure, are aware of around perceived length versus not and how much you have to fill in the blanks if I'm not giving you the whole picture.
So cognitive load can also be quite heavy if the prompts are quite short because you didn't get enough time to process or enough information to get the whole picture. So cognitive load is, it's something that we're constantly balancing when we designing for voice.
OK, so let's just do a really quick example on this. So, hey Google, any flights to San Francisco on Thursday? So you want to know, are there any flights, and she says, yes, I found four flights.
Here are the four flights.
Which one do you want to hear about, right, or do you even want to hear more about those? Because maybe you just even wanted to know, are there any flights, right? Versus that same question with this response. Yes, I found four flights.
Big Blue Airlines leaves from New York at Kennedy Airport (mumbles) the gate and arrives at Boston and all that, OK. But this, like it's a joke, and you're like, that seems like painfully obvious that that's not the right way to do it.
But this is what we see a lot when we don't get access to these prompts first, right. Which is like, first, let's make a decision, how many flights are there? OK, are there a reasonable amount? Let's just say that.
Yes, I found four flights.
Like that, in itself, is a good thing for the user to know. Do they need to know all of the information in real time? Probably not.
This is a good example of where the cognitive load would be too much. So it seems pretty obvious that we should be doing example one, but you often see things like example two.
Because even this is actually a victory in and of itself, if you think about it.
Like, what happened here is, you know, a developer was like, look, I just need to plug in the airline and the flight number and it goes to the airport and it then leaves at 1:15, right.
This is like a dynamic prompt that can get generated, which is pretty exciting.
It just gets generated in a way that nobody can understand. OK, so that's some of the complexity around modelling a conversation.
Let's talk a little bit about the speakers, so not the devices, like you and me; we're speaking to each other. I'm a speaker.
You're a speaker.
Like we're humans (laughs).
OK, so speaker one, we have to be taking into account that there are a lot of different place and times that the users could be leveraging the Google Assistant and we don't get to know a tonne about that necessarily. They could be hands-busy, right, like they're playing with their kids or they're cooking. They could be eyes-busy, like they're driving and they need just a voice-only response.
They could be multi-tasking.
They could be in private places.
They could be in familiar shared spaces, which is like a variety of a private space that's not entirely public.
So there's a lot here that we take for granted as far as how we have conversations with each other that make designing for these things a little bit more complex.
And then the users are also instant experts, right? We've all been talking our whole lives.
We have high expectations for this because we know what's good and what's natural. And we have low tolerance for error, so it's a particularly dicey area as well.
The low tolerance for error thing is really interesting to me because it's not just the fact that we've got ingrained language, and therefore if you violate that, that seems really off.
There's something to be said around user-driven error verus system-driven error. So user-driven error, if you take, if you think about typing on your keyboard, right, even though the keyboard could be really poorly executed, if you're typing on it and you get the wrong words, you put that onus on yourself.
Like, oh, it's just my, I fat-thumbed these things and now it's my fault that I can't type well, right? There are things that the user could do with poorly-designed things that they'll still take responsibility for themselves when it goes wrong.
But with speech interfaces, I said what I said and if you got that wrong, that's all on the system. That's, I mean, there's no responsibility or onus for the user on what went wrong.
so that is part of this low tolerance for error. If I said something and you recognised it wrong or you processed the natural language intent wrong, that's completely system-driven errors.
There's no user-driven errors in voice interfaces and that makes for a particularly low tolerance for error. OK, and then let's not ignore the other side of the conversation, which is if you're doing this for a chatbot or you're doing this for a virtual assistant, the virtual assistant side, there's a lot to be said about how what gets said reflects back on your company and manifests into your brand attributes.
Everybody projects a backstory and a role onto the thing that's talking to them.
It's just part of what you do as a human.
That sounds cold.
That sounds foreign.
That sounded rude.
That sounded considerate.
All of these things are things you just naturally, it's like that, like the first impression is in the first 30 seconds or something like that. It applies for this too.
And so you have to be very careful about how you say these things and the way you craft them, particularly around TTS.
So text-to-speech is the technology that most companies use in order to render these prompts and the way it does it is not necessarily the most natural, right. So something that you put an exclamation point at the end of your sentence, like, "Let's go!" And then when it gets rendered in text-to-speech, and it gets rendered in TTS, it's like, "Let's go!" Like, it puts that, it doesn't have the like (laughs) attached with the exclamation point, so you have to be really careful about what you say because when it's rendered in text-to-speech, it can get the prosody totally wrong and therefore change the entire nature of the prompt. A really good example of this that we ran into is around the word actually.
So people use actually all the time.
I used actually a million times already in this presentation, particularly when I said, like, I don't watch Silicon Valley anymore because, actually, it's really painful.
Like, actually is something that we use to reset expectations all the time. Actually, you only have 10 minutes left.
Actually, I can't because I have a date; I'm sorry. And actually, when it's rendered by a TTS engine, sounds really rude.
Actually, that's how it gets rendered.
It's not, because when say actually, like we cringe and we say it real fast.
And there's body language to say, like, this is me hedging, right.
But if there's none of that, actually sounds super snooty and it's like, actually, blah blah blah.
So we had to go back and really think about why it is, like what other language cues we can use to replace actually to make something sound a little bit softer, without being tortured by the TTS rendering of that word. OK, and so as if all of that weren't complex enough around how do you model conversation and how do you keep in mind all of these things around the speakers in the conversation, there's also the tools in the toolkit.
So when we talk about voice experiences, these days, it's not voice only, right? You can talk, you can type, you can tap, and you can show. Virtual assistants are not relegated to voice-only experiences anymore, although there is a lot of magic to that.
That being said, you'd think, oh, we've got these extra modalities.
That's great.
It's gonna make it more fun to design.
We're not gonna be limited by voice-only interactions, but actually these complicate and potentially can mire experiences in ways you wouldn't necessarily expect.
Also, what tends to happen, too, is conversation designers tend to be over here. We're like, we think in the voice-only world. This is how you need to render this experience. And then traditional interaction designers are over here and they're like, it's fine, we'll throw it on the screen, it's totally fine, because that's what you know. And that's fine, there's, I'm not, it's not a bad thing, but it may not necessarily be appropriate to just throw something on the screen.
Did you ever, like when you ask somebody a question because you legitimately think they know the answer and they say, I don't know, you can Google it, like there's something very personally frustrating about that.
I know I can Google anything, but I asked you because I thought you would know the answer and I wouldn't have to pull out my phone, right. And so there's something about just showing something on the screen that can be equally disarming as far as like, oh, well, here's just an answer.
And you're like, well, I could have done that; what I was asking was for something specifically from you. OK, so let's talk a little bit about the speech-only signal before we go onto the other ones.
So there's something very special about the nature of the signal.
Screen interactions are deep.
We can nest things in menus.
We have back buttons.
We can nest things in child pages.
Voice interactions are very shallow.
There's no nesting when it comes to voice interactions. Screen interactions, you can go down and you can come back up.
Voice interactions are linear, they are very shallow, and they just keep going, right.
I can't go back to that thing very easily that I just tried to get to.
They're also ephemeral and they're constantly fading, which means they were here one second and if you didn't catch it, then it's gone. So a way to think about that is like, oh, build this app of this thing, but you don't get a back button, you don't get a hamburger menu, and any content you put on the screen disappears in three to five seconds (laughs).
Like that's what it's like designing for voice which makes it particularly hard when people are like, well, we have an app; it's easy.
We'll just put what we have in our app in the voice interaction.
But it's a completely different modality and a lot of the nested interactions in apps don't translate to voice.
There's also the complexity of recognition versus understanding.
So recognition, automatic speech recognition, which often gets referred to as ASR, is just transcribing the thing that I am saying, right. Did you get what I said right? And then there is natural language processing, NLP, which is interpreting that and getting what it is that you wanted out of it. It's, there's two systems and these two systems, by the way, can be completely out of sync as far as the sophistication of one versus the other. You can be very, very, very good at ASR, at recognising words, and getting those words recognised, right, and not necessarily equally good at natural language processing which is interpreting those things correctly. So an example of that is like what's the weather in Springfield? In the United States, there are Springfields everywhere. There's like five in every state, if not more. So what's the weather in Springfield seems like a pretty straightforward query, but there's an amount of natural language processing that needs to get incorporated into finding out which Springfield.
Likely, what we'd like to do is, of course, know like where the user is and use that contextual cue to render the one in Missouri if you're in Missouri, for example.
There's also something like, play yesterday, right. Is it the song? Is it the movie, the playlist, or the audiobook? But you're like, OK, yesterday, that's a pretty straightforward example; clearly they mean the song, right, but which version of the song? Did they want the one by Beatles or the one by Boyz II Men? (laughs) Boyz II Men. (audience laughing)
Or maybe some other cover version, 'cause who hasn't covered this song, right? And when people have these preferences, they take these assumptions that the Assistant does very personally, right. For a lot of you, if I played the Boyz II Men version, you would be very offended. (audience laughing)
And then we talked a little about this, but the text-to-speech, which is the rhythm and melody of speech.
It's not just what you say; it's how you say it. And there's a lot to be said for how much the technology needs to catch up with humans as far as rendering these prompts appropriately. OK, so we've also got an expanding ecosystem as far as how these voice interactions are going to play out, right.
We've got the phone, the headphones, desktop, wearables. I'm gonna go into this fairly quickly, but hang in there with me because what's important here that I'm trying to communicate is that voice-only interactions, in combination with all of the different modalities that we have for wearables, headphones, desktop, speakers, there's a lot to be said around how complex this is. And what I'm hoping by explaining this to you is that when someone asks you, can't you just make a voice app for this, you'll be able to be a little bit more informed on like how complex that actually can be.
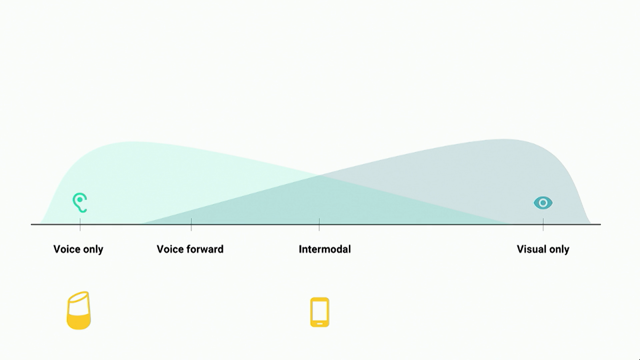
So what we have here is the spectrum of interactions from Voice only all the way up to Visual only. And once you see it in this way, you'll never be able to unsee it.
We refer to this as the two whales diagram (audience laughing) because as one grows in strength, the other one diminishes, right.
These two things aren't correlated one-to-one, and so as, you have to leverage different techniques for a voice-only interaction than you do for a visual-only interaction.
So we have the Google Home which is all the way over here as the Voice only.
And then we have Google Assistant on Pixel, or other Android devices, which is squarely in the middle which is intermodal. So we have this expectational, which one, what works on one can work on the other one, right? But these are actually two very distinct interaction models and you need to be quite careful on how you design for these.
So why is, oh, man, that's not rendering great (laughs), but what you guys can see, if you guys look here, from static to in motion is actually one continuous line. It's just too light to be rendered.
But basically, if you think about the user conditions for the Google Home, they're static.
They're in their living room, their kitchen. They're somewhere in their home, right? And it's fairly private; we can assume that. And it's touch-poor.
There's no touch interactions with the Google Home. When we think about output and input, it's very low on the visual, very high on the audio, very low on the input for visual, very hight on the audio for input.
So this kind of just gives you a spectrum of the different nature of the interactions that each modality can have. Now, if we think about the smartphone, the Pixel, or any Android phone with the Google Assistant, the user conditions are completely different. They're in motion, they may be in public, and it's a very rich touch interaction or it could be the complete opposite.
They could be at home on their couch.
And that's when the bars are really small like that. So there's a lot of conditions that play into the variety of interactions people will have with this modality.
Pretty, straightforward again here.
Overall, my point here is that these two modalities have completely different user conditions.
And when you break 'em down in this way, it makes it much easier for people to see you can't port one to the other without considering all these different things. So that was the Pixel and the smartphone.
As I mentioned earlier, there's this new gadget we're launching later this year, this Google Smart Display which is considered voice-forward with a display. So it's actually right here, which creates a really interesting tension for design because it's voice-forward.
But people are like, oh, it's got a screen. We just need to pop stuff up on the screen. But it's not that easy because it's supposed, the magic is in the voice, not in the screen. We all have televisions, tablets, like phones everywhere. We're surrounded by screens all the time.
The magic isn't in the screen.
The magic is in the voice, right? When you guys think about Jarvis and all these, Her, right, there was no screen with Her. That was the most magical movie ever.
So you just have to, (audience laughing) its very interesting because you're like, oh, we put it on a screen, so now we're on this end of the spectrum.
But, really, we've got this tension which is that it's a voice-forward product and that we need, we have a screen, but we shouldn't rely on it.
This also, as I mentioned before, this diagram gives you the breakdown to explain to people why porting is a trap. Porting doesn't work.
Porting the web onto a speaker was not a successful strategy and it's one of the reasons why I have a job. So (laughs) this is all the way over here.
Porting it over here is particularly painful. OK, and before we go, so this was all pretty technical, right.
Like, I wanted you guys to understand the difference between human language understanding and conversation design and the back end and the front end and the different modalities and the user considerations across the spectrum, but the number one thing is to just try and design for empathy.
Which is really hard in this space, to be honest, because, you know, for example, the Google platform is huge and to be able to create empathetic experiences for each user is really hard, especially for all of the things that you can ask. But we try very hard and it doesn't always work, but it's super important and we do think it's super important.
I thought the talk this morning was incredibly relevant as far as what we should be trying to consider when designing at such a large scale.
It's very hard but we try.
And we try.
Some quick resources around designing for voice and designing with empathy, I'll leave that up for a second.
And then, yeah, that's about it.
Thank you. (audience applauding)
(upbeat synthpop music)
There are few places where design is less evident than when you use a voice user interface, like the Amazon Echo or the Google home. But as anyone who has used Alexa or the Google Assistant knows, it’s painfully obvious when a voice based experience is not designed well. You go nowhere, fast. It’s the equivalent of a 404 page, but somehow more personally frustrating.
As a former voice designer for Alexa, and a current voice designer for the Google Assistant, I would like to talk about the ins and outs of designing for an eyes-free experience. What is voice design? What does it look like? Why is it important? What happens when you do it well? And what happens when it’s not designed at all.
Start here…
Algorithms.design is a huge collection of links created by Yury Vetrov that includes many of the ones in the document (in a much nicer format), spanning current tools by function, examples of generative design in other disciplines, intros to AI/ML, and ethics.
Also while it’s not specifically about AI – if you are interested in discussions around design ethics, the community in the How Might We Do Good Slack is tackling things like a design ethics framework, collective action, and the toolkit for overcoming the barriers to doing good:
Libratus poker AI and poker AI history
https://www.nytimes.com/2011/03/14/science/14poker.html
https://www.pokerlistings.com/from-loki-to-libratus-a-look-at-20-years-of-poker-ai-development
https://www.wired.com/2017/01/rival-ais-battle-rule-poker-global-politics/
https://www.access-ai.com/blogs/last-human-beat-ai-poker/
https://www.pokernews.com/news/2017/10/artificial-intelligence-poker-history-implications-29117.htm
https://forumserver.twoplustwo.com/29/news-views-gossip/brains-vs-ai-poker-rematch-coming-rivers-casino-1647075/ (CW: this is a poker forum so proceed with caution)
https://www.cs.cmu.edu/~noamb/papers/17-IJCAI-Libratus.pdf
https://www.cs.cmu.edu/~sandholm/Endgame_AAAI15_workshop_cr_1.pdf
https://www.reddit.com/r/MachineLearning/comments/7jn12v/ama_we_are_noam_brown_and_professor_tuomas/
https://science.sciencemag.org/content/early/2017/12/15/science.aao1733?rss=1
https://www.youtube.com/watch?v=2dX0lwaQRX0
https://www.cs.cmu.edu/~noamb/papers/17-AAAI-Refinement.pdf
Poker endgame theory/systems
https://www.icmpoker.com/en/blog/nash-calculator-and-nash-equilibrium-strategy-in-poker/
https://www.pokerstrategy.com/strategy/sit-and-go/sage-sitngo-endgame-system/
AlphaGo
https://fortune.com/2016/03/12/googles-go-computer-vs-human/
https://www.wired.com/2016/05/google-alpha-go-ai/
I also highly recommend watching the AlphaGo documentary on Netflix!
AI design tools and projects
https://magenta.tensorflow.org/assets/sketch_rnn_demo/index.html
https://magenta.tensorflow.org/sketch_rnn
https://www.adobe.io/apis/cloudplatform/sensei.html
https://www.theverge.com/2017/10/24/16533374/ai-fake-images-videos-edit-adobe-sensei
https://www.fastcodesign.com/3068884/adobe-is-building-an-ai-to-automate-web-design-should-you-worry
https://airbnb.design/sketching-interfaces/
https://www.youtube.com/watch?v=VLQcW6SpJ88
https://github.com/tonybeltramelli/pix2code
https://medium.com/@thoszymkowiak/pix2code-automating-front-end-development-b9e9087c38e6
https://www.theatlantic.com/technology/archive/2017/06/google-drawing/529473/
https://research.googleblog.com/2017/04/teaching-machines-to-draw.html
https://medium.com/netflix-techblog/extracting-image-metadata-at-scale-c89c60a2b9d2
https://blog.floydhub.com/turning-design-mockups-into-code-with-deep-learning/
Ethics and AI
https://www.wired.com/story/why-ai-is-still-waiting-for-its-ethics-transplant/
https://docs.google.com/spreadsheets/d/1jWIrA8jHz5fYAW4h9CkUD8gKS5V98PDJDymRf8d9vKI/edit#gid=0
https://en.wikipedia.org/wiki/Philosophy_of_artificial_intelligence
https://www.theguardian.com/technology/2016/dec/04/google-democracy-truth-internet-search-facebook
https://www.nytimes.com/2017/11/21/magazine/can-ai-be-taught-to-explain-itself.html
https://www.royapakzad.co/newsletter/
https://pubpub.ito.com/pub/resisting-reduction
https://logicmag.io/01-interview-with-an-anonymous-data-scientist/
https://www.youtube.com/watch?v=F_QZ2F-qrGM
https://www.engadget.com/2016/08/16/the-next-wave-of-ai-is-rooted-in-human-culture-and-history/
https://www.creativereview.co.uk/delusion-data-driven-design/?mm_5a924d083f282=5a924d083f326
https://www.eyemagazine.com/blog/post/ghosts-of-designbots-yet-to-come
https://www.epicpeople.org/racist-by-design/
Automation and the future of work
https://www.theguardian.com/us-news/2017/jun/26/jobs-future-automation-robots-skills-creative-health
https://blogs.adobe.com/digitalmarketing/analytics/next-retail-apocalypse-look-toward-banks/
https://www.nytimes.com/2015/04/19/opinion/sunday/the-machines-are-coming.html
https://www.oxfordmartin.ox.ac.uk/downloads/academic/The_Future_of_Employment.pdf
https://www.npr.org/sections/money/2015/05/21/408234543/will-your-job-be-done-by-a-machine
https://www.fastcodesign.com/90127514/good-news-designers-the-robots-are-not-taking-your-jobs
https://www.fastcodesign.com/3057266/designers-robots-are-coming-for-your-jobs
https://www.wired.com/2017/02/robots-wrote-this-story/
https://techcrunch.com/2017/03/26/technology-is-killing-jobs-and-only-technology-can-save-them/
https://hbr.org/2016/11/how-artificial-intelligence-will-redefine-management
https://www.businessinsider.com.au/momentum-machines-funding-robot-burger-restaurant-2017-6
https://www.wired.com/story/googles-learning-software-learns-to-write-learning-software/
https://www.nytimes.com/2016/12/21/upshot/the-long-term-jobs-killer-is-not-china-its-automation.html
https://www.ft.com/video/f2196894-ba28-49fb-a0de-933f9d806b35
Diversity and inclusion (or lack of) in AI
https://medium.freecodecamp.org/why-we-desperately-need-women-to-design-ai-72cb061051df
https://journals.sagepub.com/doi/abs/10.1177/135050689500200305
https://www.inc.com/nancy-a-shenker/is-artificial-intelligence-a-feminist-issue.html
AI progress and current state overviews
https://ai100.stanford.edu/2016-report
https://gigaom.com/2017/10/16/voices-in-ai-episode-13-a-conversation-with-bryan-catanzaro/
https://medium.com/machine-learning-for-humans/why-machine-learning-matters-6164faf1df12
https://www.wired.com/2014/10/future-of-artificial-intelligence/
https://aiindex.org/2017-report.pdf
https://drive.google.com/drive/folders/1CD-hDgf684WPCT1fzD0QmnVKC03wZaF1
https://www.technologyreview.com/s/609611/progress-in-ai-isnt-as-impressive-as-you-might-think/
Relationship between AI and humans
https://magicalnihilism.com/2016/03/31/centaurs-not-butlers/
https://www.huffingtonpost.com/mike-cassidy/centaur-chess-shows-power_b_6383606.html
https://jods.mitpress.mit.edu/pub/issue3-case
https://www.abc.net.au/radio/programs/conversations/conversations-genevieve-bell/9173822
https://www.theguardian.com/technology/2016/nov/27/genevieve-bell-ai-robotics-anthropologist-robots
AI applications in mental health
https://medium.com/@davidventuri/how-ai-is-revolutionizing-mental-health-care-a7cec436a1ce
https://futurism.com/uscs-new-ai-ellie-has-more-success-than-actual-therapists/
Overview of design/UX + AI
https://www.usertesting.com/blog/2015/07/07/ai-ux/
https://www.rtinsights.com/artificial-intelligence-and-ux/
https://usabilitygeek.com/artificial-intelligence-fill-gaps-ux-design/
https://www.wired.com/story/when-websites-design-themselves/
https://bigmedium.com/speaking/design-in-the-era-of-the-algorithm.html
https://bigmedium.com/speaking/design-in-the-era-of-the-algorithm.html
https://bigmedium.com/ideas/links/google-teaches-an-ai-to-draw.html
https://uxplanet.org/how-ai-is-being-leveraged-to-design-better-ux-8710efce79a1
https://www.drewlepp.com/blog/can-machine-learning-improve-user-experience/
https://medium.com/@creativeai/creativeai-9d4b2346faf3
https://uxdesign.cc/how-ai-will-impact-your-routine-as-a-designer-2773a4b1728c
https://www.sitepoint.com/artificial-intelligence-in-ux-design/
https://theblog.adobe.com/the-rise-of-artificial-intelligence-how-ai-will-affect-ux-design/
AI/tech fails
https://mixergy.com/interviews/cloudfactory-with-mark-sears/
https://www.thedailybeast.com/ces-was-full-of-useless-robots-and-machines-that-dont-work
https://www.technologyreview.com/s/609611/progress-in-ai-isnt-as-impressive-as-you-might-think/
https://www.theverge.com/2018/1/17/16900292/ai-reading-comprehension-machines-humans
Things that didn’t have a group!
https://qz.com/1034972/the-data-that-changed-the-direction-of-ai-research-and-possibly-the-world/
https://youtu.be/5OTnCt3MnUQ?t=5h57m50s
https://alistair.cockburn.us/Taylorism+strikes+software+development
https://www.decolonisingdesign.com/
https://www.epicpeople.org/empathy-faux-ethics/
Darla Sharp – Crafting Conversation, design in the age of AI
While all of us having experience designing screens, many of us don’t have experience designing for voice.
Darla currently works at Google (Assistant team) as a Conversation Designer, although the job may also be called Voice User Interface (VUI) Design, or Voice Interaction Designer. In the end it’s just interaction design with a focus on voice.
Google is moving away from mobile-first to AI-first. Google Assistant’s product line is expanding rapidly, including some devices that do actually add a screen (although not as the primary focus).
Design + AI – there is an increase in voice-forward design. The question of course is why? When we all have smartphones why do we need this additional modality?
- speed and simplicity
- ubiquity
When voice works it really is quicker – there are a surprisingly large number of taps to do simple things. For example you can ask for the latest Gorillaz album in Spotify, much faster than you can open up the app, search for it, find the album and tap to start playing it.
Phones are considered ubiquitous, but as virtual assistants spread to other places they are getting more popular. You shouldn’t be using your phone in the car…. right?! So the ubuiquity is moving to the assistant and not the device.
Design considerations
- conversation design, which owes a lot to linguistics
- speakers (not the devices)
- the tools in the toolkit
- expanding ecosystem
Conversation design owes a lot to linguistics; and the way humans process language.
Words (sound into words) → Syntax (words in to phrases) → Semantics (derive meaning) → Pragmatics (interpret meaning in cultural context).
This is really easy in a first language, basically instinctual or obvious. However it is incredibly fragile, if anything breaks the entire interaction falls down. If someone makes a mistake in a second language, it confuses people who are talking or listening to them. Or if someone’s accent makes the sounds hard to understand, the most basic level of comprehension has broken.
How does this break out into conversation design?
Front end:
- Words: What’s the weather today?
- Syntax: In Alameda today, it’s 72 degrees and sunny.
Back end (most of the time is spent after this, on logic and UX flows)
- Semantics
- Pragmatics
This interaction requires knowledge of the user’s location and preferred units of measurement (degrees F or C?).
Cooperative principle – rules that we innately know, that we use in order to be good conversational analysts.
- Quality – appropriate for context
- Quantity – as informative as required (neither too little or too much)
- Relevance – unambiguous
- Manner – true
When assistants get something wrong, they will have violated one or more of these principles.
Examples of Google Assistant getting these wrong…
- Quality – “open uber” → “I can’t open apps” … but they wanted to open an action they know the assistant can do
- Quantity – (a question about politics/law) → the response had way too much information and wasn’t the right detail
- Relevance – “what was that last song” → (long plot synopsis of a movie called The Last Song)
- Manner – “ok google can you tell me directions” → “I can’t find that place” (actually she’s just lying, she can tell you directions)
Cognitive load – this is discussed all the time in voice design. When we listen to people talking, we form a syntax tree that lets us understand the words. We can both listen and process, this is within our capacity of cognitive load.
“I shot an elephant in my pyjamas” can translate into two different language trees. One has you wearing the pjs, the other has the elephant wearing them. We know who is wearing the pjs, but computers have a much harder time.
Example 1:
User: Hey Google, any flights to San Francisco on Thursday
A: Yes, there are four flights. They’re at 1:15, 3:55, 5:05 and 6:35pm. Do you want to hear more about one of these.
or
A: Yes, there are four flights. Big Blue Airlines 47 leaves New York at blah blah blah….
Speakers… people may be speaking in a very large range of scenarios. They may be hands-busy or eyes-busy, they may be multitasking, they may be in a private or public space. Users are all instant experts – we’ve been talking all our lives! So they have high expectations and low tolerance for error.
The other side of speakers is your assistant, which is representing your brand when it’s talking to the user. It manifests brand attributes, it has a back story and a role. If you don’t define all this, your users will!
Text-to-speech can really change the nature of the communication. Simply removing the exclamation mark from “Let’s go!” completely changes the tone. TTS makes the word “actually” sound incredibly rude and condescending, because all the tone and body language is stripped away. So were it might have said “actually” you need to find another word, to design around this issue in the medium.
We have many tools in the toolkit now – people can speak, type, tap and show things to a device. Most organisations still have siloed teams working on these modalities.
The nature of the speech-only signal is unusual. It’s linear, always moving forward (there’s no nesting or layers the way we work on a screen); and they are ephemeral, constantly fading. They were here and now they’re gone – imagine a screen interface that only shows for five seconds before fading away.
There is complexity in recognition and understanding – what users say and mean. ASR and NLP.
“What’s the weather in Springfield?”
→ which one? there are many across America and even around the world
“Play Yesterday”
→ do you mean the movie or the song..?
→ which version of the song? the original or one of the covers?
Text to speech has the rhythm and melody of speech. It’s not just what you say, it’s how you say it.
As more devices become available, it gets more complex to work out how things work across all of them.
There is a spectrum from voice only, to voice forward, intermodal, visual only.
There is a range of user conditions – static or in motion, public or private space, rich or poor touch interaction. Mobile phones move through these, the context changes to the extremes for motion and privacy.
This is also why porting things doesn’t work. If you port a screen app straight to voice, it just doesn’t work.
The number one thing is to design for empathy. That’s a real challenge for a platform as big as Google, but it’s really important… it’s very hard but we try!