Your web page never listens to me
(upbeat music) - Cool, let's get going.
The story of how I got into this started like most stories do, they start in a community, they start at a meet up event, a conference, something like this where you're surrounded by cool people doing cool things with cool ideas. In this case it was the Perth Web Accessibility Camp in February this year, Julie ran it, I don't know where she is, but it was an excellent day, I presented a talk about being colour blind and trying to create a design system with that, but before me and after me were two speakers who were both completely blind.
So Zel it up before me and did just this great opening about the principles of accessibility, the four principles, or as she said the pour principles, perceivable, operable, understandable and robust. I'm gonna be talking about those a little bit more as I keep going through, 'cause it ties into everything.
But then after her, Ayesha got up and demoed, has anyone heard of Seeing AI? It's a Microsoft app for phones, and you can point your phone at a label on a Coke bottle and it will read Coca-Cola, and you point it at the ingredients and it will read the horrible, horrible things that are in it, you can point it at a document and it will scan the document and then begin to read it out to you, you can point it at a person and it will say it's a male 30 years old, or a roundabout.
It was really cool, and so I was at this event and it got me thinking about accessibility AI, is there a way we can use this new frontier in technology to make stuff that's better? So that was my idea, can we make this machine learning stuff to make the web more voice friendly, more inclusive, all of that, or put differently can we do better than screen readers, can we come up with something that is similar but different, something that's perhaps more not just a last resort, but something that you and I might wanna use even if our eyes work okay.
We were doing a design book club at Culture Amp earlier in the year, and we were reading Accessibility for Everyone by Laura Kalbag, and this image was in it.
I'm not sure where in the world this is, but I've seen stairs like it, does anyone know what is special other than the fact that it looks really interesting and cool? - [Man] It's got ramps.
- It's got ramps, it is a wheelchair accessible way to ramp your way up without looking like it's wheelchair accessible, it just looks cool, and it's not just helpful for people who happen to be in wheelchairs, it's helpful if you wanna walk slowly and don't like stairs, it's helpful if you're on roller blades, if you've got a pram, if you've got a shopping trolley, making it more accessible for people with wheelchairs makes it more accessible for everyone, and it's the same on the web, if we can make our interfaces more accessible for people who don't wanna use their hands 'cause they've got wrist problems or whatever's going on, or for people who can't see what's happening on the screen, either because they're blind, or their eyesight's beginning to fail, we also make it accessible for other people who's hands might not be free 'cause they're cooking dinner, who don't have time to look at something because they're too busy driving and we don't want them to crash into the cars and pedestrians around them. When we do accessibility for, if we make it better for them we make it better for everyone.
So can we use voice to do this? It was 50 years ago that we got our first picture of what talking to computers might look like, does anyone know what this is off the top of their head? - [HAL] I'm sorry Dave, I'm afraid I can't do that. - It's HAL, the doomsday computer from 2001: A Space Odyssey.
For 50 years every time we've imagined we talk to computers, it kind of takes on this dark and sinister tone, even things like this.
- So when is the end of the world? - [Computer Voice] Unless it collides with a very large rock or-- - Yeah, for some reason every time we talk to computers we imagine them taking over and killing us. But that is a lot of what we see with the big voice assistants, it's like they're good at setting timers, they're good at playing a song, they're good at setting a reminder for tomorrow to do something, not necessarily great at everything else, they're good for funny things that you ask it, like when the end of the world is, but compared to what we can do on the web it's so limited, it feels like you're talking to a giant if, then, else statement, and unless the people who designed it have specifically put in what you're trying to ask it to do and you ask it in just the right way it doesn't always work that well.
Compared to what we can do on the internet where there is so much content, there are so many things that we can do, so many actions we can take, it's just a bit limited.
So can we bring speech to the web? I had no idea so I went and searched, like you do, and what's weird about this other than the fact that it's not Google, is that this result here is the one that was helpful to me, look at the date, for those of you who can't see it this article was written in January 2013, is when Google added the speech API to Chrome, it's been there for over five years, and I'd never heard of it, I'd never touched it, I'd never done anything.
Why if it's been there for so long do we not know about it? That's why.
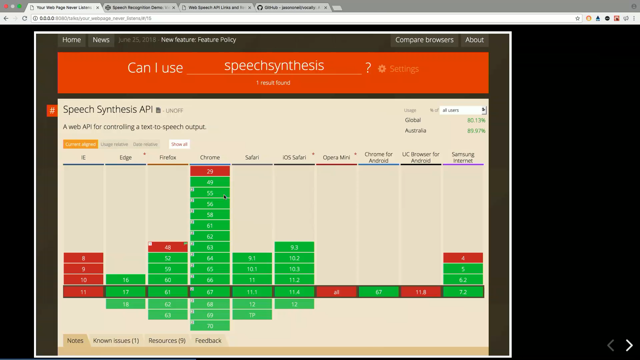
Can I use with a whole sea of red.
Speak recognition is just part of web speech, that's the computer listening to you and turning what you say into words, the other part is turning words into speech that you can hear with your ears. And that's well supported, look at all that green, very exciting, other than Internet Explorer, it's pretty much good everywhere.
And UC Browser for Android which really worries me that browser.
Anyway, so speech synthesis, that is a hard word, I wish they picked better words.
I'm gonna quickly run through this, and then we'll talk about speech recognition. The first time you do a demo of this, this is the MDN demo, and you can get it to say things like hello web directions. - [Speech Synthesiser] Hello web directions. - [Jason] And that's Karen, you can also pick other voices.
- [Speech Synthesiser] Hello web directions. - [Jason] Yeah.
You can pick, they have accents for different languages, so I was in Italy recently.
- [Speech Synthesiser] Hello web directions. - And while wife can't have gluten, so I was saying a lot of this when we were there. (Speech Synthesiser speaks in foreign language) Yeah so you get to play around, and these voices, they're not specific to the browser, they're coming from the operating system, so the voices that you get to speak to you are chosen, so this list, I mean Chrome on a Mac will be different to Chrome on Windows, you'll get different default voices, but you can get a list of what voices are there, and try to pick the ones that are interesting to you, or just use the default ones.
So that's all very interesting, the way you add stuff, is basically you add an utterance, an utterance is a short thing you want the computer to utter, to say, if it goes for longer than 15 seconds, Chrome will stop talking mid-word and never talk again. (audience laughs) Just a browser quirk.
So there's ways you can work around that, but essentially you have to break your text up into small utterances, and it's played by the operating system not the browser, so if you start uttering something and you mute the tab, it will keep playing.
Fun, so don't abuse this too much or it will get banned. Anyway, I was looking at it and thought we could probably make a more friendly API for this, so I started working on one called Vocally, so instead of having to think about utterances and everything, you can just say, say hello, and then pause and then say things.
- [Female Speech Synthesiser] Hello.
My name is Karen, but you can call me.
- [Male Speech Synthesiser] The computer.
- The computer.
(audience laughs) So as you can see it's like the APIs are there, they work, they're a little bit fiddly, but you can pretty easily wrap them into something that you'd enjoy using on a day-to-day.
With this one, that's reading out JavaScript strings, I went and tried to make something that could read an arbitrary HTML node like an article, so talking about semantic HTML in Mandy's talk before, can we get our thing to just read all of this article about self driving cars? And the code is just .read, and then does it work? - [Speech Synthesiser] Opinion, if we want a future with driverless cars in it we need to learn to trust the technology, by Alan Finkel, posted Friday.
- So that's pretty cool, so that actually what I mentioned before about Chrome stops talking, you actually need to then go and you can't just take the inner text for the whole article and use it, you have to split it by where the sentence boundaries are, where the commas are, that kind of thing, but it's not too hard to get that set up, and as I said I've done a project with it and I posted it online, I'll show you the link at the end.
But you can pretty easily get this into something that's good.
So what about speech recognition? Is this even possible? Chrome is there, the browser support is like where do we even start? So Chrome's support for this actually uses Google's APIs. And have any of you used Google's machine learning stuff? No? Some people? So Google has a whole bunch of commercial APIs, and the voice recognition in the browser, the HTML 5 thing is actually backed by their commercial service, if you turn your Wi-Fi off the voice recognition will stop working, so it's actually sending your voice to a third party server and sending back the results. Privacy issues? Probably, that's what we want some other browsers to support it. Mozilla is working really hard on this, so if you go to voice.mozilla.org, and every single person should do this, especially if you have an accent that is not Californian, because we wanna get the whole world to be able to be understood by a really great machine learning model. So you can go there and just read out a few pieces of text, and it adds it to their model, and then they're building a service which is pretty cool. If you wanna use this stuff now, but you don't wanna wait for all the browsers to have it, you wanna offer it in Edge and Safari and not just Chrome, the Bing Speech API and the Google Cloud API are both commercial products that work cross-browser, they just use the microphone input, post it to the server and send you back a result. Someone has created in the last three weeks, a full polyfill using the Microsoft API, and so it will give you an exact polyfill of the Web speech API, so when I gave this talk three weeks ago that didn't exist, now it does, that makes me pretty happy.
And Mozilla is working on their thing as well which I'll show you in a minute. But is the recognition actually any good? We'll find out.
Loading, loading, loading.
Alright Chrome are you listening to me? Not quite.
A surprising amount of stuff it does get right, you do find some funny things though.
Pretty impressive.
One of the funny ones that I discovered last night, I'll try to think of a sentence where this works, I wouldn't trust any nurse or doctor who doesn't treat me like a human. Aw, it didn't do it.
Let's wait.
(audience laughs) I wouldn't trust any nurse or doctor who doesn't treat me like a human.
That's so interesting, when I was doing this earlier today that sentence continually capitalised Doctor Who. And it was like Doctor Who, I know all about Doctor Who.
So maybe their machine learning is currently learning, and it's worked around my weird glitch, but that's okay, so the speech recognition surprisingly good, it's not good enough that you'd dictate your essays using it, but to pick up a small command, or to enter someone's name it's probably good enough. Come on, I'm gonna close that.
(audience laughs) That reminds me a bit of this, Alexa, remind me to feed the baby.
Yes I will remind you to defeat the baby.
(audience laughs) You wonder why we always imagine them wanting to kill the human race.
Also since I gave this talk a few weeks ago, Firefox has been hard at work at this, oh master passwords.
(audience laughs) And they have been working on their service, and I just found this anonymous, some Mozilla employee had a GitHub repo where he was working, and I just found the service, and it's got no authentication, so I took the liberty of creating a Codepen which tries to polyfill the API, it doesn't do draught results, but it does pick up what you're saying.
I think, maybe, ah yes, there we go.
So the Mozilla one is pretty good.
(audience laughs) You don't know your own name, oh well.
It is interesting.
It's got a way to go.
Sometimes if you're in a quiet room the recognition is really good, if you're in a room like this where there is a bit of an echo and a bit of crowd, not as good, if you're on a train or in a cafe, it just doesn't work at all, same for Google's.
This stuff will, there's user interface considerations here, like it's not, people aren't gonna start talking at their phone, and they're not gonna want to listen to it all the time, so think about the environment people are in and how well this stuff will work, but hopefully it'll get better over time.
One key thing here is to respect the privacy of your users, so we talked yesterday about permissions like this. So for push notifications, do you really wanna just be asking people to listen to their microphone? When I see this on apps I'm downloading, they're like it would like to use your microphone, it's a big red flag unless I know why, whereas if I know why I'm like hey it's got some voice features that's amazing. So similar to push notifications, if you're gonna use this, let the person know, don't just blindly open a page and start requesting permissions, because users will deny it, and then later they'll probably block you forever. So one big gotcha if you wanna go play with this stuff, it only works with HTTPS, I've been doing web development since I was still in school, and I still struggle to get HTTPS working in localhost, so it makes playing with it a bit harder, so I've used Codepen for most things, so if you wanna go experiment with this, either put the time in to get that setup working locally, and I did but then the certificate expired a week later, so I gave up.
But yeah, or just play with Codepen until you're ready to actually do something cool with it.
The speech recognition, I'll just show a bit of how the API works, you have a continuous mode where it can keep listening, and it will continue to post events as new stuff comes in. You can choose how many alternatives you want it to send through, the Mozilla service, that's kind of like this secret beta, it only sends one, but the Google service will often send you several alternatives, and it gives you a confidence rating of how likely they are to be, so you can look at the results, you can get the transcript, you can get the confidence of that one and you can look at them and see alternatives, so it might have guessed wrong, but one of the alternatives might be right, so if you are searching for a specific command, you should search through all the alternatives to see if one of them is there. Again the API was not that great, so I went on the hunt for other APIs that do stuff, and a found some cool libraries like this one, Artyom.js, which was kinda cool, but had not great documentation, and then I realised the project was dead, but it was still interesting, interesting ideas about how you could do these APIs, like having wild cards, so it hears some text and then you get a function with the missing bit, so there's some cool ways that you can begin to play with this, I will show a quick demo of that one.
So in this, let me bump the font size again, I had a bunch of things that it knows about, things to say, and it should respond, so where am I? Oh no.
(audience laughs) Where am I? - [Speech Synthesiser] Web directions.
- What day is it? This is what I mean when it was like not a great library and a bit unmaintained, that's it trying to hear web directions over the speakers, and it's feeding back into itself, so obviously if we're gonna do this we need to put some more time into thinking through what the API looks like when it's listening when it starts a new phrase, that kind of thing.
But I'm convinced that the machine learning is getting there, the recognition is gonna get better, we just have to start thinking about how we're gonna make it work in terms of code, and how we're gonna write APIs that work.
But more importantly, we need to think about how we're gonna do this in terms of interfaces, 'cause a lot of the example projects I found online imagined recreating something like J.A.R.V.I.S. from Iron Man, where you talk to an infinitely smart computer and it has all of the possible commands built in, but in reality we want our interfaces to be perceivable, people should be able to see it or hear it, so if they've got their volume muted or they're on a train, they should be able to see a text alternative, we want it to be operable, they should be able to, if their voice recognition isn't working for them, they should still be able to click, or they should still be able to use their keyboard, we don't wanna only do voice.
We want it to be understandable, so what are your options, and this is my problem with Siri and Alexa and the like, you don't know what is available to you, you don't have a sense of what the actions I can take with any given interaction are, and so we have to start thinking about all of these things and try to design around it. Does anyone remember Flash websites? What's stuff on this page do you think would be clickable? That's right, all of the shapes.
I think this is the trap we're gonna have to avoid as we start designing conversational APIs, we don't wanna create these mystery link navigations where you're like, I'll have something, I don't know what I'm gonna get, we wanna be able to list what's available so people know what they can interact with, it's just a less frustrating user experience. So thinking about all those things, what can we build? WhatsApp has a cool example of simple things you could do now, they just have a little microphone icon and you can dictate and it will use speech recognition to send a text message. I like that, it's simple, it's obvious to the user, it wouldn't surprise them if they click that button and it says I wanna use your microphone, I think that's a great example of progressive enhancement, if they don't have it they will just type a message the old way.
I think about what we're doing at Culture Amp, and a page like this where someone comes to land on a survey design, do you wanna read the title, Engagement Survey, welcome to the whatever Engagement Survey, you might wanna read that bit, but do you then wanna read the terms and conditions? Maybe, I don't know what GDPR says about that.
But you have to start thinking about what on this page would you read by default, what would you let them know is there if they wanna read it, and if I said get started, I would expect it to click the Get Started button, and so I haven't actually done any of this yet, but I'm beginning to think how can we tie this into our existing webpages, so that instead of designing voice controlled pages where there is no other interaction, how do we take an existing page and just allow our voices to use it, and allow it to read it out to us? Questions like that.
Doing it for forms, our survey form is a bit old and a bit gross, it's not as pretty as that one, we're redesigning it, it's gonna be off-line friendly and accessible and everything, so if you'd like to join please come say hi, we need help.
But how you fill out forms, how you go about showing explorative data or infographics, how do you show this stuff when it's a speech driven API, how do you let someone have that same experience of exploring and seeing what's on the page? These are big questions, and I think it's an exciting field, this tech is gonna get better, and people are gonna get used to it, and we should be able to interact with the site while we're driving a car, while we're holding a kid, while we're cooking dinner, we should be able to do it without our hands and without our eyes looking at the screen, and I think that Semantic Web combined with some really smart ways of thinking about how we can use these technologies to create good experiences, is the future.
So the idea, can we create a better way of doing it, will it work? I think there's an option there, I think this can work, it's very early days, you saw how hit and miss it feels, but it's enough to get started, so where to from here? Obviously we're waiting for better browser support, but as I said, it's like in the last three weeks we now have a polyfill that works on all browsers including Edge and Safari.
Waiting for better libraries and APIs, and I'm working on that, if anyone else wants to work on that, come say hi, open source, yay.
And then I think the future involves having the browsers actually offer some of this stuff out of the box, so that as web developers we don't reinvent the wheel for every page, and not every page is different, but we have a consistent way of knowing how to speak to our browser and how it will speak back to us, and I think that's really interesting, whether that's an extension or built in, that's the power of the web, having a user agent that works for you, and I'd like to see a voice powered user agent. So yeah, that's my talk, I hope you've enjoyed it.
(audience applauds) (upbeat music)
Siri, Alexa, Cortana and “Hey Google” – the big companies are all building services that can talk to us, and that we can talk back at. These tools are great for setting timers, adding reminders, and playing a song. But compared to the sheer amount of information and interaction available to us on the web, they can still feel quite limited.
How can we, as standards-loving web developers, help shape the future of voice controlled, conversational user interfaces? How can we use the well supported Speech Synthesis API, and the still new Speech Recognition API, to teach our pages to talk, and to listen?
And how can we make the key information on our page, and the key interactions, available to people who might be driving, preparing food, carrying a child, or people with visual impairments? In this talk we’ll explore how voice controlled interfaces open even more possibilities once combined with the natural strengths of the web platform.
- Link of related resources, projects, examples, codepens and more: https://jasono.co/web-speech-a
pi/