(playful electronic music) - Good morning, everybody.
So as John said, I'm Andrew Betts.
I run developer relations at Fastly.
I will skip the intro 'cause that was extremely long and much appreciated.
I'm on the W3C Technical Architecture Group, and I've been working for Fastly for about six months. (clears throat) Sorry.
So today I want to talk about networking, and why you should care about HTTP, how it's changed over the years, and what a difference that makes to the way we optimise websites, and how we can implement some best practises in our applications to make best use of the network. So, why does this matter? Well, sorry.
Websites are getting more complicated, more requests. Those requests interact in complex ways.
Some are on the critical paths, some are not. Some are loaded with high priority, some with low priority. We have more debugging tools now to understand those priorities and understand those critical loading paths, and we have more sophisticated tools for measuring the effectiveness of our sites and understanding what actually matters to customers. When I started building for the web, we measured the load time of our HTML document, and we thought that was the best metric for understanding the performance of the site, one single HTTP request, and that was of course complete nonsense.
But then we changed to measuring the load event, and that wasn't really much better.
It was kind of going to the opposite extreme. We had to wait for every single resource on the page to load.
So today, we have things like time to first paint and time to first meaningful paint, and time to interactive. These kind of of metrics make a really big difference to helping us understand exactly what customers are experiencing.
Sites are getting bigger.
The average webpage is now over 2 1/2 megabytes in size. This is bigger than Doom.
(audience laughs) PC World picked up on this and wrote their own article about it, which is basically the same story.
But they did add something to the story because this page is also bigger than Doom. (audience laughs) We shouldn't pick on PC World though because this is just average, like this is a completely normal behaviour on the web. It's a worrying behaviour because in some areas of the world these sort of pages are very expensive to download. MSNBC.com's homepage would cost 2.2% of an average income in Mauritania just to load that one page on mobile. So I don't think many people are doing that. And we know that we shouldn't be including hundreds of third-party scripts on our page, and we know that that's a performance challenge. But this is still something that's very difficult to avoid doing, and very highly skilled and competent technology teams like the one at The Economist, for example, are still embedding dozens of third-party originated content on that page. And this is Ghostery, which is a great tool for revealing all of this stuff as you surf around the web. So how do we start optimising this wildly complex situation? So I want to start by thinking about how we understand the internet.
And I'm always amused when I look at popular press coverage of internet stories outside of the technology press 'cause they're almost always illustrated with an image like this.
I (exhales), it's numbers or something? I don't know. (audience laughs)
Not quite sure what's going on there.
This is one of my favourite ones from like the mid '90s maybe.
So what does this tell us about the internet? Well, it's global, usually blue I find.
Typically blue. (audience laughs)
But actually we're not that much better. (laughs) We're not much better about this ourselves, and even in the industry we tend to find it difficult to explain how the pipes work.
In Tim Earsley's office at MIT, he still has this poster advertising the first international world wide web conference in Geneva.
And it explains that in order to access the conference schedule, that you should telnet to www94.cern.ch.
So user experience was very, very important in the early days of the web.
But trying to understand how that kind of thing works these days is actually quite a long way from our kind of day to day concerns as web developers. We've jumped up several levels of abstraction from this point.
So this is why this sort of thing feels kind of anachronistic to us these days, even though what telnet is doing here is something that is kind of fundamental to the networking of the web even today.
So, I usually think about the internet like this, and I think this is how most people think about it. It's basically a cloud with the word internet written in it and some arrows that go in and out of that cloud, and that will basically do.
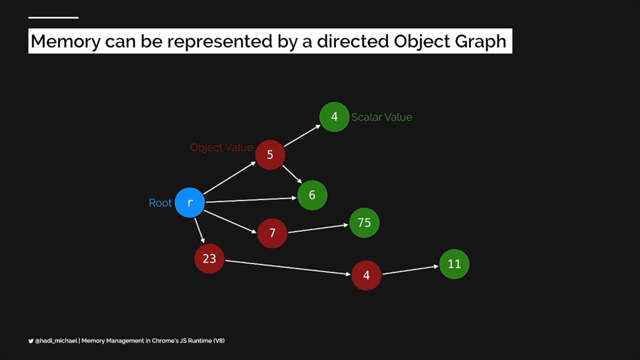
Whereas in actual fact, it's more like this. And I think the more that we actually understand how TCP works, the more we can reason about the optimizations we can make to our networking. So I'm not gonna talk about the OSI 7 layer network model you'll be pleased to know, but I am gonna just say that I think some of this is worth understanding, and maybe it's worth understanding to a slightly lower level than we typically do. So these are the protocols that we all know and love, and right at the bottom you find things like Ethernet, Wi-Fi, Bluetooth, 3G, and I think one of the magical things about layers of abstraction in networking is that I just don't care about any of this stuff. Most of you are probably connected to the web via Wi-Fi or 3G right now, and I don't really care how that works. I just care that it all speaks HTTP at the end of the day and that works.
So I think we ought to make an effort to understand this area, and I couldn't care less about this area.
(audience laughs) So let's talk about that top area and how has HTTP evolved, and how has it changed, and why has it changed in the way it has.
So we started with HTTP 1.0.
In HTTP 1.0, you would look up the address of the host that you wanted to connect to.
You'd connect to the IP address, issue a request. You'd receive your response and then the remote server would hang up.
This actually looks not dissimilar to how we use HTTP today. It took me ages to find someone on the internet that would talk HTTP 1.0 to me.
So congratulations to Google for being like super compatible with totally out-of-date HTTP versions.
No other server I tried would be willing to speak HTTP 1.0. Now I like to imagine this is a kind of WhatsApp chat. So this is how this is actually working, and the important thing here is that we have to do a number of exchanges back and forth before we actually get anything of value.
The most important thing here is that we have to ask to talk.
This is in TTP terms the signed AC exchange before we can actually issue our request for the page. Second thing is that when we get the page, we then discover it has some images on it, and we need those images.
So we have to do that whole handshake again to get every single thing on the page.
So we have to negotiate a new connection for every request and because we didn't tell Google that we wanted the about page from Google.com, we just assumed that this IP address was basically a one to one mapping with this website. And that was a pretty early scaling challenge for the web. So then HTTP 1.1 comes along to try and fix some of these problems.
It introduces the host header which means that IP addresses can now host more than one website. And the other thing is it doesn't hang up when it's finished sending you the thing you asked for, which gives you the opportunity to ask for something else without closing the connection.
So now the conversation looks a little bit more like this. We're specifying where we want the about page from, and the other end is saying that they'll actually be willing to stick around for a while in case we need something else. I'm now connecting to example.com because example.com along with the rest of the web support is HTTP 1.1.
So then we added TLS.
TLS basically makes things look exactly the same, except it negotiates an encrypted connection first. So this changes our conversation to be something like this. So now it's really long.
Like we've gotta start talking about upgrading, and then we've gotta exchange some certificates, agree on some cyphers, and by the time we actually get to request our page, it's been ages. So if we have to do this over a really long distance this can take a while.
This is the actual exchange that happens when you negotiate a TLS connection.
So, we can now reuse the same connection for multiple requests, which is good.
But moving more pages to TLS means that opening a connection can now take longer than it did before.
And we can host more than one website per IP address. So today, we're starting to see websites increasingly adopt HTTP 2.
With HTTP 2, for a single request it kind of looks the same.
It doesn't seem like much has changed.
The headers have gone lower case, and it says HTTP 2 after the request, but this really hides the enormity of the change that has happened between 1.1 and 2.
So this is how we can imagine a conversation with H2. We request the about page, but actually the server doesn't just send us the about page. It sends us some other stuff as well that we haven't actually asked for.
And then later we can request multiple things at the same time without waiting for them to come back. So this is now asynchronous and multiplexed. We can send as many requests as we want.
The server can respond to any of the requests that it receives, and it doesn't matter the order in which any of this is done.
So we've completely unblocked the tubes.
We can now use one connection and get loads of stuff done on that one connection. And the server can push us stuff that we haven't asked for, knowing that we are going to ask for it at some point because it's a resource that's embedded on the page. Now my colleague, Hooman, was unhappy with the idea that this was definitely better, and so he wanted to synthetically test that H2 was better than H1 in all scenarios. It turns out it isn't, and there are certain scenarios like connections with very high packet loss, will suffer more with an H2 connection because it's just one connection, whereas browsers will typically open up to six H1 connections per domain.
So you have more surface area to spread the requests over, and some of those connections might be more resilient to packet loss than others because they might be taking different routes through the internet.
Whereas H1, sorry, H2 will send all your requests down one connection.
That said, most Fastly customers that have upgraded to H2 have found that it is improving the metrics they care about, things like time to first paint and that kind of thing. So HTTP for the web today.
Connections are still expensive, and on average more expensive than before because we are seeing more of the web move to TLS, and that is a good thing.
I was at Mozilla the other day in London for a tag meeting, and they have a big dynamic graph on the wall that shows the proportion of requests Firefox is making over TLS versus unencrypted requests and that just passed 50% a couple of months ago, which is a really good milestone.
We can't make light go any faster.
That's something I don't think many people are working on because it seems like it's probably, probably not gonna be very successful.
So ultimately the lessons we can take from this are to terminate connections as close to the user as possible, and reduce the number of origins you use.
Because reducing the number of origins reduces the number of connections you have to set up, and terminating them close to the user means that that handshaking will take less time.
But at the same time, all of these steps of the evolution have made requests cheaper. So things like concatenating all of our content into one download so that we don't have to make as many requests, those sort of patterns are not really necessary anymore. So let's talk about terminating connections closer to the user and something that I found very counterintuitive when I started working with CDNs.
Because you imagine that if your site is not cachable, you can't distribute the content around the web, you think well, there's really no point in sending the request through a proxy because it's gonna be slower.
Objectively, it must be slower because the proxy's not doing anything useful. And actually that's not true because if you have a user that can connect to a very nearby server, and they do the cold handshake with that server, that it's like four round trips, but then that server is able to make the long connection over a connection that already exists, then, actually overall this will result in a faster response to the end user.
And in fact, it's even better if you can stick two servers, two extra servers in the way because then, if both of these edge servers belonged to the same CDN, they have the potential to use private transit or a dark fibre between those two data centres that's not available to the public internet. So if the rest of the internet is congested, then you might find that you can get your traffic through. And using fewer origins is really about putting a routing later in front of all the stuff that you want to put on our site.
My former colleagues at The FT do this very aggressively. They have a one origin strategy, so if you go to FT.com, you'll find that almost everything on the page is coming from one origin.
But ultimately behind that origin is hundreds of microservices, and a routing layer at the edge is directing traffic to each one of these. And those connections from the edge to those microservices are going over existing, prewarmed connections.
So this is stuff that works even if you can't cache your site, and all of this, incidentally, will work with any CDN, not just Fastly.
But when you're able to take your content and cache it at the edge, that's when you can achieve really impressive performance improvements. Now we've hard a lot about Progressive Web Apps, and I'm also a big fan of Progressive Web Apps. I built a Progressive Web App, and this is my score sheet. It's not quite as impressive as Twitter Lite, but it's kind of rudimentary, but it works. It's a news reader that pulls in headlines from the Guardian and allows you to read the little snippets of the articles.
But the key thing about this is that I've made a little thing that tells you about how the page got to you.
And this is the interesting bit because we like to imagine that a request is really light and a response is heavier.
The request is just like one line, fetch this file, and the response is gonna be the entire contents of the file, so you think downloading the response is gonna take more time than sending the request. But it doesn't and that's because of the process of setting up the connection. So in this case, you can see that it's taking us far longer to send the request than it is to receive the response.
And that's in fact the vast majority of the time we spend waiting for this resource. So caching things helps a lot, and there tends to be three rough categories of content when it comes to deciding on a caching strategy. There's the stuff that never changes.
And for this kind of stuff, your JavaScript, your CSS, images, things you can put a version number in the URL and often there are plugins that you can deploy if your application framework that will do all of this automatically for you. These things you can cache forever basically because the URLs are immutable.
Whenever you change the file, the URL will change as well. Then there's stuff you can't cache at all, and this really should be limited to just things that are unique to a single user.
And then there's everything else, and there's actually quite a lot of stuff in this category, stuff that has a consistent URL.
It doesn't change, but the content can change occasionally. But you still want to accelerate it as much as possible. So to consider what kind of cache policy we'll apply to these things, we need to think about caching at multiple levels. We need to think about the cache in the browser and the cache in the CDN that most of us are probably now using.
We recommend that if your content never changes, you give it a very, very long max age and throw in the immutable directive as well. The immutable directive is a relatively new addition to the HTTP spec, and it tells browsers not to reload the file, even if the user presses refresh, which is surprisingly common use case, which when it was implemented by Facebook saved them millions of requests from users just refreshing the Facebook homepage. If it's a unique response, private no-store will prevent anything from caching it.
Private, incidentally, is a nice directive for interacting with intermediary proxies like CDNs. It won't stop the browser from caching it because the browser is a private cache, but it will stop things from getting stuck in public caches. And then if your content changes when something happens, like if somebody changes a headline or posts a comment and you update the page, then you need to be able to update that page in the cache. Now we can't do that with a browser cache.
Once we've put something in browser cache, it's kind of stuck there until it expires.
But maybe we can control the edge cache, and so if you can control the edge cache, then you can use the separate s-maxage directive, which says on a server side, you can cache this for a long time.
Now what about 10 minutes? A lot of people think how long should I cache? Oh, 10 minutes, that's fine.
This is really bad idea for subresources.
If you cache things like your CSS in JavaScript for 10 minutes, that means that you potentially have users who will come to your site and get one version of the HTML and a different version of the JavaScript.
And you probably haven't tested those things together, so, you know, maybe bang? Or maybe it will be fine.
But ideally, not bang.
So you want ideally to serve the same version of all your resources.
If it's a document, it's a little bit better because you can then guarantee that all of the resources that came with that document are the right versions.
But one document may be a different version to another. And that will create really weird looking content disparities between pages.
So for example, you're on an index page and you see that an article has 400 comments. You click through to the article, and it suddenly gained another 100 comments. That's probably because the index page was cached at a different time when there were a smaller number of comments.
So ideally, we want to be able to purge all of this content from the CDN when a piece of data changes that would affect either one of these pages. So the ideal way to do this is to use an edge cache which supports purging. If you can do this, then you can serve these pages with a very long cache lifetime and then just erase them from the cache when they change. And this is a pattern that many customers, Fastly, use and also other CDNs as well.
If you do this with my Progressive Web App demo, you'll see that when you change something, when you click the button that says update content, then the pages that are affected by that, so, say the index pages and the article pages, will show a miss.
They're not in cache because we've purged that content from the cache.
Even better than this is if you can serve stale because if you purge something from a cache, then someone is gonna be inconvenienced.
Someone's gonna have to go all the way back to origin and wait for your origin server to generate that page. Now, let's say this is your homepage, and you're getting 500 requests a second for that homepage, and your origin server takes one second to generate that page.
So in this scenario, you're potentially having 500 users waiting in a queue by the time you've finished generating that page.
And so all of those users are hanging on.
It would be better if we had a stale version of that page that we could serve to those users while we're waiting for you to generate the new one.
And this is an extension to HTTP called stale while revalidate.
And if you use this, you can see it's reflected in my Progressive Web App.
This is how you add it to your cache control header. This is a completely standard part of HTTP. It's not something that Fastly have added, but we do support it.
And the number here is the amount of time that you're going to allow a cache to use the stale version before it has to go back to origin.
There's another aspect to serve stale, which is the synchronous version, and this is useful if your backend server is down. So this is where you think the content is too stale to serve asynchronously, but you do want to continue to use it if there's no response from the origin server. So this is just a matter of adding stale-if-error to your cache control header.
And the number here is how long you're willing to use the stale content for in that scenario.
And this is a really interesting decision because this number should be longer than your site is going to be down for.
So, you know, (laughs) how much of an optimist are you? I can simulate this.
My Progressive runs on Heroku, so I can just turn my dynos off on the backend, and if I do that, then my Progressive Web App will tell you that it's serving a stale version because of an origin failure.
So this kind of stuff can make a really big difference to the performance of your site, and it can push an enormous amount of the load off of your origin servers and onto servers that are much, much closer to the end user. And a lot of these techniques are supported by most major CDNs.
So now I want to move on to some of the more browser-based technologies that you can use to improve and experiment with the way you do networking on your site. So the first one is streams.
Now about maybe 10 or 15 years ago when I first started working on sites that were delivered through CDNs, I discovered Edge Side Includes and really loved it. This was a really cool technology that allowed you to cache pages that would otherwise be uncachable because the page contains some inconvenient piece of content like the user's name in the top right corner. Or maybe some personalised recommendations or something like that.
So you put all of that together in your templating engine, and suddenly you get something that's not cachable. But if you could carve out that little problem section and assemble the content on the edge server, then suddenly you can cache most of the page, and you don't have to regenerate it every time, which is really great.
Now the problem with this is that once you have assembled that page, you still have that problem of it being basically uncachable.
So it remains uncachable after that point, and it's uncachable in the browser.
So better would be if we could do this same process but in the browser itself.
And service worker now gives us that opportunity because the user submits a request for the homepage, but instead of going straight to the network, that request can go to your service worker. And your service worker can then muck about with it. It can transform it into multiple requests. It can respond with a synthetic response that doesn't touch the network at all.
So one of the things you could do is have a standard header that applies to all of your pages. And if you do this, then that header can be in cache in the browser, and when someone clicks a link, the service worker could start a response and stream back that standard header instantly. And that by doing this, you get something much more like a native app or a very, very fast experience, even whilst you're still waiting for the main response from the server.
If you use my Progressive Web App and use a debug tool like Charles here to inspect the traffic that's going over the network, you can see that when you visit a page, the URL we load from the network actually just contains the article text.
It starts with an h1.
It doesn't have an HTML tag.
It doesn't have a body tag.
All of that stuff is being done in the service worker using resources that we've already cached.
This is really cool.
Obviously, it depends on the browser supporting service workers, which are supported by some browsers. The little green flag on the edge boxes by the way indicates that Microsoft have shipped it, but it's behind a flag, so that implementation should be considered kind of nearly ready.
And the most exciting thing which John massively stole my thunder on earlier on is that this bug appeared on the WebKit Bugzilla yesterday, which indicates that Apple are also implementing service worker, hurray.
So do experiment with service worker, and think about how service worker can change the way you use the network and change the way that you can access resources that can be more cachable. Next thing I want to talk about is link preload in H2 push. So we talked about HTTP 2 earlier, and how the server can push you stuff that you haven't actually asked for yet.
And preload is kind of a similar thing in that it tells the browser that something is going to be needed later and that it should make an effort to download it as quickly as possible.
But it doesn't get pushed.
It just gets pulled earlier.
So we can send this in an HTTP response header saying this page is going to use resources/js/app.js. It's gonna use it as a JavaScript, and putting the as=script is a way of telling the browser how to optimise the priority and change the accept mime type on the request. I talked about there being multiple caches earlier on. I'm afraid I did lie slightly.
There are more than two caches.
There are actually four that we need to worry about because there's also an HTTP 2 push cache, and there's also a preload cache.
So these are relevant to these two particular technologies. And if you use preload through a CDN, then really exciting things happen.
So if you make a request to page.html, and this goes to your server and your server responds with a link preload header for app.js because you know that the browser is going to need to request app.js while it's pausing the page, that response goes back through the CDN.
And the CDN will see that you've added a link preload header and it knows that it already has app.js in its cache. So it will push app.js using HTTP 2.
So that will then sit in the push cache in the browser, and the renderer will see the page.html.
The first thing the renderer will do is it will look at the HTTP headers, and it will see that it needs to preload app.js. So it will initiate a preload request for that which will get as far as the push cache and think, ah, there is is.
So it pulls it out of the push cache and then puts it in the preload cache because we still haven't found a reason to use it yet. Then we continue to pause the HTML document, and we get to the script tag, and then we know that we need to use this file and that we can get it from the preload cache. This is a little bit complicated, isn't it? Then when we navigate to another page, we will wipe out the preload cache because the preload cache is scoped to a single page, whereas the push cache is scoped to a connection. So you could theoretically push something and if it wasn't consumed on that page, it could then be consumed on a subsequent page navigation, but that's a really bad idea.
The way these two things interact I think is kind of weird, and if you put a link header on your response just as normal, if your response goes through a CDN, then that CDN will consider itself entitled to push that resource as well as retaining the link header. If you put no push on the end, which is part of the preload standard, then you're instructing any CDN or intermediary proxy that your response goes through that it must not add a push to this preload header. So the preload header will get to the browser. The browser will still preload it, but it will preload it from the server.
It won't have any pushing involved.
Now just to make life a bit more complicated, we decided that we wanted to add the inverse of this. So we added a nonstandard extension x-http2-push-only, which will push the resource and then strip the link header. So the browser will receive the push but not do the preload. The reason why that might be useful is because there's a small possibility that if you do both, then the browser will see the preload header before it receives the push, and then you'll load the same thing twice.
So the interaction of these two things is a bit complicated. I'm not quite sure why they were both needed sort of to be considered in the same spec.
I do have a photo of the meeting where they agreed that this was a good idea. (audience laughs) (laughs) Anyway, now let's talk about some technologies that don't exist yet.
So begin furious hand waving, some more furious than others. (laughs) The first one is silent push.
So this is the idea that you can receive a web push notification in the browser and do some work without displaying a notification to the user.
Up to this point, oh sorry, I need to talk about caching here.
So I told you that there were four caches in the browser. Well, I was lying when I did that.
Actually, there are six.
(audience laughs) Yeah. - I know you're lying again.
- You'll just have to wait and see, won't you? (laughs) There is an image cache which is responsible for storing rendered pixels of images so that we can display images multiple times on the same page without decoding them multiple times. That seems kind of obvious, and it's something that none of us really think about, but that exists. There's the preload cache we've talked about already. There's the service worker cache.
This is a programmatic cache that we can interact with with JavaScript.
We have complete control over adding and removing resources from the cache.
There's the HTTP cache, which we all know and love. And there's the H2 push cache that we were just talking about, and then there's your CDN. So why is this important? Well, the service worker cache API is programmatic, so we can add and we can remove resources from it whenever we like.
So if we combine that with web push, and we have the ability to process a web push notification without displaying anything visual to the user, then we could in theory receive a purge instruction from a server and purge something from the cache in the browser.
You'll be familiar with web push notifications. These are the kinds of things that pop up when websites ask you if it's okay to show notifications, which now are like 50% of the web seems to want to do. You'll use it for Facebook or Google Calendar or whatever. If a website receives a web push notification today and tries to be sneaky and not show you anything, then the web browser will do it for them, and it will display something really ugly like this site has been updated in the background. Obviously, you don't want to display something like this every time you want to invalidate something in the user's cache.
So we now have the Web Budget API, and the Web Budget API is really cool because up to this point we've been adding all of these powerful features to the web, things like notifications, geolocation, storing large amounts of data on the browser. And every time we add one of these things, we add a permission prompt because it's very important that the user gets to decide whether they want to allow this activity to happen. And this results in the yes reflex.
Everybody just says yes to everything, and this is not in the user's best interest. The Web Budget API starts to advocate the idea that we should not ask for permission.
We should make smart decisions on the user's behalf and give differentiated permissions to different websites depending on how much you use them. So websites that you interact with a lot could gain the right to send you silent push notifications without you having to explicitly consent to that. Now this seems like somewhat of a kind of wrestling of control away from the user in favour of the browser vendor, but I think actually this is a really positive development for the web.
So if we have the Web Budget API, then in theory, assuming that you move all of your caching from the HTTP cache to the service worker cache, you would be able to receive a silent web push. In addition to purging your CDN, you could purge all of your users' browsers as well. And that would be really cool.
Another option for doing something similar but much simpler is the clear site data API. This is already supported in Chrome, and it's being kicked around the standards community for over a year now.
By using this header, we can in a single response nuke everything in the cache for our domain. So it's much more of a blunt instrument than the technique I was just talking about. But if your site has been compromised by an attacker or maybe you released some JavaScript that you really shouldn't have, and you put a really long cache time on it, I've never done that, (audience laughs) then, you want to be able to programmatically serve something that will just clear all of that stuff out of the user's cache without having to just say okay, well the best we can do is just email customer services and say if people phone up, tell them to clear their cache. So this is the new version of that, which I think we'll all agree is a much better solution. And it allows you to individually clear different parts of the storage service area that exists in the browser. So cache is kind of obvious.
Cookies is sort of obvious.
Storage refers to things like service workers, index DB, local storage, that kind of thing. And execution contexts is a fancy name for service workers and active tabs.
So if you include execution contexts, then you really are gonna kill all the JavaScript that's running on your domain.
Another thing that I really am looking forward to is something called origin policy.
I mentioned this on Wednesday at the Leader's Event, and Mark Nottingham came to me afterwards and said, you do know that this isn't really a thing yet? That wasn't a very good impression to Mark, so I've changed my slide so it now says soonish, which is I think a fairer reflection of when you might actually see this land in a browser. It might even get the name changed.
So this is very, very early stages.
But in theory, you would be able to take all of the HTTP craft that is now littering our HTTP responses, things like content security policy, strict transport security, referrer policy, all kinds of stuff which seems to be common to all the requests, all the responses, sorry, that you're delivering across all pages of your site and put all of that metadata in one place.
So the browser now doesn't need to process those response headers on every response, and you don't need to send them.
The place where you put this is a location that is well-known to the browser.
It is literally called .well-known.
That's in the spec.
In fact, this is a new standard pattern that you'll be seeing increasingly with new things coming out.
The standards community that will be putting files like robots.txt and stuff like that that have now become standardised will now live in .well-known.
Next thing I want to mention is feature policy. This is slightly further down the road than origin policy, not yet supported by any browser, but this is really exciting.
With all the new powerful APIs that have come to the web, it's increasingly a problem that we think we might do something accidentally that we don't want to do. Maybe one of our team ships a feature that interacts with web USB or web Bluetooth, or I don't know, the vibration API.
I don't think there are very many good use cases for the vibration API, personally.
Are you confident that you won't accidentally ship something? Maybe someone, a disgruntled employee, will ship a thing that vibrates all of your customers devices before they leave the company. Maybe one of your advertisers will think it's a really good idea for increasing user engagement to ship a vibrating ad.
Maybe you think there might be a vulnerability in the vibration API, and exploiting this will give attackers access to your site, even if you don't use the API yourself.
So feature policy allows you to take these powerful features of the web platform and turn them off.
And this is really exciting stuff.
This means that you can lock down your site to only using the features that you actually want to use. And you can also potentially disable browser features that slow down the rendering of all sites, just because the browser needs to support legacy functionality like document.write. So if you can tell the browser ahead of time, I'm not gonna use any of this stuff, then potentially you can take a much faster rendering path. And there's a lot more work to do on this to find all of the features that potentially could be thrown into this. For the moment, the focus is on adding key words that link to these powerful features like vibration. But in the future, there could be a lot more in there for performance rather than security. So I've covered a lot of stuff.
And in summary, I wanna say use more objects. Number of requests, ha, fine, doesn't matter. But use smaller objects.
Use fewer origins.
Don't have 50 or 100 domains on one page.
Do less bundling.
Don't go mad with the build tools.
Use smarter caching.
Use purging, use stale while-revalidate and stale if-error to allow you to cache stuff that maybe you don't think is cachable right now. Purge more and understand how to use HTTP metadata. There are tonnes of new response headers that are coming through and by using them in a smart way, you can make your site more secure, more performant, and easier to manage in its develop. Thank you very much.
(audience applauds) (playful electronic music)