Specifying JavaScript
Hi everyone.
And welcome to global scope 2021 It is July 30th or it will be when you're watching this I'm recording this a little early it's June 25th right now So hello from the past and I hope you enjoyed this talk as much as you have the talks that happened last week.
Let's get started talking about language design in the open.
What's that going to mean for us So let's go back and time The time travelers we are to 2010, for example, 2010 What was going on in JavaScript back then?
Well we didn't have classes in text yet but we wouldn't be getting it soon, so if you showed this snippet of code to someone from that time they might say "Hmm.
What language is this?" You have class in texts you have object destructuring and you have a whole bunch of other stuff here that I as someone programming back in 2010 don't really recognize but maybe I know that it's coming.
The way that I see the development of JavaScript and the whole process that we've got going on is summarized pretty well in this little comic.
And so here we have a nice little blender with a bunch of fruit, and you know these foods are coming from all sorts of different languages.
We have fruits from Java, some of the syntax out of Java, we've got fruits coming from the Functional Programming community.
We've got the fruits from Scheme and lots of other places.
Now, we put those all together and then we have this happy little blender and then we have a language.
Now eventually the dust settles and we have it out in production and people are using it.
Someone is absolutely going to come along and say "Hey, hey, get this, I've got an idea, this fruit is a pine cone".
This is an aguaje ,it's a very interesting fruit that I came across in my travels.
And let's talk about how such a fruit could be added the language.
So my name is Yulia Startsev and I work on SpiderMonkey.
SpiderMonkey is Firefox's implementation of JavaScript And yeah it's the thing that's running all of your JavaScript when you're working, when your websites are working on Firefox.
We're not going to talk about SpiderMonkey today, in fact Nicolas my colleagues spoke about the principles of JITs last week and there was a little bit of stuff in there that you could also apply to the SpiderMonkey engine, also abstracted.
Today what we're going to talk about is another aspect of JavaScript implementation which is the specification itself; JavaScript.
So let's talk about JavaScript.
The structure of this talk is going to follow basically this outline that you see here we'll talk a little bit about the history of JavaScript.
We'll talk about the proposal process how things move through the specification process that we have, and we'll also talk about what each of those parts ,each of those stages means and then we're going to dive into some really interesting topics that I really like to think about specifically language design to equip you for being able to fully comprehend the specification that we're looking at We're going to take a look at specifications and learn how to read them with a very small example.
It won't teach you everything but you should be able to get a good sense of how to get started and where to look, if you want to find more information.
Next we'll take a look at levels of language design and what it means to ask certain questions about different kinds of problems we might be wanting to solve.
Additionally we're going to take a look at what's at stake when we're designing JavaScript for the web platform.
We'll finish off with how you can get involved, places you can go to for more information and other types of things that you might want to try.
Let's get started, let's begin with what was JavaScript?
Like it was designed in 1995, it's changed quite a lot.
Well we can start with looking at the requirements, the original requirements for JavaScript.
It was intended as a scripting language for Web APIs.
A Web API is something like a set Timeout is a really common Web API you might use.
It was intended to be easy to use for both professionals and amateurs, something familiar to professionals and something that amateurs could intuitively pick up.
It was developed by Brendan Eich in 10 days with a lot of influence from his enjoyment of the language scheme.
And finally, with some of the recommendations, some of the...
rather than recommendations some of the ongoings that were happening at the time in Netscape the decision was made to adopt a Java like syntax.
I really like looking at the historical context around decisions that were made like this, so here is a quote from Brendan Eich about what the goal was for this language "We aim to provide a 'glue language' for Web designers and part-time programmers who were building Web content from components such as images, plugins, and Java applets We saw Java as the 'component language used by higher-priced programmers, where the glue programmers - the Web page designers -would assemble components and automate their interactions with a scripting language".
I find this to be a very interesting quote because it tells us a lot not only about the intention of JavaScript but it also tells us about some of the ideas around who the programmers were going to be.
So the intention was that these were going to be people who weren't necessarily skilled maybe not as valuable as Java programmers And this because this plays out in a very interesting way as we all know looking back with our vision 20 20 into the past we can see that Java has disappeared from the web It is not the component language of the web and instead it's JavaScript.
And how did that happen?
Well here's the timeline that we're looking at, from 1995 until today.
In 1995 the prototype that Brendan Eich had created was called Mocha, and it got released and we had it on Netscape and was fantastic.
Well, Microsoft took a look at it and said 'Hmm we want something like that', so they reverse engineered it and created a language called JScript which acted a lot like JavaScript but it wasn't JavaScript.
So the decision was made that we would create a standard.
A standard is a shared document between implementations that describes how a given piece of technology should work and we've got many different kinds of standards in the world; you can take a look at standards for weights, you can take a look at standards for the characters that appear on your computer and so on and so forth, standards for the USB and whatnot.
So from 1995 until 1998 we had a yearly cadence where we were releasing a new ECMAScript version every year then 1999 comes along, and there's a long period of silence until 2009.
What happened in this long period of silence and how did it influence how we design today?
Is the fundamental question of this section.
What we ended up building during that time and never releasing was something called ES4.
It was supposed to be the fourth specification, you'll notice in our timeline here, we go from ECMAScript3 directly to ECMAScript5.
In fact in between we also had something called ECMAScript3.1.
What had happened is that ECMAScript4 was designed and developed over 10 years without much implementation during that time.
So we had a huge specification that needed to be implemented by implementers; and implementers took a look at them and said "It is impossible, we can't implement something so huge without having been a part of the iterative process of design as these new language features were being developed.
This included stuff like class syntax and various other things.
It included an integration of ActionScript 3 into JavaScript, so ActionScript 3 was the programming language used in Flash and various other things.
So, because of this problem, and a lot of work went into this, but eventually it became the foundation of other proposals that didn't make it through the proces, but as a result of this you could call it a failure.
The folks on TC39 realized that something needed to change.
So they developed a process that we use today called Harmony And you'll see this this word Harmony if you're used to V8 flags syntax when they have new experimental features for JavaScript it's usually flagged as - - Harmony and then the name of the feature.
So what happened is that we moved forward with something called The Harmony Process designed by Dave Herman?
Yeah I think that's his name, Dave Herman, and what it aimed to do was address the issue that had arisen in ES4 where implementations were so far behind the specification that it was not reasonable for them to implement.
And the way that we solved this was by integrating the work of the specification and the implementation into the same process.
It also introduced a concept of Champions.
Champions are people, they're called delegates, who work for the member organizations that are part of the ECMA that helped shepherd through different proposals through this process.
Now if you want to read more about the history of JavaScript you can check out 'JavaScript the first 20 years', this is a paper by Alan Wirfs-Brock and it goes into depth about how everything over those 20 years happened.
So we got up to the point of the process in JavaScript in the history of JavaScript, let's understand that process because it is the process that we use today.
Well before we dive into that let's also talk about TC39.
What is TC39?
TC39 is the technical committee that was established as part of JavaScript being specified in ECMA International.
It is the 39th committee of ECMA international and TC naturally stands for Technical Committee.
It takes care of several standards including JavaScript formerly known as ECMA-262 We've also also got ECMA-402, ECMA-404, and ECMA-414 and those include in no particular order the JSON Specification the Internationalization Specification and the Specification for the Specification.
We operate on a basis of consensus.
What does that mean?
Consensus in our context means that no one blocks the proposal from moving forward.
In a sense this is everyone needs to agree that this solution is valid and it can be implemented.
Which is different from other standards bodies which may work on a basis of majority or other types of models that also exist.
Okay, the process.
So we can more or less talk about the Stages in terms of what they signify once you've got your proposal, your strange fruit, into the difference stages.
So starting with Stage 0, there's actually no formal process to have something be Stage 0.
Anything can be Stage 0, it's effectively a way for us to note which problems are being explored.
And people can come to us and tell us that they're exploring them, they don't have to though, you can go and fork the templates for proposals on TC39 and make your own Stage 0 proposal for a given problem that you want to solve.
We also have people doing like April Fool's Day proposals based off of this coming up with silly ideas, and this is all totally valid, these are all Stage 0 proposals.
Stage 1 means that the problem's been presented to committee and it's being explored.
Stage 2 is effectively the committee saying this probably should be in the language, the problem is valid and the solution is valid as well.
Stage 3, that's where I start doing work along with my colleagues on Spider Monkey we are doing implementations in browsers and also polyfills and various other things.
Finally, at Stage 4, there is no stage after Stage 4 and Stage 4 means that the proposal is in the Specification.
So in depth, let's take a look at each one of those and make sure we fully understand what's going on.
Stage 0, you've got your weird fruit that you want to become a feature in JavaScript.
And the purpose of Stage 0 is to allow general input into the specification.
Now from Stage 0 you naturally want to move to Stage 1, which means that the committee has acknowledged the problem statement you are exploring.
In order to do that, you need to identify a Champion, as I mentioned before a delegate from the committee who's willing to take up your cause, in other words you need to convince someone that this is a good idea and they will then help you advance your proposal through the process.
There should be initial pros outlining the problem you're solving or the problem you seek to solve, and the general solution that might solve that problem.
The high-level API should be there and the identification of possible problems, maybe there are conflicts with other proposals, or conflicts with existing libraries that you need to identify ahead of time and this is a good point to do that, as it makes for a more convincing proposal.
So, once you've fulfilled those requirements you may move to Stage 1 and the purpose of Stage 1 is to make the case, like really argue for the addition, because recall Stage 2 means we're saying that this probably should be in the language, so Stage 1 is about making the case and also identifying any potential challenges that might come up in Stage 2.
What you need to do in order to move to Stage 2 is you have to have all of the initial spec text, we're going to take a look at that later on and see how that's written, as well we need to have all major semantics and texts API is covered but you can have a couple of to do's like maybe you haven't figured out absolutely everything at this stage as you enter Stage 2 but you're going to figure them out.
Okay so you've gotten to Stage 2, so the purpose here is we are basically saying that this feature will probably go into the language,and the purpose of Stage 2 is to precisely describe everything.
The expectation is that this will be implemented, it has the same weight as if it was going to be implemented; but it's not being implemented yet, and many proposals make it to Stage 2 and they don't actually advance further.
There might be reasons discovered at Stage 2 about why they can't advance, but generally let's say we're on the happy path, then the requirements for advancing to Stage 3 are a completed spec text with no to dos in them.
Designated reviewers, so you find a couple of other delegates to go and read your spec text and make sure it's correct.
In addition the ECMAScript editors have signed off on the spec text, so they've gone in and looked at your spec text and been like yes this is correct and this fits with our current specifications stuff.
So finally we get to Stage 3 and at Stage 3 this is the time that implementers are investing in implementation.
So people are going and actually working on the specification that you've created and they're putting it into browsers and other environments.
What happens here is implementers may discover various kinds of problems with the specification that could not be discovered without implementing.
For example performance characteristics or maybe there is a web compatibility issue, often those are caught at Stage 3.
If everything goes well, then you can advance to Stage 4 and to advance to Stage 4 you need to have something called the Test262 acceptance tests.
This is our conformance test suite to make sure that all of the possible things that different implementations might try to do, that they all do things correctly.
Two compatible implementations must exist and must be shipping they can't be just like a to-do branch or something like this, they need to be shipping, usually behind a flag, sometimes not,and pull request needs to be sent to the main specification repository ECMA262 and once again the editors need to sign off.
Finally we get to Stage 4.
Stage 4 is the final stage of the process as mentioned.
It effectively means that this proposal will be published with the specification every Spring.
So from this Spring on it'll be part of that big document where we say what JavaScript is.
And that covers it, that's the whole process, and that process was describing how a specification is made, but if you've never seen a specification before, it might be a little scary to look at those things.
So, how scary are they?
Actually, hopefully not at all I'm going to walk you through one simple example of a specification and you'll have a chance to see for yourself what that looks like.
All right let's take a look at what specifications look like.
So the a piece of syntax we're going to look at is called the Post-increment operator and the Pre-increment operator, what these two are, are something you might've seen in a for-loop So you might write a for loop where you say for let X equals zero, X is less than Y, increment X by one So X ++. And what this will do is each iteration that X will be increased by one until it reaches the termination condition which is that it's less than or whatever your condition is less than Y.
So there are two different syntaxes for this, one of them has the ++ after the a and one of them has a ++ before the a.
Are these the same?
Are they different?
Let's find out by reading this back.
But first let's experiment and see what it does.
So the first case, which is a++, the post increment operator has the following behavior observationally for us, without looking at the specification, we can say that a = 0 and then we can do a ++. Unless you assign it to variable you might not notice but a++ will return the value 0.
Whereas ++a will return the value 1.
Now those are called the return value.
However the value of a in each case will be the same, the value of a will be updated to being 1.
How does this happen?
Starting with the syntax.
So, here we are looking at a screenshot of the syntax for something called an UpdateExpression.
And we're going to walk through this twice, because we're going to look at both, and consider how they changed and then it will also see how the specification helps you read it some.
So I'm going to read this aloud and tell you a couple of words you can use for each line to help you comprehend what's going on here.
At the colon I usually read as, is a, and then each new line from the first new line I read as, or.
So an UpdateExpression is a LeftHandSideExpression, or a LeftHandSideExpression with a ++, or a LeftHandSideExpression with a --, or a ++ UnaryExpression, or a -- UnaryExpression.
I skipped over some detail here You're going to see these flags all over, specifically the Yield and Await and the no LineTerminator here.
Those have specific meanings and specifications but you don't need to comprehend them and understand everything that they're doing right now.
You can ignore them safely and get a general high level concept of what these are doing.
Of course, if you're curious this is all written out in the Spec, but the short version of it is these flags yield in a way to actually expand this statement into multiple statements which also cover the cases of if this expression happens in the context of an Await, and if this expression happens in a context where Yield is possible So let's read this with our goal syntax, effectively this describes the behavior that the parser should take, as it tries to understand our a++ syntax.
As I mentioned we read from the top and we go down and we're trying to match a goal that will correctly describe a++.
So first we try LeftHandSideExpression which doesn't have ++ at the end.
So we cover the a but we're not covering ++, so this doesn't work.
If you're familiar with pattern matching languages this is a pretty similar process that's going on here.
Okay let's try the next one.
We have a LeftHandSideExpression which covers this, and then we have a ++ which covers the second half of our expression.
Fantastic.
We have found the correct like matching piece of grammar that will describe a++.
What about ++a?
Now this is going to be a bit more complicated, so we're actually going to do this in the specitself.
So here we have the UpdateExpression section of the spec.
What I'm going to do is just walk through how a++ might work.
So UpdateExpression is a left-hand side ,left-hand side, left-hand side ,none of those fit because we need a ++first.
So we go to ++ UnaryExpression, but we don't actually know what UnaryExpression is, we also don't know what LeftHandSideExpression is either but we're going to find out in a second.
So I'm going to click on UnaryExpression and find out what a UnaryExpression is.
A UnaryExpression is an UpdateExpression, hmmm, interesting.
So if I go back it's an UpdateExpression, which is why it's so important that the very first rule here is that an UpdateExpression can be a LeftHandSideExpression.
So let's find out what a LeftHandSideExpression is.
Click.
Well LeftHandSideExpression is a NewExpression or a CallExpression or OptionalExpression.
OptionalExpression, you learned about optional chaining recently, that's where that's coming from.
You can go and explore it.
Well let's go to the first one this NewExpression.
What is a NewExpression?
An NewExpression is a MemberExpression or a NewExpression.
Well, like, a MemberExpression is a primary expression or a big list, but we're going to go from the top.
What's a PrimaryExpression?
A PrimaryExpression is a this, but we're definitely not a this, unless we are.
Then I jumped down to the next one and it says IdentifyerReference Hmm.
An IdentifyerReference is an identifier, in addition to these two keywords yield and await, details, details don't get lost in the details.
It's very difficult.
So what is an identifier?
An identifier is an IdentifierName, again we're digging down deeper.
IdentifierName is an IdentifierStart or an IdentifierName with an IdentifierPart.
So IdentifierName will move back into IdentifierStart and then go to IdentifierPart, which will get us into Unicode.
That's how we get it to the a of the ++. Okay.
A lot of looping but you can see how you can click through the grammar and find out what different things are defined as one.
So we've found out about how the UnaryExpression is defined and that leads us to the LeftHandSideExpression which also helps you wrap your mind around how a is specified in the initial case the post increment case, which is the second line that you see there.
Okay cool.
That was syntax.
Syntax is what does the feature look like.
Now we're going to look at semantics.
How does the feature behav.
So we're going to start with the Postfix Operator the ++ at the end, so that's a++ and let's read this aloud.
The runtime semantics for evaluating a LeftHandSideExpression with a ++, are as follows.
One, Let LeftHandSide be the result of evaluating LeftHandSideExpression.
Recall that LeftHandSideExpression, once we go all the way down, in our case, in this simple case we'll evaluate to an IdentifierReference.
We have a reference here.
JavaScript doesn't make a distinction for programmers between reference types and values but in the Spec we do make a distinction, and reference type is effectively like an address.
You say I have some data over there and I'm going to name the address like a in our case.
So that's Line 1 Line 2 says let the old value be, and then we have a question mark ToNumeric.
Well actually, let's read it backwards, let it be the value of the LeftHandSide cast it to a numeric type.
Now there's question marks in there, what do those mean?
The question marks effectively mean that this operation could potentially fail.
So this is a shorthand to say if something goes wrong here just get out of the loop, this algorithm, an ReturnIfAbrupt completion and abrupt completion basically says something went wrong, for example, if you pass the wrong type or something like this.
Next we have step three, assuming everything went well, we say let the new value be equal to and then a bang.
What does that bang mean?
That is another shorthand which means that the following cannot fail.
This will not be an abrupt completion.
So type of the oldValue a numeric type So maybe it's an integer or a big end or something else And we're going to add to that oldValue, the oldValue is going to have added to it a unit of that type.
So we're going to increment it by 1.
Then we're going to Perform, again possibly failing, to put the value into the reference type.
So that's basically taking the address and being like okay change that value over there to this new thing.
Finally step five we're going to return the oldValue.
Recall if you do a plus plus the return value will be 0, but the value of a itself will be 1.
So this is describing exactly what's going on step by step in that process.
So if we switch over to our other example, which is ++a, we see that the specification is almost exactly the same with the exception of some naming.
A left-hand side is renamed to expression because we're evaluating a unitary expression rather than the left-hand side.
But otherwise everything is looking pretty much the same.
The main difference is step five, which rather than returning the old value is returning the new value.
And that also describes the exact difference that we saw in behavior between a++ and ++a.
++a was returning 1, the new value as well as setting the value of a to 1 and a++ was returning the old value 0 and setting the value of a to 1.
And that's it, that's semantics.
So if you're curious about this topic, there are great places to read more.
Our semantics are pretty much written in sort of a pseudo coding style, it's almost a programming language, but it's not quite, but the spec also contains a chapter around how to read our grammar, which is probably the more complex part of the task of reading the specification.
You can read about that in that chapter, and you can also read more generally about Backus–Naur form grammars called the BNF grammars.
This is something that applies to a lot more languages other than JavaScript.
And we sort of build on top of that and have a couple of quirks around it.
Finally, I think the best way to learn the spec is to go to the spec and start clicking through things.
Maybe you're curious about how a certain feature works in the spec.
Well, you can go to the spec, find that feature and just start clicking around and seeing what you can learn within the spec about how it's implemented or specified rather.
All right.
Let's get to our next segment, which is levels of language design.
So I wasn't too sure how to word this.
We'll go with this for now, but let's talk a bit about what goes into language design decisions and what kind of questions are we asking?
So the thing that we need to ground ourselves in is that we should be solving a problem for users somehow.
Take a considered the fact that our stage, one of the stage, one of our process is about solving it.
And I also included here a little quote from Charles Eames.
That design depends largely on the constraints.
This is true in any realm of design and it's especially true in programming languages.
We are constrained by certain situations.
We need to design to those constraints and also to those problems.
So, a couple of things to think about, when we're generating solutions to problems, we start with a problem in stage one, we might take various approaches to how to generate the solution.
We might want to take a look at what already exists in the ecosystem.
This is really common for us.
We call it paving the cow path, which means that users of JavaScript have gone and written libraries to solve problems and we come along and look at those libraries and say, yes, that probably should be in the language.
Sometimes we want to rapidly generate a lot of different solutions and figure out like what's the best shape for a certain problem.
And then you might see a proliferation of different shapes of a proposal.
For example, you might take a look at a pipeline operator and how there are multiple different possible ways to solve that problem with different syntax.
Another thing is that sometimes we don't fully have a specification, we don't fully understand the problem we're trying to solve.
And in that case, we may go and ask people like, what do you think we should be solving about this problem space?
In addition, whenever we generate a solution, it comes with its own set of questions.
It's not enough to just say we have a solution, we also have to evaluate that solution, especially if there are multiple ways to solve the same space.
So evaluation of the solution depends on the question.
Sometimes if you're designing something that needs a formal proof, then it makes sense to go and make a formal proof of that problem.
That's actually pretty rare in our realm except for places where we've got security questions or other things like that.
Other times we want to do a user study because what we're trying to resolve is maybe some ergonomic issue.
And that's much more about users than it is about formal proofs.
But it really is difficult to balance all of these questions and balance all the different ways that we might evaluate them if we don't have a framework for thinking about them.
So let's talk about a framework for considering how to approach different questions that may arise in language design.
Now this comes from a really great paper called 'An interdisciplinary approach to language design'.
It's linked in the slides.
I'm going to refer to this rather informally as buckets of investigation, because I find it easier to just call it that, rather than categories or something else.
Let's take a look at what those three are as defined in that paper.
There are a formal properties of the programming language.
There are observational properties, and then there is the impact on the programmers themselves.
So let's start with formal properties.
Now we have one question that you might ask that is a question that folds into the formal properties bucket is it sound or rather correct?
So what does soundness mean?
What does correctness mean?
And you'll notice that I've got two emojis there and a thing that says grows in the ground.
You could create a sound statement to put these three components by saying that a sweet potato is a potato and all potatoes grow in the ground.
That's invert that and say, all potatoes grown in the ground, a sweet potato is a potato, therefore all sweet potatoes grown in the ground.
That is an example of a set within a set, which is a kind of proof you can do.
And it can be really useful.
It's one that's useful that you can improve certain properties of things.
You actually use it, if you use class based inheritance, it depends on how you do the class based inheritance, but as long as you've got an is a subset relationship, that's what that is.
You also want to have formal properties in place when you have security guarantees.
An example of that is a couple of years ago, we had a security flaw revealed called Spectre, which meant that programs running in the same process, could effectively see each other's data.
And that has had huge impacts for us when we design different APIs.
For example, the design of Realms, a proposal that you'll hear about later today from Leo Balter has been impacted by that.
And it has influenced the fact that this is now an integrity proposal, which ensures that things are working as you intended, rather than something that is necessarily ensuring that no information is leaked to a potentially malicious party.
In addition to that formal property, something else we can look at is can we guarantee that the code that a user is writing will be correct according to a given contract?
One of the best examples we have of that is Promises.
Prior to promises, you could use a callback with a polling structure.
And today, instead of doing that, which you had to write out all yourself, we have promises at which say once this promise resolves, do this action, if it fails, do this other action.
And the final form formal property, which is interesting to think about is Turing completeness.
And I got my animations mixed up, Turing completeness is formal property that you want to think about when you're designing your programming language.
And of course one of the languages that is not Turing complete is Datalog.
Datalog is a subset of prolog and the decision to make it not be Turing complete was so that we could have other properties because Turing completeness, this is really a lot of power for a language, and by giving that power up, what Datalog got in return is that it is a fully sound and complete language.
What does completeness mean?
So soundness is the ability to prove a truth of some sort.
Whereas soundness is the ability to prove all truths in a given system.
What that means is Datalog is covering the entire surface that it can within the system that it's describing, which is really interesting property.
Now one thing is that sometimes people will come along and say, 'oh, but if it's not Turing complete, it's not a programming language'.
Well, this isn't a useful way to look at programming languages.
Again, we should always be thinking about what's the problem that we're solving.
And if we can reduce the power that we use to solve that problem, we reduce the responsibility that we pass on to the programmer in order to have to go add it themselves.
A lot of API is focus on making sure programmers are doing the correct thing, even if a language is powerful enough to allow you to express everything.
And then there are programming languages that don't give you all that power, but ensure that you're writing correctly anyway.
Datalog is an example, HTML is an examp.
CSS is an example, and I consider them all to be programming languages.
Next up the bucket of observational properties.
What are those?
So observational properties include things largely related to implementation questions.
So is the design efficient, we're talking about the specification, is it permissive enough to be performant?
A good example of this in recent history of the TC 39 is the regular expressions match indices proposal, which had to be redesigned because once it was implemented in stage three, we discovered that it was slowing down all RegExs.
And that there wasn't really a great way to fix this.
So what we did is we split it out by giving it an extra flag, and now we can optimize as we did before.
And we have this separate bucket for saying, okay, this will probably be a bit slower, but it's fine.
Another example of observational properties is whether or not the programming language is portable between environments.
So, one thing that we talk about a lot on TC 39 is if a design is portable between for example, node in the browser, uh, famous, uh, in compatibility is module syntax.
So node describes modules differently than browsers, which use URLs and node uses like string identifiers.
So something like this can be a significant.
Um, design decision, depending on how the feature is intended to work.
Finally, one last example, there are more examples.
This is just a subset.
Uh, another example is, is this design something we can optimize in a jet and Nicola did a fantastic talk about it last week.
I encourage you to go and check it out and think about this from a language design perspective this time.
All right.
Our last.
What's the impact on programmers.
So, uh, this is something that if you're a programmer yourself working in JavaScript is probably the surface area of language design that you're most familiar with because you can experience it all the time in your day job.
So one question that you might've come across is, is this something that I can learn?
And is this something that I can teach to other people, uh, is my code easy to comprehend?
So this is a dimension of, um, designing for programmers that might be called teachability or learnability, but it's also related to the consistency of the language, because the more consistent a language is the easier it is to go from something that you know about the programming language and say, Hmm, it works like this and this situation.
Well, I can just say that it works like that in this other situation.
And it works.
So something like, um, a list is a really learnable language because it's quite consistent and it's got quite a small subset of programming of programming language, um, building blocks that you need to work with as a program.
Another one interesting thing from the JavaScript world is records and topples.
So you heard about that last week.
And this is an interesting proposal because it's introducing immutability to JavaScript.
Now, how do you teach that?
That's an interesting question.
And it's one that the champions and the authors have been working with, and I encourage you to go and check out their proposal to see how they're doing that.
Another question is, is the, is a design.
Um, is this a design that is prone to errors now, uh, recall that we talked about promises as an interesting format.
Um, structure in the language that ensured that the programmers were following the contract correctly, but then we've got, async await.
Why do we have async await?
The problem with promises is that they were not really ergonomic.
There were pretty hard to look at.
So people were thinking, Hmm, it would be great to write a synchronous code as though I was writing synchronous code.
So we introduced the construct of a.
But that actually introduces another problem, which is error.
Prone is, uh, from looking at a piece of code because JavaScript isn't typed, you can't tell if a given statement or expression results in a promise.
So that means that you might miss a few things and your program might work, but it doesn't cause any errors, even though it's doing the wrong thing, this is a design trade-off that we have to make, and there are different reasons why we make different design trade-offs.
It's a really interesting case.
Yeah.
The final one that I'll bring up is, is it expressive again?
You had a really fantastic talk last week about optional chaining and nosh coalescence now optional training.
Um, what it does is it adds away in the code to say, Hey, all I'm doing here is checking if the field exists and if it does, I'm continuing on, otherwise I'm going to do something that is a fallback, usually with the turnery statement or something similar like this plus now we've got Nelish coalescence, which in a sense is, uh, adjusting for the fact that we have an interesting way of thinking about truth and falsely values and knowledge.
Coalescing allows us to sort of make that more restricted.
All right.
So that covered our language design principles bit, which is something that you can actually take to other languages.
It's not JavaScript specific.
It's a, it's something that you can think about in relation to any language.
Now we're going to get specific to JavaScript.
We're going to talk about what's at stake for designing for something like the web class.
Now, um, what platform is made up of a number of stakeholders.
We have the vendors.
Uh, so all the browsers, we also have developers such as yourself, and we have users of the web people who do not work with technology themselves, but they use the web and they use it for their daily daily lives.
In addition, we have other standards bodies who have to interface with our staff.
So, this is sort of the constellation that we've got, and of course the W3C and what wig and others have their own, um, interfaces with users and developers, et cetera.
This we're not going to focus on.
We're just focusing on All right.
So, uh, in order to sort of think about how we design things as a platform with like different browsers and different standards, organizations and developers, uh, an interesting document was written called the extensible web manifesto.
Not everyone signed it.
A number of people ascribed to it.
Some people don't, but it had some interesting high-level ideas about how to design for the website.
So I have a couple of things highlighted here.
The standards process should focus on adding new low-level capabilities to the web platform that are secure and efficient.
The web platform should focus on low level capabilities that explain existing features such as HTML and CSS, allowing authors to understand and replicate.
The web platform should develop, describe, and test new high-level features in JavaScript and allow web developers to iterate on them before they become.
Which creates a virtuous cycle between standards and developers.
In fact, it's why we're here.
We want you to be able to interact with the standards process and understand what the heck we're on about, but there are a couple of other things here.
One is we want to add new low-level capabilities so that let's say you're a library author.
You can build the library that does the thing that you want it to.
In addition, by having lower level capabilities that explain underlying features of the web platform, we hope to make the web platform a uniform, interesting place to work and to make your applications.
So that brings us to a rather important topic, which is backwards compatible.
Now looking at it specifically from the JavaScript side.
One thing that we're interested with backwards compatibility from a design perspective is that there are certain properties of programming languages.
We call them of the programming language.
We call them an invariant.
That we don't want to lose.
And if we add certain features, those invariants will go away.
One example is the JavaScript should be poly fillable.
So, uh, when we were designing the module system for JavaScript, that was one of the key things that, that was maintained in the language.
Because if we had just done any design, it may have been possible to say that the modules load before any polyfill could be inserted, but instead of we designed it in such a way that you could first load a polyfill and then have the entire module tree load.
So that means, for example, if a browser makes a mistake or maybe if a browser is slow in implementing a new feature, you can still install a polyfill and have all of the modules that you load work as intended.
So that's an example of an important invariant.
Currently, this is undocumented, but we're working on writing down all of our invariants so you can understand them as well.
It'll go on the TC 39 repository when it's ready.
So that was the TC 39 specific view, uh, on our design and backwards compatibility, but there's a broader one and a more important one, arguably, which is backwards compatibility and the broader group of users.
Many people rely on the internet for their livelihood or to study, especially today, given coronavirus and those services are incredibly important.
We're talking about banking services, educational services, hospital services.
Not everyone has the ability to upgrade their operating system or their browsers.
So if a standards, organizations stop paying attention to what happens to older browsers, it means that potentially critical services will start to break and they may not have the money to then go and upgrade their services.
So the browser has to always be able to run the programs that it ran before, just as well as it did back in the past.
This is one of my favorite examples of the impact of backwards compatibility.
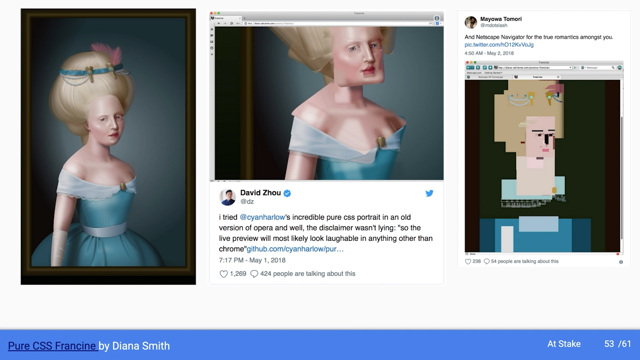
It's a project called CSS, Francine, pure CSS, Francine by Dan Smith.
And it's really a work of art.
It's quite beautiful on the right.
You see the intended, um, representation of this piece.
But at the time, even in 2018, not all browsers supported the same CSS properties.
And she had one people that she'd only designed it for one browser Chrome.
And it might look a little funny in places other than Chrome.
So people started looking and what they found is as you go back in time, all the way to Netscape on the left, you get more and more modern.
As a result, the best part about this, it still works.
You can still see it on a Netscape browser from goodness who knows how long ago.
So that also brings us to an important point, all of this discussion, which is that we as standards organizations, and also as developers have a limited view onto what the world is for everybody else.
There's a group of users who are in effect kept outside of the design process.
But because we have the view into the design process, it's our responsibility to ensure that we don't make a bad experience for those users who are relying on us to make sure that they have a functioning performance secure web.
Why not break the web?
The costs are impossible to estimate.
We cannot know how much it will cost all of the small schools and small businesses that would need to upgrade.
If we broke.
In addition, it's easy for us to rename things.
We can just say this happened multiple times.
So for example, Array.prototype.contains a proposal we had a little while ago was renamed to Array.prototype.includes due to a web compatibility issue breaking the web affects users, disproportionately compared to developers also compared to brown.
If you want some more grounding on this topic, I highly recommend watching dear developer by Charlie own.
It's a very direct talk, but it's also, I think, a healthy discussion for us as an entire technical community to have about what it means for us to develop the way that we do.
Alright.
That brings us to the end of this talk.
And I want to talk about how you can get there.
So everything's on, GoodHub go to get hub.
It's the get hub.com/tc 39.
And there, you will find Ekman 2 6, 2, which is our main repository or the specification itself, our proposals repository, which enumerates all of the in-progress repositories as well as the old ones, except for the ones that are really old.
Test 2 6, 2, the conformance test suite of the agendas for our meetings, our notes, and also other specifications.
We work on like ECMO.
Uh, the places where you can contribute.
Well, one thing that I recommend to everyone is that they start with the, how we work repository.
We've got documentation there about the terminology that we use and the different kinds of processes that we, um, uphold, uh, in addition, uh, what you may be interested in are things like how to review proposals, how to give good feedback, et cetera.
And that's all written there and it's living documentation.
So we're updating it.
In addition, you can go to GitHub and find a proposal you're interested in.
You can go to discourse, which is where you can talk to other people about new features or ask questions about specification.
And finally matrix is our chat where you can join us and talk to us about JavaScript and that's it's uh, thank you so much for listening to this talk.
I hope you have a fantastic day.
And you've learned a lot of really interesting things about the language.
And I hope to hear from you and maybe your ideas for a new feature or new language.
Language specification can be a bit of a mystery. This talk will introduce the stages of the TC39 process for introducing a new language feature to JavaScript, and some high level concerns around our design process.