Principles of Just-In-Time compilers.
Hi, JavaScript gets faster as it executes.
What a strange behavior, this this something rarely seen in computers.
Without looking into each optimization of JIT compilers, we will have a look at what give JIT compilers their super powers.
Before digging into JIT optimism, we will answer one of the most asked questions, why aren't JIT compilers compiling everything from the beginning.
To answer these questions, let's consider a random JavaScript function with no loop.
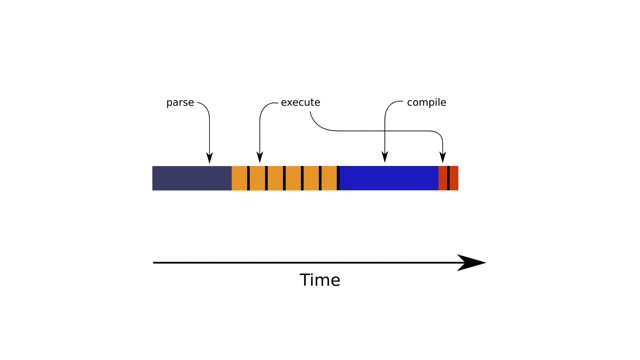
When this function is first called we parse and execute.
Next calls, we keep executing it slow a few times.
At one point we have one slow iteration, which is where the JIT magic happens.
And after all subsequent executions are faster.
When's this function is first called.
We parse it and execute it.
Next calls, we keep executing it slowly a few times.
At one point we have one slow iteration, which is where the GIT magic happens.
Yeah.
After all subsequent executions are faster.
If the JIT were to be eager, we will parse, then right awake compile, such as all executions are fast.
As you might see this, this is not always the fastest case, this depends on whether you prefers throughput over responsiveness, and it depends on the number of times the function is expected to run.
On a web page, a user expects a fast response, or it will browse away, while on the server, the same code answers thousands of requests and a steady performance is important.
Thus, one might expect that you will have a different heuristic between a JavaScript engine used in a browser and a JavaScript engine used in a server.
A simple heuristic, which is never implemented as cleanly in JavaScript engines is to guess the time the engine will spend executing each function.
If by compiling the speedup we gain compensates for the slow down of the compilation, then scheduling a compilation is worth it in terms of throughput.
Now, we knew how just in time compilers choose to compile on demand, instead of compiling ahead of time, it is time for us to look at what a just-in-time compiler is doing.
Before jumping into more detailed explanation for the next 16 minutes, we have to understand the control flow graph.
The following blue block is a sequence of code.
We represent branches with edges between these blocks.
An if statement will see the code prior to the if, and the condition oft the if in the first block, which can branch to the then part, or to the else part, which are both joining back after the if statement.
If the else branch breaks the control flow by returning, then we do not have any edges back.
A JIT is all about specializing some code based on its input, removing what is used less and optimizing what remains.
To know what is removed, let's first, have a look at what is executed.
The first thing to execute JavaScript code is the interpreter.
In general, an interpreter is a loop with a switch statement.
The loop iterates over every instruction to be executed, and the switch statement dispatches the instruction to the code responsible for decoding and executing it.
From this, a simple method JIT consists of removing the costs induced by the interpreter.
Thus instead of having the interpreter to dispatch every opcode, the Git replaces the opcode of our bytecode by the corresponding assembly code.
For each opcode we copy the interpreter path used to interpret it and reconstruct the control flow of the bytecode.
So this small modification has a huge impact!
Nt only do we remove the cost of branching to execute each opcode, but we also specialize the code extracted from the interpreter with the opcode parameters.
Still some opcodes need a lot of code.
Let's look at one of the most versatile character of JavaScript is the plus operator.
The plus operator is, in JavaScript, one of the most overloaded operator, it can add floating point numbers, add integers, a specialized by all the engines.
Concatenate strings, convert an object into a string before concatenating a number to it, and even mutate the DOM.
Yes, you're near right in JavaScript, nothing forbids you from making any side effect in any of these functions.
As you might guess, most of the time the plus operator is either summing numbers or concatenating strings, but rarely both.
Ideally, we should only cherry-pick the pieces of code which are used and discard the rest.
But this is premature for a simple JIT.
This is a technique called "inline caches" or "trace on violation".
This technique is about generating code on demand.
Instead of compiling the entire function, which can be time-consuming, we compile only the branches which are requested.
Thus, if the first time we've visited this code, we detect double addition, we will execue it.
We will compile and simplify the code corresponding to this double addition.
If after we detect a string concatenation we will execute it compile and simplify the branches dedicated to the string concatenation however, we will need a fallback path to hndle all the cases which are not yet generated, But how removing unused branches optimize the execution speed.
When to CPU sees code, it tries to predict which branch is going to be executed However, branches are not equal in assembly code.
One fall-through while the other will discard a bit of its instruction pipeline.
By moving away the unlikely code we help the CPU making the right choices.
By loading less instructions as branches are no longer interleaved, inline caches are great for extracting the existing code.
but they are not restricted to it.
One thing possible when dealing with pure operation is to using inline caches as a caching mechanism.
When we have a complex function such as property lookup, which is mostly pure, we can generate a much simpler code by specializing appropriate to lookup for each object type, we can generate code, which shakes the object type.
And right away returns the location of the property.
So, good news.
We have reached what a simple JIT compiler do as a compilation target, which is to remove the dispatching cost of the interpreter and use line caches for code which has a lot of variations.
This mode of compilation is what SpiderMonkey uses since 2013.
And what the V8 team recently announced uder the code name sparkplug.
So far, JITs are just warming up.
They are much more powerful than that.
The optimizing JITs learns from what the simple JIT is doing.
The simple JIT generates in line caches.
Each time a code path is necessary.
The optimizing JITs piggyback on this a prior knowledge to specialize the code accordingly based on the hypothesis that it is unlikely to change.
If there is no entry in an inline cache, we can deduce that the branch, which is in the code written in JavaScript is actually never used.
For example, in a function from a JavaScript library, where a function is only used in a specific matter, we can move away all the corner cases which are never encountered.
In spider monkey, this optimization is simply named branch pruning.
Inline caches also provide valuable information when there is a single entry.
When there is is single entry, we can take to code compiled by the inline cache, and reuse it in the compilation graph of our optimizing JIT.
For example, knowings that the previous insertion is an addition and not a concatenation, remove the need to check that we have numbers as operands of the following operation.
For example, knowing that the previous insertion is an addition, and not a concatenation, the need to check whether we have a number as an operand for the next instruction is no longer needed.
Why this sounds trivial, there are many others with many other opportunities.
By specializing, we can do more optimization, suggest constant propagation, folding consecutive operation, replacing object fields by stack variables.
Computing ranges of math operations to use integer math when possible.
Another optimization, is the unreachable code elimination.
Why this sound similar to branch pruning it is actually complimentary as some code, might be unreachable based on parameters provided by the caller.
So when in lining code of one function into another, we might discover that a branch can never be reached in the context of the caller, while it might be used in different contexts.
Unreachable code eliminations, follow other optimizations, such as constant folding and range analyses, which help pre-compute whether a condition is always true or false.
The optimizing JIT is making profiling, guided optimization.
It is much more capable than static compilers at this task.
When a static compiler performs a profile guided optimization, it does not have the ability to remove anything.
It just moves the code far away to hint the CPU that the code shall not be loaded and its instruction cache.
An optimizing JIT keeps the conditions, and simply removes the branches.
The Reason we can do that is because we have the option to resume in yhr Simple JIT or in the interpreter.
Resuming in the lower tier of execution is called a de-optimization.
And this is the nemesis of optimizing JITs.
A de-optimization is quite complex.
As the optimizing JIT is removed from the execution stack, and replaced by what the frame of the simple GIT would look like.
The location of the variable of the optimizing JIT have to be mapped to the locations of the variable of the variable of the simple JIT.
This onstack replacement is quite costly.
Not much because of itself, but because we have to wait in the simple JIT, while the optimizing JIT is getting confident enough to recompile.
So far I only mentioned how JITs are cutting branches, but keeping conditions.
JITs do not have time to prove all the properties which hold within a program.
Moreover code could be headed dynamically, invalidating, any proofs that we made so far.
Still, there is a trick which consists of moving the conditions from one function to another, which are producing the value, which have to be checked.
To understand how all this works, we have to look at the data from where it's coming from, such as a property read.
The optimizing JIT will move the condition out of the generated code to be executed into sources of the data, such as a property setter.
Thus, when we have value, which is used in the optimized code, we know the condition is true..
And that it holds.
However, if the condition fails, while setting the property, then the generated code is no longer valid and if the invalid property value were to flow in the compiled code it called misbehave.
So generated code has to be invalidated and discarded.
A fuse is triggered, and converts all the edges into de-optimizations.
Invalidateding code forces us to de-optimize and resumes the execution in the simple JIT and wait for another compilation to resume our fastest running speed.
Okay.
Let's summarize.
JITs are all about making trade-offs between compilation speed and to speed up the generated code.
While there is a lot of logic in JIT compilers, their goal is to reduce the number of instructions to be executed, and functions, which are executed the most frequently.
Removing branches is the most effective way to enable more optimization in a JIT.
Either by removing the obvious overhead, such as in the interpreter by recording the path, which are needed, such as in an inline cache or by filtering the branches when they are unused or unreachable.
As a JavaScript developer, your interest is not to remove all the branches, but to make sure that where the performance is needed, that JIT compilers will have the ability to remove a maximum amount of branches.
You can do so by reducing the number of types for each instruction and making sure is that branches can be removed when a function is inlined.
Also nothing forbids you from making your own simpleton in JavaScript.
Thank you.
JavaScript gets faster as it executes! Just-In-Time (JIT) compilers are used in all major JavaScript engines to improve the speed, but how do they work? By understanding the principles of JIT compilation, web developers have the opportunity to optimize their code.