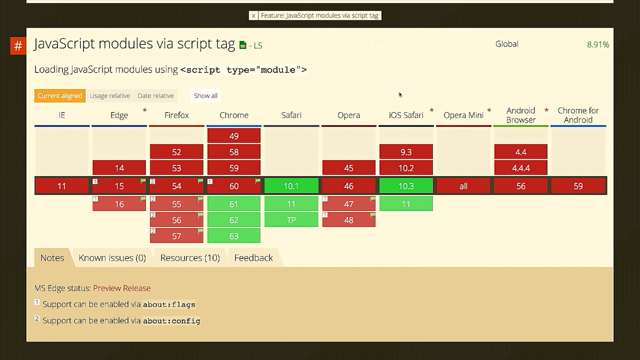
Architecture Patterns for App Modernisation

Introduction
Simon Warden, Principal Engineer at Terem, kicks off his talk on architecture patterns for application modernization (AppMod). He emphasizes the prevalence of AppMod in enterprises dealing with legacy software and his experience in the field.
Software Architecture Basics
Simon highlights two common pitfalls in software architecture: the belief in a single solution and excessive dependencies. He advocates for pragmatic decision-making, considering team composition, requirements, and the application's lifetime. He emphasizes keeping architecture simple and avoiding unnecessary complexities.
Cloud Hosting Options
Simon briefly compares serverless options like Cloud Functions with containerization using Docker and orchestration tools like Kubernetes. He advises leveraging cloud-native solutions for databases and other services to simplify architecture.
Application Modernization Patterns
Simon introduces eight AppMod patterns: Big Ball of Mud (pattern zero), Strangler Fig, Facade, Backends for Frontends, Eventify, Microservices, Micro Frontends, Multi Monolith, and Parasite. He emphasizes that these patterns are not mutually exclusive and should be chosen based on the specific situation.
Pattern Zero: Big Ball of Mud
Simon cautions against the "Big Ball of Mud" pattern, where applications lack clear structure and become difficult to maintain. He uses a startup's experience with an unsuitable open-source package as a cautionary tale. He emphasizes the importance of understanding problems deeply and crafting simple solutions, rather than prioritizing code production.
Pattern One: Strangler Fig
Simon describes the "Strangler Fig" pattern, inspired by the tree of the same name. This pattern involves gradually replacing an old application by building a new one alongside it and migrating functionality piece by piece. He explains how this long-term strategy allows for incremental modernization without disrupting the existing system.
Pattern Two: Facade
The "Facade" pattern addresses situations where an embedded legacy component cannot be easily replaced. Simon explains how a thin translation layer can be used to interact with the legacy system while presenting a modern interface to newer applications. He highlights how a well-designed interface can persist even after the legacy system is eventually replaced.
Pattern Three: Backends for Frontends
Simon discusses how creating tailored backends for new frontends, such as mobile apps, can inadvertently lead to AppMod. He uses a startup's experience building APIs for a mobile app as an example of this accidental modernization pathway.
Pattern Four: Eventify
The "Eventify" pattern tackles bottlenecks in legacy systems that are difficult to scale, such as mainframes. Simon explains how broadcasting events from the legacy system and handling them in more scalable cloud-based systems can improve performance and enable event-driven architecture.
Pattern Five: Microservices
Simon delves into the popular "Microservices" pattern, emphasizing both its benefits and potential drawbacks. He cautions against blindly adopting microservices without strong engineering practices, as it can lead to complex infrastructure and slow down velocity. He highlights the importance of carefully considering the suitability of microservices for a particular organization and context.
Pattern Six: Micro Frontends
As a complement to microservices, Simon introduces "Micro Frontends," a pattern that addresses frontend bottlenecks by allowing teams to own and develop independent frontend components. He explains how leveraging the DOM and the PostMessage API enables communication between these components.
Pattern Seven: Multi Monolith
Simon challenges the idea that monoliths are always bad, arguing that sometimes building a new, well-designed monolith can be a viable solution. He stresses the importance of avoiding past mistakes and prioritizing long-term maintainability over short-term velocity. He defines technical debt as prioritizing short-term velocity at the expense of long-term velocity.
Pattern Eight: Parasite
The final pattern, "Parasite," addresses situations where access to legacy systems is limited or nonexistent. Simon shares an experience where his team built a mobile app that interacted with a legacy web application without direct access or support. He acknowledges the unorthodox nature of this pattern and emphasizes the importance of clear communication when using it.
Key Takeaways
Simon concludes his talk by reiterating the importance of making pragmatic decisions, keeping things simple, understanding the problem space, and communicating effectively with stakeholders. He encourages the audience to reach out to him for further discussion.
Good morning, everyone.
Really great to be here.
I was here Last year, just as an attendee in just some really great talks, very honoured to be here today.
I appreciate the generous introduction, Sharky.
So today I'm here to talk to you about architecture patterns for application modernization.
Bit of a mouthful, at times you might see me calling it AppMod for short, so nine syllables down to two.
What is application modernization?
So it's just the process of updating older software to improve performance, usability, and to align with current business needs.
Now, this can happen if you update old software, or if you're building new software that includes some old systems as components of the new software.
And we see this a lot in enterprises and big businesses where they've been using software for decades and you can't just rewrite everything to align with new trends, to update everything to a single trendy programming language.
So quite often, when being pragmatic, you've got to work with old technology and there's a number of ways to do that.
So I'm going to present some patterns for you.
As Sharkey mentioned, I work for Terem, which is a software services provider.
And that allows us the opportunity to see a lot of different approaches across different industries.
Across different organizations, and we see what works and doesn't work.
So having done this for quite a while, I've made all the mistakes that can possibly be made, or it feels that way.
I'm sure I'll make some more though in the coming years.
But hopefully you can learn a bit from some of the things we've seen and some of the approaches that we've seen, that we've seen work.
Before I dive in too much, I'll just briefly talk about myself, not too much, we've already had an intro there.
My name is Simon Warden, 20 odd years of architecture experience, again a lot of those making terrible mistakes.
Can talk to you about those in another talk maybe.
Apart from that, Principal Engineer at Terem.
It's really just a fancy title for someone who architects systems and works with our clients to make sure we deliver strong outcomes for them.
We deliver product teams that include sort of design, business analysis, everything, just help, we help our clients push products out, and we really thrive in environments where it's normally hard to be agile and get things out the door.
So you can have very slow moving organizations, governments definitely are guilty of this, large enterprises, a lot of red tape, a lot of things to navigate around.
We work well in those environments.
Yep, that's what we do.
I'm just going to briefly touch on the personal side and then I'll dive into the content.
Some of my favorite things, it's me with my two boys.
We love hunting Pokemon.
If you know any good spots, let me know.
They love trips to the city.
We live a bit out west but they love coming in to catch Pokemon.
It's their favorite thing.
Brazilian Jiu Jitsu, one of my favorite things.
It's really just a way to violently cuddle with your friends.
Really good exercise.
If you've never tried it before and you're looking for a way to get fit, you have to work hard when someone's trying to strangle you, that's all I'm going to say.
And, I love riding vehicles with one or two wheels.
More than that, it's just transport.
Less than that, it moves the soul.
It's me on an electric unicycle.
Pushbikes and motorbikes are great by me too.
Okay, before we dive into app modernization and patterns around that, I want to give some sort of high level Software Architecture Basics, really.
This is just a very brief set of principles that I've seen work really well when followed, and things go just disastrous when they're not.
I'm going to mention two things that you really shouldn't be doing, and two things you should do instead.
The first one is, do not buy into this idea that there's only ever one way to solve a problem.
We're not mathematicians here, we work with software.
You can call it an engineering discipline if you like, it's not always engineering.
Like any form of engineering, there's generally more than one way to solve a problem.
And some of those ways are going to be good ways.
That achieves strong outcomes, and others that won't be so good.
Just because you've always done things a certain way doesn't mean it's the right way.
For the current application you're working on, just because your organization has some standards and principles generally followed, you might want to reassess them sometimes.
You can't always jump into solution mode, and, just start banging out code, that's not going to necessarily give you a strong outcome.
And the next one, and this is one that is just becoming worse and worse over time, is excessive dependencies.
Now, this can happen at the code level, if you just add, any time you need to solve a problem, add a package for that, and that package references 20 other packages, each referencing another 20.
And it all seems good, because in the short term you get this crazy velocity, right?
You can move fast, build whatever you want.
Long term, you end up with so much, so many packages to update, some which stop being compatible with each other.
So just be careful any time you rely on someone else's code.
It's definitely not a bad thing to have external dependencies.
That can definitely be at the architecture level where you're adopting certain cloud services.
It could be at the code level with a package.
Just be careful that you slowly add things with good purpose and in a way that is maintainable.
So things to do instead, make pragmatic decisions.
Again you can't make the same decision every time, you've got to think about the context you're in.
So that means being aware of your team composition, how senior are people, how junior are they, what is their preference?
Sometimes taking into account what teams want to do is super important.
You don't want to impose things externally sometimes.
But also think of your requirements, the timeline, how quickly does this need to get out.
And what is the lifetime?
How long will this application live?
How likely is it to just need to be standing and up to date in 10 years, 20 years?
We find ourselves with a lot of bad legacy software.
Not all legacy software is bad.
A lot of the times they just didn't foresee the lifetime and made decisions that were not sustainable in the long term.
So just be careful with those things.
And just finally, keep your architecture as simple as possible.
So that's the counterpoint to your dependencies.
And look, any time you're crafting a cloud native solution, the advice you'll get from some cloud vendors is just maximize utilization of all the tools and all the services.
That's generally not the right approach.
Keep your architecture simple and only use what you need because every additional piece to your architecture is something someone has to maintain, maybe you, maybe someone else, in the long term.
Always go for simple and pragmatic decisions where you can.
Now this next slide, I'm going to be brief because it could be a whole talk on its own.
When you're working with the cloud, what are some high level options you have for just hosting your code, getting your code out there?
There's this conversation around serverless versus containerization.
It's actually a topic I've thought about a lot and I have crafted content around this that I'm just going to sum up very briefly here, without going into too much detail.
If you just really need to get something running in the cloud very quickly, Cloud Functions are really great for that.
All the major providers will offer variations and flavors of this.
Need to get something up very quickly, it's great.
If you need something though that scales well cost wise, generally not your best option, you will end up paying more for something hosted this way, compared to, a container, or something where you just have more fine grained control over the resources.
If you're going to towards, if you look at containerization, we want to put our code in a container, we want it to be portable, we want it to be, consistent in all environments, Docker's a technology I strongly recommend, you're probably all familiar with it.
Has a huge support, in the community, very easy to pick up and very portable.
And then finally, sometimes we see organizations wanting to go beyond this and containerize a broader solution, something like Kubernetes can be useful for that, there are other technologies.
And there is also the option of just containerizing your applications, but then relying on cloud native features.
If you need a database rather than trying to containerize it yourself, you get a lot of, free benefits.
Things like backups, retention, restoration, by using cloud native solutions around things like databases, storage, queues, etc.
So just some, thoughts there.
Okay, let's get to the heart of this, talk.
We're going to go through eight application modernization patterns.
These aren't all mutually exclusive by any means.
You can mix and match.
And, all of them have their place.
So back to pragmatic decision making.
I'm not telling you to use any of these patterns or not use them.
There is one I will tell you to definitely avoid and I'll start with that one.
But otherwise, feel free to use what is most suitable for your situation.
At a high level, summary of what I'm going through today is, aptly name zero because, programming, we start numbering zero, and it is a bad pattern, so we're giving it a low score.
But, the first pattern is just no pattern, and I'll go into that soon also referred to as a big ball of mud.
And some of you may know where that reference comes from.
I'll, if you don't, I'll have a link to it soon.
The next one is Strangler Fig.
And then we have facade, we have backends for front ends.
And this one seems outta place, but I'll explain why it isn't once I get into it.
Then we have, eventify, microservices.
You've all heard of that one.
I have a lot to say on it.
We have micro front ends, which relates to it a bit.
And then multi monolith and parasite.
That last one in particular, I've got a really cool graphic for it.
I may or may not have used AI to generate art for this presentation.
Okay, so let's start with pattern zero, a big ball of mud.
Now, no one sets out trying to make software that looks like this.
But we've all dealt with software that isn't necessarily fit for purpose, and any time you touch it, it breaks, and there's a lot of fragility.
An example of this, that I've come across is we worked with a startup that were building a new platform, and from the get go, they identified an open source, package that seemed to basically give them 80 percent of the functionality out of the box.
It was a really quick win, and so they adopted it, and, they very quickly realized they didn't do everything they needed, and that last 20 percent took so much effort to build in.
But they just doubled down and kept going, building around this, this sort of tool that over time they should have realized wasn't fit for purpose.
Eventually they added the missing features.
It took them probably four times as long as it should have.
Not an exaggeration.
And teams can spend more than four times their original budget to get, to not get something out the door.
This happens.
But fortunately they had a very successful marketing team and sales team.
There was an interest in their product, despite the technology kind of being fragile.
But they are now in a situation where they've achieved, success in the market, but have a product they cannot modify.
And a ticking time bomb, because that platform really can't be modified very well.
It's very fragile.
Now, why do we end up here?
It's because a lot of engineering driven initiatives just get in there and start writing code.
They start cutting code, start deploying things.
What is the quickest path to get something out there?
And so But my view here is that producing code is not a software team's main purpose.
That's not what we're about.
Now, what are we about then?
What should we be about?
It's really understanding problems deeply and then crafting simple solutions.
Software doesn't exist in a vacuum.
It doesn't exist so you An engineer can use shiny new tech.
That's cool.
We all like shiny tech.
But that is not the end goal.
The end goal is deliver something valuable that people can use.
That is the purpose of software.
The only reason it exists.
Please make sure you understand problems deeply and craft as simple a solution as possible that solves that problem.
And this really means investing time into your planning.
Engineers can feel like their main job is just planning.
Writing code, that's part of your job.
Thinking about how you're going to write code, thinking about how it's structured, thinking about how it's maintained long term, how it works with other systems that you must support and integrate with, also very important consideration.
And as I mentioned before, there's more than one good way to solve a problem, but there is also absolutely more than one bad way to solve it, in that it takes longer than it should.
It's hard to maintain in the future, so to avoid using this pattern, you have to consciously pick one or more other patterns.
Otherwise, the default is you have a mess.
Let's try and avoid that pattern.
Okay, I mentioned a big ball of mud.
Now this is an article I came across maybe a decade ago, and it was written in the 90s.
But it is ridiculously relevant today.
If you've ever had to deal with a system that you felt was just an absolute mess, made no sense, and you just feel like you want to scream in frustration, this article will be extremely validating.
It's a good read, and also a cautionary tale.
You can reach out later if you don't get to scan that now, and I can share the slides with you.
But the QR code there for your convenience as well.
Okay, I don't want to talk too much about what you shouldn't do.
Let's get into patterns that are quite useful and have their place.
This is the last time you'll see actual photos.
Here on out, pure AI generated stuff.
So let's get into this one.
Pattern one is a strangler fig pattern.
And it's actually named after a tree that, that exists in quite a few countries and this architecture pattern was put forward by Martin Fowler in 2004 after visiting the Queensland coast.
So he saw this tree and I'll explain what it does.
If you look at the first slide there, the first photo, Essentially, this, strangler fig, seeds itself in the upper branches of a tree and then works its way down until it roots in the soil.
And once it does that, it slowly takes over and suffocates the host tree until all that's left is that patchwork on the right.
That is the final phase.
So the tree that was originally there is no more, and the Strangler fig takes over.
Now how does this apply to software architecture and app modernization?
So what you start off with is you create a new application that's adjacent to your old one.
So you have an old application, you leave it alone for now, you start a new application, but what you do is really just pick off slices of functionality to migrate across.
So rather than going, we must migrate everything that's been done on this platform for the last 20 years all at once, A monumental effort, just start by migrating little bits of functionality.
And then you can do things like, use a routing layer, an API gateway or similar to divert more and more traffic, against individual API endpoints or, different URL paths.
There's different ways to do this, but essentially what you do is instead of replacing everything at once, just very slowly suffocate your old application, starting with the things that you can most easily get wins on with the new application.
Over time you move functionality across, eventually nothing is left.
Now this is a long term strategy, when you adopt this one, you're just, you're doing it a bit slowly and you're mindful that it will take time, but you're in it for the long haul.
Alright, this next pattern is the facade pattern.
Facade pattern is when you have an embedded piece of technology, and it could be an internal or external piece of software, that you simply cannot get rid of.
You might be contractually obliged to use it for the next ten years, we have seen this happen with our clients, or longer durations, or it may just hold so much critical information that you cannot get rid of it.
Maybe there's a ten year plan to get rid of it, but right now, you need to build something to that operates against some data this contains, but you don't want to be exposed to the mess underneath.
An example of this we've had is, one of our clients had something they had to build, a mobile application, we wanted to build a nice RESTful API, and it turns out the service they wanted to consume was XML SOAP.
Now, that's not that old, you can get much older than that, but it definitely wasn't something we could find support for on a mobile framework, we just really struggled.
So what we did there is, we created an interface that acted to contain those legacy components.
So we built a very thin translation layer in front of those APIs.
And it just really did a format transfer and it did a bit of authentication handling.
And that was all it took to then present a modern interface to our app.
Now, this interface can live either inside the legacy application, if you're able to update it that way, support a new format or protocol, or it can sit outside of it and either approach works.
So one approach is just, put in this interface, do the translation, and if you think through that interface well enough, that interface may persist in the long term, even after you swap out what's beneath it or behind it.
So if you design your interface well enough, that becomes permanently your new interface, and over time as you replace, the system that you want to get rid of, that interface remains the same.
It's very possible to do that.
So that's the facade pattern.
Now, this next one is not directly an AppMod architecture pattern per se, but we find it an accidental gateway to AppModernization.
So I'll give you a scenario here.
We worked with a startup, and the startup was hugely successful.
They really grew during COVID because people needed their services, They were an e commerce platform, primarily web driven.
They had some REST APIs, but most of what they had was full page loads and that sort of thing.
And it actually worked for e commerce, right?
Everything's automatically indexable by search engines, it worked for them.
But they wanted us to build a mobile app, and we couldn't do it against what they currently had.
So we started building some new APIs, adjacent, sometimes deferring to APIs they already had, other times using our own, and it ended up just being the start of, a modernization effort, but inadvertently.
So this is one that teams stumble into.
You create a backend tailored to a new frontend.
That could be another service, it could be web, it could be a mobile app.
Not usually deliberate modernization efforts, so it's often an accidental way to start modernizing.
And look, if you stumble into this, just run with it and launch your modernization efforts off it.
It's okay.
And look, you're going to see this pattern a lot.
You don't always have to completely destroy old software to build something new, that works, that is sustainable.
Quite often you need to work with what exists, and look, the larger your organization, the longer they've been using software, the more you're forced into this situation where you cannot dictate what the whole organization does.
You can't make sure everything is new and shiny all the time.
It's simply not feasible.
Okay, that's back end for front end.
This next one is interesting.
This one's the Eventify pattern.
What you can see there in the middle is this old structure that's broadcasting and everyone else is receiving a signal.
Believe it or not, there's still a lot of organizations, government and enterprise, that use mainframes, for example.
Now, mainframes are notoriously hard to scale up.
You can't just, you can't scale it up, but what happens when that becomes a bottleneck?
So we've run into this situation quite a few times, and while there's generally a plan to eventually migrate everything off the mainframe, that's a very long term initiative, can take 10 plus years depending on how many decades have been spent building on top of it.
How do you solve for that problem?
How do you deal with a situation where you have a bottleneck in this system that you cannot easily replace?
It doesn't have to be a mainframe, just any system that is a bottleneck that cannot be easily replaced.
What you can do is, broadcast events from this legacy application.
So you make very small changes to it, or maybe it's an external timer that fires.
And whatever data is required at scale, you push out of that system, into systems that are more scalable.
Hopefully cloud enabled and auto scaling and all that shiny stuff.
That is something that can be done.
You broadcast events.
That take that data out, and instead of relying on that system that cannot scale, you then defer to systems that can scale, that are integrated with it.
Once you do that, you can then use event driven architecture more broadly.
I won't go into detail too much around that.
Just as a broad architecture pattern, you can have event driven architecture.
It's quite a modern pattern to use, more broadly in architecture.
Moving on to one that I'm going to spend a bit of time on, and that is microservices.
Now I'm going to show you two images for this one.
This first one probably represents what we want microservices to look like, and they can look like this when done right.
So you've got a whole bunch of buildings in a nice city, everything's nicely contained, every service has its responsibilities, probably does them well, you can have teams owning different services.
I'm not trying to disparage microservices.
But unfortunately, we've seen them done poorly so often, and some of the biggest problems we've seen in the last maybe five years have been due to teams just diving into microservices without considering how they should do them, what the correct way is for their organization, for their context, and they end up with a big mess.
So it ends up looking a bit more like this.
You have a team of engineers who spend way too much time maintaining complex infrastructure.
We've seen cases where there were four services to each engineer.
And Velocity grinds to a halt because what's often lacking in this is good engineering discipline.
And it's a bit chaotic.
And teams are driven just by this view of we need to do microservices.
It's the trendy new thing.
And look, it is it is a trendy pattern.
It's quite often very, suitable.
We've seen it done well to great effect.
But just because It's suited to this organization or that organization, even within your organization, just because it was suitable.
One place doesn't mean it's suitable everywhere else.
So this pattern is very highly reliant on strong engineering practices.
I'll paint you a quick picture.
You develop these microservices because it's the right thing to do.
And again, we really need to avoid that thinking of there's only ever one right way to solve a problem.
You're relying on these, … you have all these services, you've split up your monolith, which was super outdated, and no one knew how it worked.
But then you realize you didn't really split it up properly, and all your services depend on each other.
We've seen teams go as far as separating the data for each service into its own database, then realize, oh, we can't separate the data.
Instead of then consolidating it, they built a custom syncing layer to synchronize between about 10 services.
And the engineering team spent all their times just making sure this complex mess kept standing.
And very little time could be spent just actually getting things done, getting new features out the door.
They were so obsessed with this pattern that they heard was great, and it really was absolutely disastrous for them.
I had another example, five team members decided they needed 40 services, 4 0.
It's a small team, there are no other teams, there are no immediate plans for growth.
And they just created this big mess that they did not need, so microservices can be great and it's absolutely ideal for organizations with multiple teams.
If you work at an enterprise government, you need to be doing this, even if it's a medium sized startup, you may find yourself splitting things up for good reason.
Absolutely nothing against it, but please make sure it's suitable and you're doing it right.
It's also extremely sensitive to strong engineering practices.
If you have 10 microservices that make your front end work, say your website, how do you test all of that without orchestrating your whole service?
How do you do end to end testing without being in a live environment?
Just basic things like that are often missed when considering, this pattern.
Alright, enough on that.
I can rant longer on this, I promise you, but I'm gonna move on.
But this next pattern is closely related to microservices and is more of a modern conversation.
What ends up happening with microservices is teams that do it well and it's a suitable fit, they end up with all these services great, but then they quite often realize they're bottlenecked on the front end.
So while they have all these services in the back end, on the front end they just have one container, one code base, maybe it's React, it's some other shiny framework.
But it's all in one place, so teams step on each other's toes.
Who owns this?
Who owns that?
Constant conflict.
How do we deal with this?
So MicroFrontends exists to solve this problem.
It pairs well with microservices and eliminates frontend bottlenecks.
Now this is another thing that has to be done carefully.
It needs to be thought out almost in a vacuum where you just decide how it's going to be done.
Do it carefully before bringing your teams on board.
But it's easier to do than you And, the massive benefit here is teams can own functionality end to end.
So rather than having a front end team that everyone has to work with, teams split across organization or product, can own entire slices of functionality.
And the technical approach here relies on two very basic browser features.
You can just use frameworks that do this for you, but I've seen large orgs do this on their own very simply.
First one is just using the DOM as a shared state.
So you build a container that's your layout, and then, for your high level menu items, this is just one way to do it.
I'm not saying do it this way.
For each high level menu item, you load a different app.
It could even be hosted separately and it just draws it in.
There's far more complex ways to do that as well.
But the DOM itself can act as a shared state, right?
Maybe some DOM elements are shared, some are just unique to your team or your front end.
And this next one is little known but has existed forever on the web, and that is the PostMessage API.
That is an API designed to let Windows message each other.
So if you have two different Windows on two different domains, they can actually interact offline.
Through your browser using this PostMessage API.
Supported since forever.
Every browser supports this.
It's a common mechanism when using micro frontends to communicate between the frontends.
We've seen a large bank do this where different teams could even pick their own frontend framework.
They didn't even dictate you must use React, you must use Angular.
Every team did their own frontend.
They had some shared concerns, some shared CSS, for example, that was applied.
But they could largely do what they wanted and these two things facilitate it.
Okay, now this next pattern is the antithesis to what we just went through.
Look, sometimes you have a monolith and you need to modernize.
Sometimes the correct answer is just build another monolith.
Now, that view is actually becoming more popular again.
Used to be everything was a monolith, now everything's a microservice.
We're course correcting a bit and I think that's healthy.
Both approaches have room to coexist, and really, again, it comes down to context and making pragmatic decisions.
Sometimes a monolith is a good solution.
Just take care not to replicate your current problems.
I've worked on products where, three times within a two year period, the entire product was rewritten, three times.
And each time they just ended up with the same problems.
They kept looking at it from a purely technical lens.
Oh, this is a problem because we're not using this particular state management in React.
That's never your real problem.
What the problem was is there was intense pressure from the business to move quickly all the time.
And they constantly just went for this short term velocity.
We can get a win today.
We can get this out in two months.
Guess what?
We can't ever touch it again.
It will break everything.
And they don't stop and pause and think maybe your engineering practices need to change.
Maybe you need to push back and make sure your team has enough time to do things right and set yourself up for future success.
My definition of tech debt is simply prioritizing short term velocity over long term velocity.
Now, if you can quickly hack something together with no long term ramifications on velocity, please go nuts.
I don't think tech debt is messy code somewhere in a corner.
It's not the problem.
If that code's never touched again, it's not tech debt.
Tech debt is when you go, we're gonna build this in a dirty way that, that means something else is gonna break down the line.
When we scale beyond this amount of users, we have to rewrite the whole thing.
That's tech debt.
Always make sure you consider the long term.
And again, just to reiterate, more services, not always the best way.
Running out of time, so I'm going to sprint through the last pattern.
This is the very last one.
It's my favorite art, by the way, of the talk.
Thank you, ChatGPT.
What we're looking at here is a parasite.
And the final pattern we're going through is the parasite pattern.
Now what is this?
So we've had to do this a few times.
It's never been our first option.
It's never been what we went in aiming to do.
But what ends up happening is sometimes you have no access or no support for your application.
Maybe you're at an enterprise where no one knows who owns the application.
It's somehow running.
No one knows who has access to it, or maybe there is access, but there's no support.
You're not going to get it in time for what you need to build.
So an example of this is, we had to build something for a large enterprise against a system that had no API.
It was just purely a web app, MVC framework of some sort, and, we needed to urgently build a mobile app on top of it.
And we had no access to the team working on it, no one could figure it out, I think no one was working on it at the time, no one had access to it.
But this thing was urgent, it had to happen now, and it had to be a native app.
Because we needed device features not available on the web.
So we ended up building an app that kind of was a parasite.
It tacked onto the web behind the scenes without anyone knowing.
And it was the only way we could get something out the door in the time frame we had against this system that we had to work with.
That's what held the data, that's what we had to work with.
This is quite often something you just only arrive at by being pragmatic and realising you have no other way but to attach yourself like a parasite.
So unorthodox, but it can be quite effective as a last ditch measure.
Engineers always get sad doing things like this, but if it's your only option, you might have to just do it.
Okay, If you do this one, and by the way, this applies more broadly, always clearly articulate what you're doing, what your plan is, none of us work in a vacuum, you're building software for someone, the requirements came from a team or other people, just make sure you're communicating, taking people on the journey with you.
Just some key takeaways before I wrap up.
Make pragmatic decisions.
Always consider your situation, your environment, your team, your timeline, your budget, all of that.
Just be careful.
It's not just about the tech.
Keep it as simple as possible.
Do not overcomplicate things.
Don't add extra moving parts just because it seems cool.
Deeply understand your problem space.
So understand why you have to build this thing.
Don't just go ahead and build things.
Understand why.
Why are we doing this?
And then craft a simple solution to solve it.
And finally, I can't say this enough, take people on the journey with you.
I've quite often been guilty of thinking of something that had to be done and then trying to go ahead and do it without taking people on the journey of how I got there.
And I can intuit some things after doing this for 20 years, but sometimes you need to explain someone non technical, and you have to be patient.
It might take weeks or months to convince them of the right way forward, but don't give up.
Loop people in, keep them up to date, and explain yourself.
Vouch for your ideas if you believe in them.
Look, and that's all I've got for today.
You can email me at the address, you can see up there if you want to talk about this stuff.
I also have a QR code if you want to add me on LinkedIn, if you want to ask for slides or just, just share anything you're working on, I'd be, happy to do that.
Thank you all for your time.
Dive into the key architecture patterns:
- Microservices
- Containers & Kubernetes
- Serverless
- Cloud-Native Design
- Event-Driven Architecture
for effectively modernising legacy applications, with a focus on cost, performance, security, and scalability considerations.