How adopting GraphQL will make your organization better / faster / stronger
(upbeat music) - What's up, Web Directions? First talk of the day.
I am super excited to be here with you all today. So much so that I flew 20 hours, halfway around the world, all the way from New York City.
And it's been amazing so far.
I absolutely love Sydney.
The people are so friendly.
The beaches are awesome.
And I am just really super excited to share with you all what we've been working on at Apollo, and also a topic that I'm very passionate about, how to build better, faster, and stronger teams with GraphQL.
So you already heard the intro.
My name is Peggy Rayzis, and I am an Engineering Manager at Apollo, where I lead a team focused on developer experience. And our main goal is to ensure that developers all around the world are successful with GraphQL. And that's exactly what we're going to be talking about today.
So we're here to talk about GraphQL.
We're here to talk about what it can do for your team. And maybe you've started to evaluate GraphQL or maybe you've never even heard of it before. That's totally okay.
But one thing is really for sure and that's GraphQL is here to stay.
Over the past year, GraphQL adoption has increased significantly among companies large and small. So here are just some of these logos.
I mean, all of these companies, companies like Airbnb, GitHub, and The New York Times, they are all running GraphQL in production. And what's really cool about GraphQL is that companies from a diverse range of industries, so you're seeing e-commerce companies, you're seeing FinTech, social media.
And all of these companies are seeing value in GraphQL. And I think this isn't just because everyone's trying to hop on the newest, hottest JavaScript trend. It's because GraphQL solves real problems that engineering teams face every single day. So I think often times as developers, the biggest problem that we face when we're building apps is constructing the data layer.
And it's because data management is very complex. So our apps have a bunch of different microservices that we need to pull data from, whether they're REST APIs or databases, and then we have to filter that data, and we have to sort that data, and we have to make sure it's displayed in the right way. And, on top of all of that, we have a bunch of different clients that we have to support, so we have websites, mobile apps, chatbots, IoT, and new clients keep popping up every single day. So the data requirements for our applications, they've became increasingly complex over time. So here's just an example.
Let's just take Twitter, this is a screenshot from my Twitter feed.
And you can kind of see there's a lot of data on that page. And where is that data all coming from? So here's just an example, I've kind of outlined where I think the data is coming from.
And there's so many different sources, so many different APIs.
So you have user data at the top, you have trending topics, you have the feed itself, you have Who to follow, you have the posting a tweet itself.
And these are all probably pulling from different data sources.
And when you need to pull from a lot of data sources like this, you have very complex data requirements. And this isn't just for people who are running a microservice architecture, this is for monoliths as well, because often times the data that's exposed by the monolith is not in the form that you're actually consuming it on the client. So I think whatever your situation, whether you're running a microservice architecture or a monolith, if you're really just working with data, then GraphQL can help your team.
So, first, let's talk about what GraphQL is. And I think in the simplest terms it's really just an API specification that details how we communicate about data. So this specification is very unopinionated. You can implement GraphQL in whatever language you want actually, and it's also extremely flexible. So I think when we think about GraphQL, often times we're talking about this communication in terms of servers and clients, but you can actually use GraphQL to query a client's side cache, for example, or even a style sheet.
I mean, the possibilities are literally endless, and that's what makes GraphQL so exciting.
So I think to keep it simple, though, for this talk, we're just going to stick with the client and server model for now.
So in this model, GraphQL becomes an API layer, and it sits in between your clients and your services. So in this model, your services, whether that's a REST API or a database, they describe the data that they have.
And then your clients describe the data that they need from those services.
And GraphQL is kind of that layer in the middle that handles all this for you.
So let's talk about what this actually looks like in a production environment.
So first you're going to want to start with your schema. That's always the first place you're going to start when you're building a GraphQL API.
And in your schema, you describe what data your services have.
So you can kind of think as a GraphQL schema almost like a blueprint or a menu for all of the available data that your clients can query.
So here you kind of are starting the root of your graph with that query type.
And you'll see that we have both a POST query that returns an array of POST items, and then from there you'll see that we've defined a POST type, and that describes the structure of the POST that we're going to receive back from our API. And then we also have another query.
We have a query for author to fetch an author by its ID. So you can kind of visualise in your mind if you're starting with that query type, at the top of your graph, how it can then branch out with all of the different types that you expose in your schema.
So one of the other cool things about your schema is that it's strongly typed.
So that's kinda why those definitions, and we call this Schema Definition Language, looks a little bit like TypeScript or Flow, if you're familiar working with that.
And, as we'll see later, the static typing opens up the door to a lot of really cool developer tooling.
So, okay, so we've written our schema, what's next? So the next thing is we want to describe what data we can retrieve from our API with queries. And you can think of GraphQL queries as GET requests, but that's not all you can do with GraphQL. You can also update data, so that would be a mutation, which you can kind of think of as a POST request, and then there's also subscriptions for subscribing to real-time events.
So just to continue kind of like that restaurant analogy, if your schema is a menu, then queries are how you place your order with the restaurant.
Okay, so we have our queries, but how do we actually turn those into data? So that's where our resolvers come in.
And resolvers are functions that transform our queries into data.
So you can kind of think of a GraphQL query as a tree of resolver functions.
So, first, you'll have that author resolver called, then the ID resolver, first name, finally POSTs. And this is kind of what it looks like in practise. So first we're going to call the query dot author resolver. And resolvers are extremely flexible, so you can do literally whatever you want.
You can return primitives like strings or integers, and you can also perform data fetching.
So you can fetch from REST APIs, databases, gRPC services, literally the possibilities are endless. So once we call that query dot author resolver and we get that data back, then we're going to call that author dot POSTs resolver. So that's what's really cool about GraphQL is you can also specify resolvers on types, not just queries, and that's what allows you to really just transform and mould the data into the shape that you choose.
So just to kinda put this all together.
This is what it looks like in a real API.
So this is a screenshot from GraphQL Playground. And it's an IDE, which you get for free when you build an Apollo API.
So on the right there we have our schema.
And we get this automated documentation all for free thanks to GraphQL's static typing.
And here we can search and we can explore all the available types that we have to query in our app.
So then, on the left, we have our query.
And what's really great about GraphQL is that the results are always predictable. So you request only what you need, and then the response shape that you get back from your API exactly matches the structure of your query. So it's really great in terms of predictability, but it's also great for reducing payloads as well. Say we don't need that genres field or that overview field, we can just omit it from our query and then it will also be omitted from the response as well. So that's really what's so awesome about GraphQL is that the predictability enforces consistent results, but it also leads to smaller payloads and also fewer roundtrips, because each request returns exactly one response. And that size of the response is dictated by what you ask for.
So you always receive exactly what you ask for, nothing more or less.
And these smaller payloads are a huge win for consumers on mobile devices with a slow internet connection, because then they don't have to parse that huge response. So just how noticeable is that difference? So here we have a REST API detailing all of the launch information for SpaceX launches. And this one resource alone sends nearly 35 kilobytes of JSON.
And it's highly likely that we're not going to use all of those fields in our client app. So how can we make this better and how can we improve and optimise this with GraphQL so we are not sending 35 kilobytes down the wire and making our apps slow? So by layering a GraphQL API over this REST endpoint, all we have to do is just pick out the specific fields that we're consuming in our client.
And this reduces our payload down to only 1.3 kilobytes from 35 so this is a huge improvement, and it's one of the main benefits of GraphQL. So I think maybe some people are probably shaking their heads.
They might be a little bit critical, because you can already use REST selectors to accomplish this same thing.
But I'd argue that if you're already putting a lot of effort into making your REST endpoints behave like GraphQL, then it's probably a good sign that you should migrate to GraphQL and get that for free.
That way you're not maintaining all of that code to implement the REST selectors by yourself. The other thing is if you probably have a lot of REST APIs, you're feeling like this grumpy turtle here. So after the conference is over, I'm actually getting my diving licence at the Great Barrier Reef over the weekend, super pumped. And I'm really excited to meet this turtle, so I can convince him that you do not have to rewrite all of your REST APIs to get started with GraphQL. And I think this is a really common misconception, which is proliferated by all these articles. I feel like one a week pops up on Hacker News, GraphQL versus REST.
And it's a huge misconception, because actually GraphQL is a great compliment to REST. And layering a GraphQL API over the REST APIs that you already have is a really great way to get started and to migrate incrementally. And that's actually what I recommend that most teams do in order to get started.
So this is really great.
We've learned that we can migrate incrementally to GraphQL by layering a Graph API over our REST endpoints, but how do we actually do that? So that's where Apollo comes in.
So Apollo is a complete platform for layering a Graph API over your existing data. And you can kind of think of Apollo as a specific way to implement GraphQL.
So what does that entail? So we have two open source libraries, Apollo Server and Apollo Client, which are both the most popular GraphQL client and server implementation in the ecosystem today. And Apollo also comes with developer tooling, which is powered by our cloud service, Apollo Engine, that helps developers be productive with GraphQL. So this tooling is really awesome because it meets developers where they actually are. So we have a VS Code extension, we have a Chrome extension, we have integrations for GitHub, Slack, Datadog, and more. So it's really meeting developers where they are. And, not only that, Apollo also enforces a consistent set of best practises to help your teams get the most out of GraphQL and to help you all be as successful as you can be with it. So let's see what this looks like in practise. So, first, we have Apollo Server.
And Apollo Server is a schema first server with all the batteries included.
So first you're going to define your schema as you see here like we have with typeDefs.
Then you're going to implement your schema with those resolver functions that we talked about earlier. And then all you have to do is just pass those to the Apollo Server constructor, start your server, and you automatically have a Graph API running with GraphQL Playground, which was that IDE that we saw earlier, schema stitching, subscriptions, mocking, all of the features that you're going to need to be successful with GraphQL in production. Okay, so we have our Graph API with Apollo Server and now how do we fetch data on the client? And that's where Apollo Client comes in.
So Apollo Client is declarative data fetching for React, for Angular, for Vue, and also vanilla JavaScript, too.
So here in the photo, we actually have our React integration here but it's Vue layer agnostic.
And even if you're using vanilla JavaScript, you get all these amazing features out of the box. You get an intelligent client side cache, you get loading and error state tracking, optimistic UI, server-side rendering support. You get all of the things that you need to build complex production-ready applications just by creating an Apollo Client instance, which I think is pretty cool.
And what you see is really what you get.
You just write your queries and you pass them to a query component, and then you render your UI based on what your data returns. So you have your server and you have your client, and when you put it all together, it looks something like this.
So we have our Apollo Server, and that's our Graph API that sits on top of our REST APIs, databases, gRPC services, whatever data you already have, and then this server, it connects to Apollo Engine. And that's our cloud service.
And it's actually a schema registry.
So just like you have NPM as a package registry, Apollo Engine is a schema registry.
And once you push that schema to Apollo Engine, it provides detailed analytics to power the developer tooling like the VS Code extension and Chrome DevTools, and all of those things. So and then, finally, on top you have Apollo Client, which allows you to query your Graph API from any client, including iOS and Android, and anywhere else that JavaScript is run.
So once you register your schema with Apollo Engine, you'll unlock detailed metrics that give you visibility into the performance of your graph and how it's being used.
So I wanna be just completely transparent that while most of our tools are open source and free to use, viewing these detailed metrics in Engine is a paid service just because it requires a lot of infrastructure, and also because teams find it valuable.
But once you hook it up to Engine and you get that paid plan, Engine will collect detailed metrics on how you're using your schema at the most granular level, field-by-field. You'll also know what clients are sending which queries. You'll also know how many cache hits you have. And then all of that data is then piped into the developer tooling.
You can pipe it into Datadog and then it also powers intelligence in our VS Code extension as well.
So just to give you a preview of what this looks like. We haven't officially announced it yet.
You all are getting the first sneak peek.
And we are launching this at our conference, GraphQL Summit, next week.
So I am super excited for this to go live, because it is awesome.
It actually gives you real-time metrics inside your editor of the performance of your queries as you're typing them.
So I think a common concern of GraphQL is, from backend developers at least is, if I just open up my services to frontend developers however they want then they're going to make needlessly expensive queries.
This safeguards against that, because you'll know exactly how long those queries are taking, running against your actual production API. So it's really important for you to have these metrics in order for you to understand what's going on with your graph, so we're really excited.
Definitely check it out next week.
We're super pumped about all of this.
So with all of that, Apollo has grown astronomically over the past year. It's actually grown 400%, which is absolutely crazy. It's really exciting.
But I kind of was looking at this and I was thinking why, why are so many developers gravitating towards Apollo and GraphQL? And I think the reason is really because Apollo helps developers succeed by lowering the barriers to building great apps.
And this is really important.
It doesn't just help developers on large production teams. It also helps bootcamp developers be successful building applications as well.
I sent out a tweet a couple weeks ago just trying to see if any bootcamp students had used Apollo before.
And I was absolutely blown away by the responses. It was just really cool to hear from so many people who were new to coding that with Apollo they were able to learn GraphQL and build their final projects in only two weeks. So this is just really a testament to how great the getting started experience is and how approachable it is to help you build apps with very complex data requirements.
But Apollo isn't just for bootcamp students. It's also for developers on production teams at scale. So Airbnb is in the process of migrating to Apollo. They're already using it in production.
And Adam Neary, one of the lead engineers who's leading this project, is just super excited about how Apollo really simplifies their state management.
So before they were on Redux, and now they're migrating to an Apollo Server API gateway. And then literally using Apollo Client for all their state management, both local and remote. So it's really cool to see that.
If you'd like to learn more about the Airbnb's migration to Apollo, there's a really excellent blog post by Adam Neary.
And I'm gonna tweet out the links to my slides afterwards, so don't worry, you'll be able to reference them later. But I highly, highly recommend just giving it a read, because it's really cool to see how they're adapting GraphQL to fit their use case. But that's not all.
So not all of us are working at a tech company using the most modern stack.
A lot of us have legacy APIs that we need to account for. And Apollo works for that, too.
So Kristy Miller, she's a developer at Poetic Systems, where she works with a lot of oil and gas companies with really old legacy APIs.
And by layering Apollo on top of those legacy APIs, they're able to iterate so much faster, because they're able to transform the data into the shape that they need that's consumed by their clients.
So whether you are a bootcamp student, you're working on a large team, small team, modern stack, legacy stack, basically, if you work with data at all, then GraphQL can help your team become better, faster, and stronger.
So how exactly does it do that? So how does GraphQL make your team better and write better code? I think it's kind of hard to define exactly what constitutes better code, but I like to think of it as code that's simple. And I think simple code is easy to extend and it's also easy to delete.
And that's exactly what GraphQL gives you.
So with REST APIs, like the SpaceX one that I showed you earlier, we end up writing a lot of client side code in our Redux action creators to transform and filter the data into the shape that we want. And GraphQL helps remove some of that complexity by moving all that data transformation logic to the server. And this is huge benefits.
So for one you're not writing all that complicated Redux code.
But probably the most compelling benefit is that it makes all of that sorting and filtering logic reusable across all of your clients.
So by layering an Apollo Graph API on top of your data, you can remove complexity from the client and then store it in a centralised place.
And that way all of your clients can use it, you're not duplicating yourself, and you just really have this centralised data layer that stores all of the transformation logic for sorting, filtering, localization, computed fields as well.
You can kinda just stuff it all into this GraphQL layer and then reuse it across all of your clients. Okay, so we've learned how GraphQL enables us to write better code, but it also allows us to ship faster by writing less code. So let's see and kind of learn how that happens. So state management in modern applications is really tough. There's a lot you have to keep track of at once. You're writing reducers and action creators and middleware, and you're dealing with all this stuff. And then on top of that, you have to implement all of these complicated features, like optimistic UI, offline support, pagination, and it becomes so much to keep track of.
So we really want a way to make that simpler. And the way to do that is really with GraphQL. So Apollo Client will just enable you to write queries and get your data immediately. It'll cache your data, track loading and error state provide really nice helpers to execute things like optimistic UI and pagination.
So it just simplifies everything that goes into your state management layer.
And it actually allows you to delete a tonne of code. So before I was working at Apollo, I was actually an UI Engineer at Major League Soccer, where I saw our entire transition through from REST and Redux to GraphQL and Apollo.
And literally every PR, we were deleting thousands of lines of code. And it was really amazing and just transformative, and it's really the thing that got me so hooked on GraphQL. So by moving to Apollo, it really just enables developers to write queries and not code.
What's also really cool about Apollo is that you can query your local data alongside your remote data.
So probably your components are made up of a lot of different data sources.
You have remote data pulling from an API, but then you also probably have some local state as well. Maybe state about a cart or whether the network status, whether the device is connected.
Or maybe from device APIs, like the Camera Roll for example.
So you need somewhere to store all that, and you can actually just store it in the Apollo cache alongside your remote data pulled from your API. And then you can query it with GraphQL just by writing that client directive there. That'll tell Apollo, "Hey, pull that data from the cache "instead of a remote API." So this is really great because the Apollo cache becomes this single source of truth for all of the data in your application, and GraphQL just becomes this unified querying interface. So, okay so we've learned how it helps us write better code, we've learned that it helps us ship faster, but how does it make our team stronger? So GraphQL actually makes your team stronger by helping product teams just collaborate better. And the way we do that is by schema driven development. So remember in the beginning when I said, "The schema is the first thing that you do "when building a GraphQL API"? And this is really important because once the frontend and the backend teams agree upon a schema, it becomes a contract that both sides can adhere to. So once you have your schema, you can actually just mock it out.
You don't have to connect it to real data sources up front. And then the frontend teams can build their query components with mock data as the backend teams are working on hooking up that schema to all the external data sources.
So it just provides this really nice development workflow. And it also enables really great conversations between frontend and backend teams about data requirements up front.
But that's not all.
So Apollo also allows you to evolve your API safely and it allows you to validate your schema changes as part of your CI workflow.
So once you register your schema with Engine, you'll use the CLI to then validate that schema against all of the operations made within a certain timeframe.
So you'll know if hey, I'm adding or removing a field, how many clients it's going to affect, whether or not that field has been queried in the past week or not.
You'll be able to validate all of that before you actually merge in your code.
And that way you'll be able to prevent bugs before they happen.
And all these analytics will also allow you to deprecate fields gracefully, which is really important as you're evolving your GraphQL API over time.
So what are the pitfalls? So GraphQL isn't a silver bullet, but I think one of the strengths about GraphQL is actually one of its greatest downfalls, too. So it's extremely flexible which enables you to do a lot of really cool things, but this flexibility also makes it really easy to do the wrong thing.
So how do we avoid this? So one of the common criticisms of GraphQL is performance. And a lot of this results from the N+1 Problem. So this is where a query could actually request the same resource multiple times.
And if you don't account for this, then you could take down the underlying backend services, because you're hitting them with too much load. So how do we solve this problem and make sure that our Graph API is not putting strain on this underlying services? And the way that we do that is through Apollo data sources. So Apollo data sources are an API that's part of Apollo Server.
And out of the box, just by using them, it automatically sets up a resource cache for you over your REST APIs.
So these are really new.
We've only had them out for a couple months, so we only have a REST data source and a GraphQL data source, but we're also planning to add them for things like SQL as well.
And by default, the cache is in memory, but you can switch it to Redis or Memcache, or anything else that you like.
And it just gives you this really great way to cache your resources, that way you're not dealing with that N+1 Problem. So another common criticism of GraphQL is security. So GraphQL queries can have unlimited depth and complexity. So here's just an example.
We're querying for articles and then querying for the author of those articles, then the followers of that author, and the favourites of those followers, and it just becomes infinitely nested, and recursive, and out of control.
So how do we prevent both developers from doing that and bad actors? We need a way to secure our graph when we're in production so we're not exposing it to possibly fail.
So the solution to that is the Apollo operation registry. So before I was talking about that schema registry that you use to push your schema to Engine, but you can also register your queries with Engine and ensure that only those allowed queries are what you're able to run in production.
So that way if any bad actors try to make queries that are not permitted, they're gonna be hit with an error immediately. So the operation registry is how we kind of address that security problem and lock down our graph. So this is all pretty cool.
How do I actually get started with GraphQL today? And the way I'm going to show that is with a demo. So I think, how much time do I have, 20 minutes? So for the last 20 minutes we are going to build a full stack Apollo app.
So this is gonna be really fun.
Let's see how it goes.
And this is actually what we're going to be building today. So we kind of saw that SpaceX API a couple times throughout the course of this talk, so we're actually going to put it into practise and build our very own Apollo Server.
So just gonna go over here.
So who here is familiar with CodeSandbox? Have you used it before? Okay, yeah, I love CodeSandbox.
It is super cool.
It's a great way to just start prototyping and playing around.
I use it a lot in my workshops, too.
And we actually have an Apollo Server template on CodeSandbox.
So this is what we're going to be using to get started today.
So we talked about the first thing that we do when we're building a Graph API, and that first thing is our schema.
So we're gonna start with that first.
And just like we saw in this design, we're going to be displaying a list of launches. So we are going to need a launches query, and that is going to return to us an array of these launches.
So now that we have our query, we need to define our launch type.
And how's the font size in the back, good? Okay, good.
Lotta thumbs up, that's what I like to see. So now we are going to define our launch type. So when I'm kind of defining fields for my schema, I like to look at the design first and see what data do I need to expose.
You don't wanna write your schema and expose more data than you're actually going to use.
So it looks like here we're definitely gonna need some sort of ID to identify these launches for the cache. And then we are also going to need the name of the launch and then this mission patch here, which is going to be an image.
So our name is going to be a string, and our mission patch is also going to be a string. So if we save that, and hopefully when we refresh, we can explore our schema. Great, okay, so this is GraphQL Playground. This is what you get out of the box with Apollo Server. It's super cool.
And just by clicking over the Schema tab here, you can explore all the types in your GraphQL schema. So what if I am a frontend developer and I wanna start developing my UI immediately without waiting on that backend data to appear? All you have to do is just pass in mocks= true to Apollo Server.
And we will just wait for that to refresh.
And now let's actually try making a query and see what happens.
So we have that launches query, and we have an ID, and we also have a name, and let's just see what happens.
So just by passing in mocks= true, it'll use the type information from our schema to automatically mock out that data for you. This is super cool, and you can actually customise the mocks, too, if you don't wanna use what's already provided. But it just makes it a really great way for you to start building your UI before your backend services are connected. So, okay, so this is pretty cool, but we wanna actually connect it to a real API. So the way we're going to do that is that Apollo data source that I mentioned earlier that sets up that cache for you. So first we are going to require the REST data source. And that is exposed from the Apollo data source REST package.
And then we're going to define a class.
So this class, we're gonna call it SpaceXAPI, and it's going to extend our REST data source. And we have a constructor.
And on this constructor, we have this baseURL property. And this is the base URL of our API.
So here's the REST API that we're going to be using. You can see all that JSON.
We need to clean that up and reduce the size of those payloads.
And we are just going to copy that URL and we are going to paste it here.
Okay, so now that we have our base URL, let's set up some methods so we can actually do some data fetching.
So literally all we have to do is just write this getLaunches, if I could spell, right here, and we're just going to return, the data source has convenience methods like GET and POST on it that take care of all the data fetching logic for you, so we're just going to return this.get and pass in the resource, which is launches. So once we have this data source all set up, we need to connect it to Apollo Server.
And the way that we do that is by adding this data source's property, which is a function, and the function returns an object which contains our data sources.
So SpaceXAPI, This Prettier is not working.
Do, do, do, data sources.
Hmm, okay, well let's just see if that works. If we refresh, what do we get? Okay, it looks like it's working, but the Prettier just isn't do, do, do.
Extends REST data source.
Okay, okay, cool.
So now let's just call this data source from within our resolvers.
So we're going to have this launches query and the context is where our data sources is going to be stored.
So from there we're going to return dataSources.spaceXAPI.getLaunches. Do, do, do, and let's see if that, oh, before we do that, then we need to define resolvers on our type. So once we have that resolver running, we're going to define some resolvers on launch. So the properties that we get back from this SpaceX API are not actually the fields in our scheme, so we need to transform those somehow.
So what we're going to do is, first we need this ID field, and that's going to take a launch, and then we are going to return launch.flight_number is going to be our ID.
So this is really great about GraphQL.
It allows you to kind of transform the properties that are exposed from your service, and make them more how you would actually consume them on the client.
So we have launch.flight_number.
Then, we're also going to need one for name as well. And that is going to be launch.mission_name, I believe. Do, do, do.
Yeah, launch.mission_name.
And then we're also going to need a resolver for that mission patch, too.
And I just know, because I've rehearsed this, that the launch is launch.links and launch.links.mission_patch.
Great, and now we need to just connect those resolvers to Apollo Client.
So hopefully this works.
I'm wondering why my Prettier isn't properly doing it. But now, once we do this, cool, okay, yeah, it actually works. (laughs) I wasn't expecting that to work.
(audience applauding) Yeah, thank you, yeah.
It's always a sign when your Prettier isn't auto-formatting. I'm like what did I do wrong? But, I don't know why.
It's working.
So, okay, so now I wanna demonstrate the shared resource cache that you get for free when you build these data sources.
So if I just add a field for the mission patch here, we should see these results display instantaneously, because we have already cached this resource. So if I add this field, we're not going to fetch it again, it just automatically shows up, and that's the resource cache at work.
Okay, cool, so we have our GraphQL API built, and it looks like I have enough time to build a frontend, which is super exciting.
So I'm just gonna duplicate this tab real quick. And we are going to create, do, do, do, a new React app.
Okay, so before we do anything, we are going to need to instal some dependencies, because that's what we do as JavaScript developers. (laughs) First, we are going to instal Apollo Boost, which is kind of an easy way to get started with Apollo Client.
Boost is actually going away in the next version of Apollo Client because we're going to just build these features into the API.
But it's not out yet, so we're going to use Boost. And then, once we have Boost, we also need to instal GraphQL itself, very important. And then once you have GraphQL, we are going to need to instal the React integration for Apollo Client, which is called react-apollo. Cool.
Let me just Hide Browser, okay, great.
So the first thing that we are going to want to do is construct a client instance.
So we are going to import Apollo Client from, from Apollo Boost.
And then we are going to just create a new client. And all you have to do to create a new client is just pass in the URL of your GraphQL server. And we have that URL right here.
Do, do, do.
So we are going to pass that in.
And what's really cool is you can just start querying data immediately.
So we're going to define a query.
And we're gonna also import this GraphQL tag function. And this function is a tag template literal that parses your query string into an AST, which is necessary for Apollo Client to work. So we're going to define this query.
We're just gonna call it GET_LAUNCHES.
And it's gonna be this GQL function right here. And it's gonna, just basically what we did before. Launches, ID, name, missionPatch.
Save that.
And then we are going to query from that client without using the React integration first, just so you can get a sense of what it looks like. So we're just gonna call it client.query, and we're gonna pass in our query GET_LAUNCHES, and this returns a promise.
So let's just see what we get and console log it.
Okay, so I think if I reload this perhaps something will appear in the console. Yes, okay, cool.
So we got a result, and on this result is our data.
So this is really cool.
So this is kind of what I mean when I say Apollo Client is Vue layer agnostic.
You don't need the React integration in order for it to work.
It just works with vanilla JavaScript.
But certainly the React integration makes it easier, because if you were going to just kind of roll your own in a React app, you would have to probably track this loading state in component and mount, and save to a state variable, and it would kind of be a big pain.
So we are going to quickly do, do, do, collapse the console right there.
Okay, great, so we're just gonna take this out for now, and we are going to use the React integration. So we're going to import this ApolloProvider component and also query from react-apollo.
And what this does, the Apollo provider, is it actually wraps our app and places the client on the context.
It's kind of like the React Context API, if you're familiar with that.
Provider.
Oop, okay.
So then once we have that, now our client is on the context and we can create our query components.
So we are just going to wrap this with a query component. Query, and we're gonna pass in our query GET_LAUNCHES. And this query component, it takes a render prop function.
So render props are a pattern in React that we use to compose components with other stateful logic. And this render prop function, we destructure loading, error, and data off of it. And then once we have those, we return some UI.
So if we're loading, we're going to return loading.
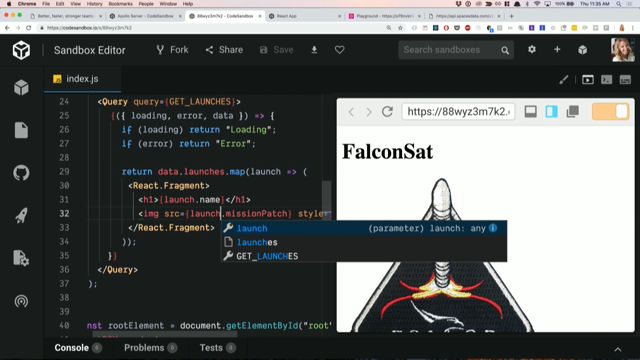
If there's an error, we're going to return error. Otherwise, we are going to return data.map launch, and we are going to do a React Fragment just to wrap our code.
And then we are going to do data.name and also the image, data dot, data dot what did I call it? Mission patch. (laughs) And we'll just give it a width of, width of 300 pixels.
Okay, so then once this looks pretty good, we will just take out all this.
Save it.
Data.map is not a function? Oh, that's because it's data.launches.map.
Ah, no, it should be launches.
It looks like we are getting a console error. (audience excitedly chatting) What is it? Someone shout it out.
(audience shouting) Oh, my gosh. (laughs) Thank you guys so much.
At least you guys were vocal about it and didn't let me sit here and suffer.
I appreciate that, the Aussies and their honesty. Okay, great, now we have it, yay.
(audience applauding) (laughs) Awesome.
So that's how you build an Apollo app in only 20 minutes.
Pretty cool.
It just shows you how easy it is to get started and how you can really start implementing this over your existing APIs today.
So I don't have a lot of time left, but I do wanna call out some other resources just so you can kind of further your learning. There's a new O'Reilly book out.
It's called Learning GraphQL.
It's amazing.
I was a technical reviewer on the book, and I just am so impressed by even Alex's ability to simplify complicated concepts and also make it really fun to learn GraphQL in Apollo. We also have a new tutorial coming out next week, that we're launching at the conference, which will show you how to use the Apollo platform, data sources, building a server, Client, VS Code, Engine, everything all in one tutorial. And it's gonna be really cool.
And if you only take away two things from my presentation today, the first is that GraphQL really empowers developers to work better, faster, and stronger.
And also that all of you in this room are koala-fied to implement GraphQL on your teams.
So start small, incrementally adopt, and you'll do just fine.
Thank you all so much.
(upbeat music)

Peggy’s team is responsible for making teams successful with GraphQL.
One thing that is sure is that GraphQL is here to stay. Adoption is growing and big names are trusting it in production, across industries. It’s not because it’s the new and shiny, it’s because it solves actual problems.
When building apps we have a huge challenge designing and building the data layer. We have tons of data to manage, and tons of clients to serve.
What is GraphQL? A specification for communicating about data. It’s unopinionated and very flexible.
(client: describe the data they need) ⟷ (GraphQL) ⟷ (Services: describe the data they have)
- With GraphQL you always start with your schema. It describes the data you have, essentially a set of types/interfaces (strongly typed, looks very like Typescript or Flow).
- Next you move on to writing queries, which describe the data you want. Get requests and listening to events.
- Resolvers are functions that transform queries into data.
For an example of this in practice, look up the GraphQL playground.
The thing that starts to really stand out about GraphQL is that you only get the content you request – request payloads are much smaller than traditional endpoints which usually send a great deal more information than the request really needed.
You always receive exactly what you ask for, nothing more or less. This is particularly valuable for people using mobiles. (Example where a REST endpoint is 35k, but the GraphQL equivalent was 1.3k)
You can use REST selectors to accomplish the same thing, but if you are doing a lot of work to make REST work like GraphQL… maybe just use GraphQL where you get it out of the box? Also you don’t have to rewrite all your REST APIs to start using GraphQL – they complement each other. You can layer GraphQL over your existing REST APIs and that’s a really good migration path for teams that need to change over incrementally.
Apollo is a platform for doing this layering. It’s a specific way to implement GraphQL. They provide client and server packages (open source) which help teams follow best practices. They support all the tools you care about.
Apollo Client allows declarative data fetching, it’s framework agnostic – you just put your query into an ES6 template literal. Apollo Server sits between your data and your client layers; and connects to Apollo Engine, their cloud service which registers your schema. (This service has some paid features for usage analytics etc.)
Apollo’s VSCode plugin will be giving realtime metrics on query performance at author time! This helps address the concern many teams have about the potential performance impacts when non-data developers start hitting the data layer.
BETTER It’s simpler! Simpler to write, easier to get rid of when you don’t need it.
FASTER GraphQL lets you ship code faster by writing less code. State management is hard and has a lot of code to write and keep track of. Apollo handles lots of concerns like caching (both local and remote); and generally just lets you delete a lot of code. Apollo cache becomes the single source of truth.
STRONGER GraphQL makes your teams stronger by helping product teams collaborate more effectively… with schema-driven development. Once you agree on a schema, you have a contract both the frontend and backend can use. Frontend can be built against schema-compliant mock data; while the backend team works on providing the production data layer. Apollo CLI also gives schema validation checks that help you evaluate the impact of changes before you merge; and deprecate fields gracefully as your API evolves over time.
What about the pitfalls? GraphQL is not a silver bullet.
Its extreme flexibility makes it easy to do the wrong thing, eg. n+1 problems where a query hits the same data source multiple times. Apollo Server handles this by adding data sources that be cached.
Another issue is security – because queries can have unlimited depth and complexity, which is bad when devs do it and REALLY bad if a bad actor is doing it. Apollo operation registry can lock the system down to allowed queries – that limits what anyone can do if they get in.
How do you get started with GraphQL? Demo time!
(full walk through of building an app with GraphQL)
@peggyrayzis