Announcing Moonshine Voice « Pete Warden’s blog
February 19, 2026
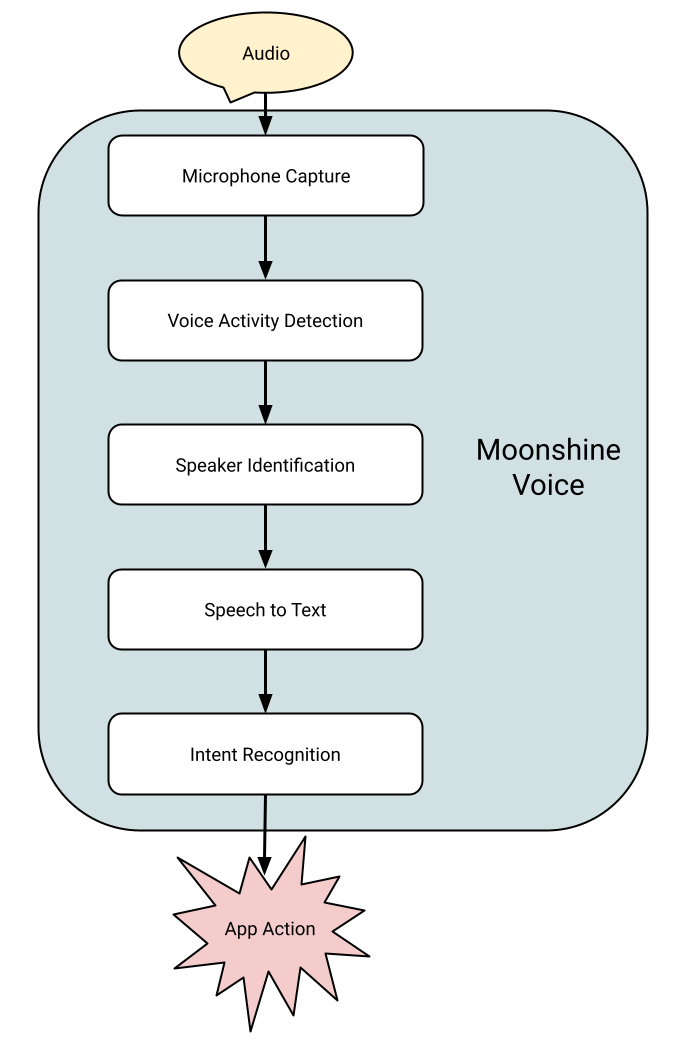
Today we’re launching Moonshine Voice, a new family of on-device speech to text models designed for live voice applications, and an open source library to run them. They support streaming, doing a lot of the compute while the user is still talking so your app can respond to user speech an order of magnitude faster than alternatives, while continuously supplying partial text updates. Our largest model has only 245 million parameters, but achieves a 6.65% word error rate on HuggingFace’s OpenASR Leaderboard compared to Whisper Large v3 which has 1.5 billion parameters and a 7.44% word error rate. We are optimized for easy integration with applications, with prebuilt packages and examples for iOS, Android, Python, MacOS, Windows, Linux, and Raspberry Pis. Everything runs on the CPU with no NPU or GPU dependencies. and the code and streaming models are released under an MIT License.
Right now, most of the focus by software engineers and AI engineers, product people, and designers when it comes to AI is large language models. They’re clearly very capable, but they’re not the only approach to achieving really interesting outcomes. There are a whole bunch of traditional machine learning techniques that can often be very useful for things like semantic search. There are vector and graph databases, but also there are small models.
Someone who has been at the forefront of this activity for many years is Pete Warden. His company has just released a new family of small models for transcribing that is doing speech-to-text. These run without the need for anything other than a CPU. I think they are really good examples of the kind of technologies we perhaps overlook that could be very valuable in the products that we’re building.