A pragmatic guide to LLM evals for devs
December 8, 2025
One word that keeps cropping up when I talk with software engineers who build large language model (LLM)-based solutions is “evals”. They use evaluations to verify that LLM solutions work well enough because LLMs are non-deterministic, meaning there’s no guarantee they’ll provide the same answer to the same question twice. This makes it more complicated to verify that things work according to spec than it does with other software, for which automated tests are available.
Evals feel like they are becoming a core part of the AI engineering toolset. And because they are also becoming part of CI/CD pipelines, we, software engineers, should understand them better — especially because we might need to use them sooner rather than later! So, what do good evals look like, and how should this non-deterministic-testing space be approached?
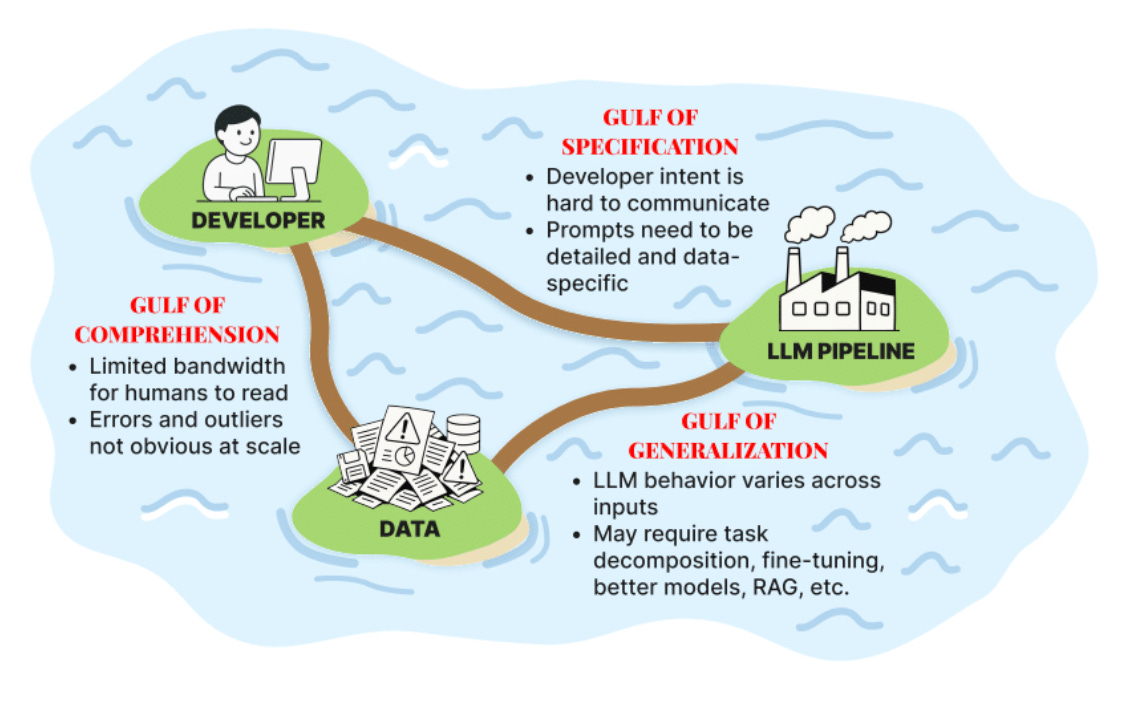
E-vals are a core part of debugging LLM-based systems, managing non-determinism and ensuring quality of output. This is a really good introduction to the concept and some of the key ideas based on real-world case studies.