The Web in the age of Surveillance Capitalism

(upbeat electronic music) - Thanks very much, John. It's good to be here.
So today I'm gonna talk to you about the web in the age of surveillance capitalism. So I'm gonna go into the details about what surveillance capitalism is and the role that web browsers and you as a developer have in this new economy that we're calling the surveillance capitalism economy. So what is surveillance capitalism? Let's start there for people who don't know. So as the internet came into being and computers got more powerful and the amount of hard drive space increased, essentially, people were able to record more and more information as people used computers.
So, essentially, as you move your mouse around, information can be recorded, as you access files, you know the day when they were accessed, and so on. So from that, you can essentially build profiles about people.
So pretty soon hard drives started to fill up and people realised, Hey, we can take this information and potentially make some from it.
So to give that a name, Shoshana Zuboff wrote a book called "The Age of Surveillance Capitalism," actually tried to understand this new form of capitalism. So it's a form of capitalism that has emerged only recently, or last few decades. And Wikipedia sums it up quite nicely as surveillance capitalism being "commodifying personal data "with the core purpose of profit-making.
"Since personal data can be commodified, "it has also become "one of the most valuable resources on earth." So given that it's so valuable, how do we capture that data? Particularly on the web, this happens through what's called tracking. So you probably would have heard of tracking, being a web developer.
So what is tracking? So tracking is the collection and retention, this is essentially Mozilla's definition, so tracking is the collection and retention of data of a user's browsing activity across multiple websites, which may be then shared amongst other parties without the user's knowledge or consent.
So a critical thing here is that people are watching what you're doing without you really knowing and then that data may be getting sold.
So not an amazing thing, tracking.
Now, there are good reasons to do tracking and sometimes tracking is okay.
So let's begin the, you know, let's look at this on the sunny side. Let's talk about why this might be okay.
So, for instance, you're selling a product and you wanna see what the conversion is on that. That's okay. That makes sense.
So you wanna know if your sales are making sense based on whatever you're doing, and that might be a campaign.
So, for instance, you might have a marketing campaign, so you wanna know if the marketing campaign is efficient or not, and you might do that through a website or you might be sending emails.
What's really interesting, next time you go to your inbox and you've received an email, go, for instance, to an image and right-click on it and view the URL and you'll see there'll be a special key just for you that identifies you as a person viewing the email. So email can be quite sneaky 'cause they identify you, they see if you've looked at an email, and if you click on a link, they identify you as the person clicking the link. So, again, another form of tracking.
And another time when it's okay, if you're trying to improve the user experience of your website over time.
It's okay to do some tracking there.
So why are companies tracking us? As we've talked about, it may be for advertising purposes. It may be for analytics, so how people are using sites, which routes are they taking into a particular website. So funnels and things like that.
Or it may start getting a little bit more nefarious, so to understand what are social connections and what are political affiliations.
And another thing that may come up is this whole concept of fingerprinting.
So we're gonna go into some depth into what fingerprinting is but, essentially, it's uniquely identifying you by various capabilities in the browser.
And another reason that people might wanna track us is to do what's called session replay.
So this is quite common.
You, again, wanna understand how a user's using your site, how much did they scroll, where did the mouse move to on the site, how long did it take them to find or click something, and so on.
So, again, useful things, but taken holistically, we can start building up a mass of data which can become a little bit nefarious.
So why track? Again, when you start collecting tracking data from a person, you're essentially building up a big profile and over time that becomes worth more and more. So the more I know about you, your preferences, your likes, your age, your gender, potentially your sexual orientation, your political leanings, the more likely it is that I might be able to sell you something or change your worldview or do something related to that.
So that's why people get into the tracking game. It's basically to collect as much information as humanly possible and then potentially sell that information or pass on that information.
So the problem is that there is hundreds and hundreds of trackers that are buying and effectively selling you without your consent and without your knowledge and they're doing this illegally.
And a lot of people are not okay with this, or they don't know what's going on.
So who is actually tracking us? So we're gonna have a look.
Essentially, the top people that are tracking us online, on the web, are Google Analytics, Google Static, the CDN, Google Tag Manager, Google Fonts, you'll be surprised to know, and then we have Facebook.
Other interesting things is 42% of these trackers are using cookies, which we'll go into.
We'll talk about cookies.
A lot of people know what cookies are but we'll do a little refresher there.
0.3% of these trackers are using fingerprinting and, on average, websites that are using tracking technologies are forcing users to download an extra 1.5 megabytes of data that you didn't ask for. So imagine you're in a developing country and you go to a random website, that's eating up a whole bunch of your internet usage. For us here in Australia or in countries like the U.S. and so on where we have fast internet, that may not be a huge issue, but every time we go to a site, we're basically downloading all this stuff that we may not want.
So it's slowing down the web at the same time. So let's have another little look in more detail who's actually doing this tracking.
Like I said, we had Google, Google, Google, Google, Facebook, more Google.
So you can see Google is amongst the top 10. YouTube does a lot of tracking, then you've got Amazon and so on.
So we're not gonna go into a lot of detail but you can see the companies here.
Some of them you would have never heard of, others are common.
So you see someone like Microsoft.
Again, more Facebook. AppNexus and so on.
Amazon pops up a lot.
Even "The New York Times" works as a tracker. And you see this list goes on and on.
So we've got 1,000 different trackers here. So that's not amazing.
So how does all this work? So, essentially, as you've seen, or you've gotten a hint of already, a lot of the time this is done through downloading media resources, so through images, through using CDNs, and so on, YouTube videos.
URLs are also a sneaky way of tracking.
So when you click on a link, by adding a unique identifier to that link. A unique identifier that identifies you as the user. So it can pass from one link, so from one website to another, it can keep tracking the same user over and over again. Third-party cookies, which we're gonna go into. So I'll show those in detail.
Supercookies, which are a scarier kind of cookie. They're not a sanctified or a standardised thing. This is actually an attack on a browser that creates a supercookie.
Fingerprinting and dual-purpose widgets.
So a dual-purpose widget is, for instance, embedding a YouTube video or embedding a Facebook widget, is an example of a dual-purpose widget.
It serves the purpose of allowing you to like something, but at the same time, it tracks.
So let's look at cookies.
Cookie is, at its most basic form, something that is stored on a website, on any webpage that you can set, and it's literally just a key and a value pair. That's all it is.
Except that when you navigate around a domain, so some origin, this cookie gets sent with every HTTP request. Cookies are nice. Who wouldn't love a cookie? So what cookies do actually allow us to do is maintain state, so they keep us logged in.
They allow us to personalise the websites for users. They're persistent, which is nice.
You don't need to login to a website every time you close your browser, and this is cookies coming into play there. So they're nice, persistent, even though they're time limited.
And what's nice about them as well is that browsers understand them so you can clear them as well.
So there's nice qualities to them.
They're not all bad.
Where it starts getting a little bit muddy is when we go, for instance, to a news website and we have these embedded ads.
So you can see them in the green.
So in those cases, imagine these are iframes that are coming from a different origin.
So what can happen here is as you navigate from, for instance, social-site.com to news-site.com to shopping-site.com, the same ad can appear and it's the same iframes with the same source. And because it's the same iframe with the same source, this third-party context, so this external website which is just ads.com, retains the same cookie and it's always going, Ah, I was embedded in social-site.com so I know you use, for instance, I know you use Facebook, I know you use Twitter, and I know you go to this news website and I know you go shopping here.
So from that, I may be able to deduce your political leanings, how often you go to these websites, you know, you like to have your lunch break and you like to check out your Facebook account, and what products you look at, and from what products you look at, you may be able to determine age and gender and things that you're interested in at any moment in time.
So, again, these ads, for instance, whatever, ad.com or whatever, will be able to build a profile about you.
Now let's talk a little bit about supercookies. So supercookies are, again, a scarier form of cookie and supercookies kind of arise from the law of unintended consequences.
So supercookies have this property that they can't be cleared and they even persist in private browsing, so they're kind of scary.
How they work is that they basically exploit browser APIs and features in browsers to actually build themselves up and to make themselves resistant to erasure. The users have no idea what's going on because this is essentially a hack.
They can't be cleared and, like I said, they persist in private browsing. So it's really scary.
So browser vendors, so Mozilla, for instance, we're always on the lookout for how people are trying to exploit this technology to create supercookies.
So you would find, like, the NSA, for instance, would be always trying to find supercookies as well and exploit them to track people, and particularly evil tracking companies would set a supercookie.
So I'm gonna show you an example of one of these. So this is the HSTS attack.
So HSTS is an acronym for another acronym, so it's HTTP Secure Transport, sorry, Secure Transport Security...
I can't remember it because it's an acronym for an acronym. But anyway, I'll show you the attack.
So, essentially, how HSTS works is if you have a HTTP resource, so an image, for instance, you could essentially use this technology in a really good way, which is like, Hey, if you land on this site, automatically upgrade the connection to HTTPS, so automatically make it secure.
So that's great, that's amazing. That's what we want. But then the attacker can come in or the tracker can come in and be like, "You know, I've got this a.png, "what if I have b.png "and I was not gonna upgrade that one?" And you're like, "Okay, that's fine." So let's scale that.
So if you're like, "Okay, I have a PNG file and I'm gonna turn it on here. "I have a second one, I'm not gonna turn it on there. "I have a third one, I'm not gonna turn it on," and so on.
So if I'm actually pulling levers here, if you're a programmer, you start seeing on and off, you start seeing ones and zeros, what are you seeing? You start seeing binary code, right? So suddenly you're Neo in "The Matrix" and you're like, "Ah, if I have binary code, I can encode that." So if I take just those little numbers there, I can get the number 74 out.
So let's scale to that to a number of servers. So if I scale that to, say, 32 servers, I now have 2.5 billion addressable numbers. So I can basically uniquely identify every user on the planet on the web.
So it doesn't take...
Sorry, that was to the 20.
So, essentially, given these possible identifiers, you don't need to go to many...
Sorry, given 20 servers, you can go to, let's say, one million numbers with just 20 servers.
Not even 20 servers, you can just use 20 origins, and uniquely identify whoever you want visiting your site. And as I mentioned, so two to the 32 will get 2.1 billion possible identifiers.
So let's now talk about fingerprinting.
So fingerprinting is similar to a supercookie but, again, it works in a similar way that it attacks the browser, or capabilities in the browser, to create a unique identifier for a particular user. So let's look at how this works.
We'll jump over to Panopticlick.
So Panopticlick is something developed by the EFF, the Electronic Frontier Foundation, and what it does is it pokes at the browser in as many ways as it can to try to generate a unique identifier.
So this is running in Firefox Nightly.
We'll see if my browser happens to be unique amongst all the browsers that they've tested in the last month.
So running the test now and we'll see how we go here. So it takes a little time.
Like I said, it's poking at as many things as it can and it's using real data to do this as well. And the results are coming in.
So let's zoom in.
Is your browser blocking tracking ads? Partially. Is your browser blocking invisible trackers? Partially. And the thing that matters here is the fingerprinting. Is your browser unique? Yes.
So my browser is, unfortunately, at this point, unique. So it's really hard to actually defeat fingerprinting. So let's go into some of the details here, given that we're a developer conference.
So we can look at some of the things that are being exploited.
So, for instance, the user agent string comes into play. So one in 131 web browsers share, of the ones being tested here, share this bit of information.
HTTP_ACCEPT headers. Browser plugins.
Time zone offset, so identifying you from where you are. The screen's colour depth is used.
The system fonts, so poking at all the system fonts to find out which ones are different from another system. So you can see how by using these various bits of information and getting enough variance, you can actually start uniquely identifying people. A quite funny one, which we'll come back to, is this Do Not Track header.
So Do Not Track was actually invented to disable these trackers as a way of using a standard to do this and it's actually used for tracking.
So by setting it on and off, you can actually use it as a bit of information. So this obviously has large ramifications and we've seen this play out over the last year, or last few years, particularly with the Cambridge Analytica data scandal that happened with Facebook.
So for those who don't know, essentially, a whole bunch of data was collected from Facebook and then essentially sold to this company for data analytics who then used it to manipulate various political campaigns. The effectiveness of these campaigns, or whether it worked or not, is in question but what is egregious here was the violation of privacy, and I'll let Katie Hile from the BBC, who looked at her own data, explain how this affected her.
- I'm Katie Hile.
I work for the Business Unit at the BBC.
I went on to my Facebook page this morning and had a look to see whether I had been affected by the Cambridge Analytica scandal.
Turns out that I have and I found out that the information that was passed on to Cambridge Analytica was my public profile, my birthday, my current city, and my Page Likes.
I went to quite considerable lengths to make sure that my birthday wasn't shared and that has been passed on to Cambridge Analytica 'cause I think that's relatively personal information. The Page Likes that I had a look at, you can build up quite an intricate picture of what I'm like and the sort of person that I am. So, for example, there are the fitness clubs that I've been to.
There's the cookery websites that I might have liked at one particular time. There's even a tennis club that I went to a few years ago. The way that they got this data is that one of my friends did a quiz called "This is Your Digital Life," and as a result of doing that quiz, they sucked in information about me which was then used by Cambridge Analytica. I also found out that the person that did the quiz may have shared posts and messages which included messages from me.
That worries me a little bit because some of that, I don't know the sorts of things that I might have sent, so I don't know what data's out there.
It does make think a lot more about how I share my information and what I do with it, so much so that I've actually deactivated my Facebook account because I think it's time for me to take stock a little bit and look at, actually, the sorts of information I'm sharing and where I'm sharing it.
- So as you can see, there are significant consequences here, particularly because Katie had to essentially censor herself being online. So not only did she stop using Facebook but now she's much more aware, but at the same time, that's quite regressive in the sense that you have to censor yourself. That's not cool at all. So that's not great.
So we don't want to head in that way where we have to censor ourselves and be really worried about the stuff that we view online. We should be free to express ourselves and communicate online without having that fear of having to censor ourselves because somebody's selling our data, watching over us, or could implicate us in something.
So how do we fix this? It's obviously a really difficult problem and there's a number of entities that need to come into play here.
So from standards, which I'll talk about, which is something, obviously, quite close to my heart, having worked on standards for so many years. Education, Mozilla being a large part.
Our mission being part of educating people about the web and trying to fix these problems at the same time. Obviously, government and law enforcement have a big role to play, even though they have a vested interest in monitoring us. So as you've seen with the debacles that have been the COVID-19 apps that haven't really worked.
And industry and NGOs also have a big role to play here, and part of industry is us as web developers, as well. So we all have a role to play here and understanding the problem that we've, in a sense, created.
So let's look quickly at the role of educators and also researchers, just from Mozilla's perspective.
- This morning I checked four websites, as I do every day. I looked at my surfing conditions in the area, I checked local news, I looked at national news, and I looked at a little bit of the tech website that I go to every day.
By the time I'd finished my cup of coffee, I'd actually interacted with over 120 different companies. I checked four websites, 120 companies.
Very few people understand that.
Very few people recognise that the interactions they have online are far more expansive than just the websites that they think they're visiting each day.
- And so we've built Lightbeam to help each one of us understand what tracking is occurring and what kind of information we're sending out in our daily lives.
- It's a Firefox add-on that provides users a view into all of their online interactions. - Lightbeam is part of a much larger mission. We build Firefox for the same reason, so that when you use Firefox, you have a base level of protection, a base level of flexibility, and a base level of figuring out what's going on and making some changes, if you should want to. - Not only do you have the content that the publisher is making available but now you have Like buttons and Tweet This. Each one of those elements that the page has loaded for you is being provided by a different company.
And so in that one moment that you see that website, all those other companies are also seeing you at that site. - We see Lightbeam as both a teaching tool for the people who use it and also a learning tool for all of us.
- When we take back that curtain and we expose all of the interactions that users have, it's not necessarily good or bad.
I think the bad that we're focusing on here is the lack of awareness, the lack of understanding. The first step in any of these types of issues is understanding all of those different companies you're interacting with, and it really is a "Wizard of Oz" moment to kind of see that behind the scenes, true functioning of how the web operates.
- So that gives you an idea of how we can show people, or you can show yourself, what's actually going on. And we actually have a data solution for this now, which I'll cover in a little bit.
So, obviously, the role of industry and NGOs. Again, going back to Facebook and Cambridge Analytica, we've seen that Facebook has learnt very little from this. They still resist collecting data or taking much action at all.
So Facebook, for instance, shared a whole bunch of data with Microsoft, Amazon, and Spotify and it's quite concerning.
So be aware of what you put on the social networks. Thankfully, industry is taking action, particularly, browsers are taking action, and this has been through tracking protection or tracking prevention initiatives where we actually build tools directly into the browser to try to put a stop to this.
With the browser vendors, we're taking various different approaches.
Particularly, like I said, Firefox, Safari, and Edge are doing this, but you'll notice one particular company, one particular browser, is not doing this and you can see why, going back to the beginning of our talk here, is that Google has a massive vested interest to track everything because that's their core business.
You saw nine out of 10, or whatever it was, of the top trackers were all coming from Google.
So do yourself a favour, if you love Chrome, maybe consider moving to Edge if you want to protect your privacy.
I also have here something about public policy and what public policy is is, essentially, companies putting out a statement letting tracking companies know how tracking works. So in order to be classified as a tracker, you need to do or meet certain conditions and each company has put out a statement about that. Microsoft, given that they've only recently released... They've put out a bunch of public documents but they don't have a very clear policy just yet, that I've found, anyway, from my own research. But, again, anyone who's seen the new Edge, they have fantastic tracking protection there as well. But given that I work for Mozilla, I'm gonna show you Mozilla's, or Firefox, anti-tracking features.
So let's have a look at somewhere you might, you're on Twitter and you suddenly end up on "The Verge", let's say. I love "The Verge" 'cause it's a good clickbait site. So let's go directly to "The Verge." And remembering now what we talked about, the loading times of "The Verge," given how many trackers being loaded, it can be a little slow.
So you may have noticed, if you're using Firefox, there's this little icon up here with the little shield on it and this lets you know that blocking's actually taking place.
So let's see what was actually blocked here. So we have Blocked, Social Media Trackers.
So we had Facebook and Twitter analytics being blocked. Cross-Site Tracking Cookies.
I actually wasn't expecting, what's that? Like, 50 different tracking cookies being set here on one site.
And Tracking Content, so you can see all the little pixels and all the little things that are being used, again, from Amazon Ad System, Google Analytics. Mother Of All, I think it's Mother Of All Ads or something like that, this website.
Anyway, you can see there's just like...
It just goes on and on.
So, again, I came to interact with one website, and at the same time, all these trackers tried to sneak their way onto my viewing session here.
So it's quite scary.
So what we built into Firefox, and, also, there's very similar in Edge as well, is you can actually set the level of protection that you want.
So we can be very strict, where we kind of just block everything, or we can have a custom policy and so on.
So it's very useful.
So as I mentioned before, the reason that we have various controls here from standard to more strict is that we have these dual-purpose widgets. So, for instance, if we set it on Strict, then, essentially, things like YouTube would break because YouTube try, well, they track at the same time as giving functionality. So by restricting them, we would break things. So we try to find the right balance between keeping the web usable and stopping the most egregious trackers.
So how it works in detail in Firefox, each browser does this differently, so what we do is we collaborate with another entity, with a company called Disconnect.me, you can go there, Disconnect.me, and they keep a list, so they go out on the web and they identify trackers based on the set of criterias I mentioned.
And so if you do bad things and you track this way or try to steal data, they will identify you as a tracker and add you to the naughty list.
So that's how you end up on that list.
And then there's essentially...
If you don't think you're naughty, you can go and appeal that.
This is different to the way Apple does this. Apple uses some kind of artificial intelligence magic to identify trackers.
So if you end up on the naughty list with them, you're in trouble, you've got no appeal.
But that's specified in their policy.
So they make it quite clear.
If you do this, you do this, and you do that, you're gonna be on the naughty list, and it's the same here.
And I'm not sure how Microsoft does this but they do something similar as well.
They may even be using Disconnect.me for all I know. So what happens if you're a tracker? What actually happens to you? So if a browser identifies you as a tracker, your cache is partitioned, so we actually rip you out, put you in a protected space, and treat you as hostile.
We essentially block any cookies that you try to set. We lie to you and say, "Yeah, we totally set those cookies.
"Don't worry about it." You don't get any storage, you can't communicate with other ads, and we block all sensitive APIs, you get blocked off completely.
So trackers can't do bad things, they can't access geolocation.
Essentially, we isolate them and lie to them and try to stop them that way.
So they think that they're in an operating environment but they're actually not.
And then as you leave, we basically just eject them out.
So whatever data they tried to write, we just cast it away.
So as I mentioned, because we do that, this can lead to breakage.
There are other industry initiatives, as we've seen. So Let's Encrypt, some people are using it, was a Mozilla initiative to make more sites move to using SSL.
There's the safe browsing list.
If you accidentally or somebody tries to phish you, often we catch it with the safe browsing list. This is the list, the master list, that we share amongst browsers to protect users. Secure DNS is another one which prevents people, particularly telcos, from knowing which websites you're visiting. As I mentioned, Disconnect.me, keeping a list, and the also block crypto miners.
Role of standards.
As I mentioned, standards, sometimes things go well with standards.
We create a lot of the problems at the same time. We're well-intentioned people and sometimes we screw up.
So HSTS was an example of that.
There are other examples.
For instance, the credit card companies working on web payments, they would like, for instance, encoding fingerprinting into standards, which is not amazing, so we've moved away from that.
We have things like...
Now, another problem is that W3C recommendations are literally just recommendations.
They can't enforce things.
So we can even go back to the past when the cookie specification was designed. There was big warnings in there that this was gonna be a problem for society and advertisers didn't pay attention and browser vendors didn't really pay attention and we ended up in the world that we are today. So we are working on continuous improvement. We constantly review APIs.
Like, right now, we've moved geolocation, you can't use geolocation on HTTP anymore.
We've also only allowed third-party context to use geolocation if the top level site, the site that contains, the site that you're viewing, says it's okay for the iframe to use geolocation. Things like that.
So we're constantly evolving and securing the web in this way.
As we develop standards, we have this large list of questions that we go through for every standard and we try to basically ferret out potential issues. You know, who are gonna be the attackers of this API? How are they gonna attack the API? And we ask a whole bunch of questions.
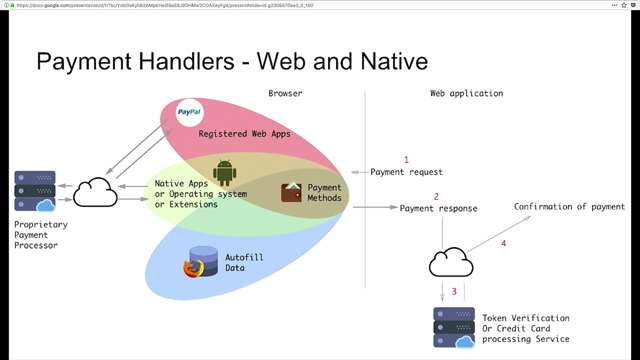
So rest assured that the people working on standards are very much aware of these problems and we, essentially, are concerned and we question ourselves all the time about how do we make our senders better? Quick example from the Payment Request API, privacy of mobile phone numbers and privacy of postcodes.
Really neat example in Apple Pay, Apple Pay will chop off the last number of a postcode in certain locales. So, for instance, in the UK, postal codes go down to almost, down to the building, and in Singapore, they may go down to the building level. So by chopping off parts of a postcode, you can essentially give more privacy, you can widen the net and protect people's privacy. Another more disruptive technology is the Storage Access API, which is a new API that Apple's proposed.
Essentially, it allows trackers to continue working, so particularly dual-purpose widgets like YouTube, but if you wanna interact with a YouTube video, this popup will now appear which says, "Do you want," for example, "video.example.com to use cookies and website data "while you're browsing this site?" So quite a disruptive popup here letting you know that you're actually being tracked. So there are a bunch of rules around this as well, from this API.
So, like, if you interact, you're only allowed to use this thing for 30 days and then you have to re-request access and so on. So we make it much more difficult for these trackers to work.
Now, for developers, as we finish this off, so I implore you to, now that we have an understanding of how trackers work, you may have been surprised that you might have been complicit in this without even knowing.
So you've been complicit in this tracking economy just by using Google Forms or by using a CDN. So really do consider, for instance, like, if you're including social media widgets, do you actually need to include them there? Like, do you need the whole Facebook thing? 'Cause that's actually, the trade-off that you're making by including that widget there is that you're allowing Facebook or whatever company to track your users.
Do you need to have analytics everywhere, like Google Analytics on everything? That might be useful but it might not be.
And remember, when you do that, you're actually, again, fueling this particular economy, which is not great.
Same goes for CDNs.
Maybe have a look at their privacy policy.
You think you're getting all this stuff for free, but at the same time, somebody's paying for it and it's your end users that are actually paying for this. And again, do you need to embed third-party widgets? Even in this talk, I embedded a YouTube video. So, you know, I'm as guilty as anyone because of the convenience but I know the trade-off is that.
So really do consider that.
If you can encode your own video and you can host your own video, for instance, by all means, please do.
So with that, I conclude, and thank you very much. (upbeat electronic music)
Although early web standards forewarned of the privacy risk of technologies like cookies, they never envisioned that the Web Platform would be coopted for global-scale mass surveillance. In response, browser vendors have been working together to clamp down on the most egregious privacy abuses.
In this talk, Marcos will discuss breaking changes and new APIs that will help make the web platform more private and secure, and what these changes will mean for you as a developer and user going forward.
The Web in the age of Surveillance Capitalism
Marcos Caceres, Standards Engineer Mozilla
…
So what is “surveillance capitalism”? As it became cheap to process and store data, personal data became commidified. The term was coined by Shoshana Zuboff in the title of her book The Age Of Surveillance Capitalism, to describe this new method of profit-making. She also observed that personal information had become the most valuable resource.
https://www.goodreads.com/book/show/26195941-the-age-of-surveillance-capitalism
This data is captured through tracking – the collection and retention of data about a user as they use websites, which may be shared without their consent. Sometimes there are good reasons for tracking – measuring sales conversion for your business is not unreasonable, and tracking can help you improve the user experience of your product or website.
So why are companies tracking users? The data ise useful for marketing, but also less comfortable things like measuring social or political views. It gets even less comfortable when you see entire user sessions being recreated.
If you can link this data to one person across multiple sites and interactions, that data gets deeper and more valuable – particularly to people who want to sell you something; or sell the information itself.
It’s particularly problematic that there are hundreds of trackers trying to do this. Who are we talking about? The biggest are companies you would recognise like Google and Facebook.
In addition to collecting data, some tracking methods include surprisingly large forced downloads – imagine the impact of pushing 1.5megs to someone in a developing nation on an expensive data connection.
Tracking techniques use lots of methods including cookies, URLs, ‘supercookies’, fingerprinting (to identify the user by their very specific device profile) and dual purpose apps.
Cookies are simple – key/value pairs. They do lots of useful things like maintaining state, keeping your session active, remembering your login on frequently-used systems. So there’s plenty to like about them, they’re not all bad.
Where things get muddy is when we do something read a news website and the embedded ads, loaded in iframes (different origins), third parties gain the ability to serve things to the same person across multiple sites. This is where you get the sensation that an ad is ‘following you’ or ‘knows things about you’.
Supercookies come from the law of unintended consequences. They can’t be cleared and they persist in private browsing. They exploit browser features that make them resistant to erasure – it’s essentially a hack. The user does not control them and that makes them much more scary. They are really only used for dodgy purposes.
A super cookie example: using an HSTS attack to build up a binary data store, exploiting a trick on each site to set a bit on or off.
Fingerprinting example: this attacks capabilities of the browser to create a unique, identifying profile of that browser.
It’s hard to defeat fingerprinting as the sheer number of data points is so high. The settings it has, the extensions installed, system fonts, viewport size, language, Do Not Track header enabled, device hardware, etc.
You can test your vulnerability using EFF’s Panopticlick (https://panopticlick.eff.org).
This obviously has big ramifications, with incidents like the Facebook/Cambridge Analytica scandal – where personal data was used in political campaigns. The data was harvested when people did Facebook quizzes – data was gathered from people who had not used those quizzes or given consent to share the data.
(Video of the BBC’s Katie Hile, talking about the personal information she found in the Cambridge Analytica; and what that identified about her and her life. Ultimately she decided she had to take her information down, to essentially censor her online life.)
So how do we fix this? It’s hard and requires standards, education, governments, law enforcement and industry/NGO engagement. This is a lot of moving parts; and web developers play a role as well.
So what’s the role of educators? Mostly to teach people more about what’s going on; so people can make better choices.
(Video about Mozilla’s Lightbeam, designed to demonstrate the data being gathered; so people can understand what’s going on.)
An important aspect of industry activity is browser manufacturers engaging with this issue… with one key exception…
…Google has a vested interest in tracking, so Chrome does not include blocking options. So even though we love Chrome, if privacy is important it isn’t the best option.
(Demo of what Firefox blocks out of the box just visiting one website. Edge has similar controls built in.)
Where this gets tricky again is dual-purpose applications. Strict blocking will break sites like YouTube, which both provide useful content AND track the user. So there is always a balance to be found between privacy and functionality.
Firefox use disconnect.me as the basis for tracker data; Safari uses an algorithmic approach; Edge will be doing their own version as well.
So what happens to you (or your code) if you are identified as a tracker? Browsers will partition your code, block your cookies (but tell you they were set), block storage, block sensitive APIs. The browser tries to close the gaps they’re sneaking in through, while smokescreening that fact. This can obviously lead to breakage if not applied perfectly.
Other key industry initiatives include Let’s Encrypt, safe browsing list, secure DNS, disconnect.me and so on.
So what role do standards play? Sometimes standards have unintentional consequences, even when they are good attemps (like the failed Do Not Track)… and even when standards (like the cookie standard) include dire warnings about the risks, they can’t stop bad things happening!
But standards evolve and over time the list of questions and requirements get better at heading off negative consequences. People who make standards are highly aware of all of this. The Payment Request API has lots of examples of privacy mechanisms built in (eg. truncating postcodes).
Of course many of these things will require user-disruptive dialogs in order to give control to the user. Again this walks a difficult line between privacy and usability.
So what about developers? We may not have even realised we were complicit in tracking – just by using Google Fonts or a CDN, we will have contributed to user tracking. They’re hard to remove, but you can start with other choices like deciding if you really need to include social media widgets, Google Analytics and so on.
Ask yourself if you can work around including third party code – whether you need it at all, or you can write your own solutions instead. There’s a lot to think about!
@marcosc