Picking up the pieces – A look at how to run post incident reviews.
(upbeat electronic music) (applause) - All right.
G'day, so, end of last year.
Christmas Eve, my parents have just come 'round for dinner. And the on-call phone went off.
Woke me up, I had to go into the back room, look after things.
And I was sitting there, with a glass of champagne, sitting on my laptop, fixing issues.
And this issue had happened half a dozen times before and I thought, we've gotta do something better. This isn't good enough.
So, I went looking.
But, first of all, my name's Klee Thomas.
I like to think of myself as a clean code enthusiast, a code crafter.
Those of you who've talked to me during the last day or so will know that I'm trying to get the term Middle-Stack Developer out there.
(chuckles sheepishly) (audience laughs) That's the person who's doing everything, the nougety bits in the middle.
I love stupid shirts like this one here.
This shirt is bananas.
(audience chuckles) Yeah. Yeah, I'm the organiser of the Newcastle Coders Group, so if any of you are in Newcastle, come along and say hi. And by day, I'm a Senior Software Developer at NIB Health Funds. So at NIB, and I'm sure where you all work, we're tryin' to do the best we possibly can, to build our software systems that are reliable, sustainable, and work well for the long term.
We're using all the buzzwords.
We've got agile, pairing, TDD, clean code, dev ops, cloud architectures, continuous integration, continuous delivery, and plenty more things. And it's fantastic, we're wonderful, we're stable, but, customers keep asking for more.
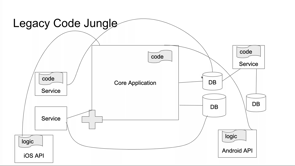
We have these things, and we keep piling in more and more things, and eventually we started building these systems that are more complex, more complicated, and eventually turn into legacy code.
So, we have to accept that, given that we're doing this for the workforce that is more transient, and more than ever before, made up of people who have been in their job for maybe a year, maybe two years.
That, at some point, something's gonna go wrong. Our systems, no matter how well-designed, are eventually going to go down.
So we're goin' to build a culture that is prepared to fail. Like say, we're ready, we can actually deal with this when it comes up. This little GIF here I think is fantastic, and the guy here starts out with a domino that's five millimetres high and then knocks over one that one and a half times the size and so on and so forth.
And eventually you can extrapolate this out where you'll eventually knock down a domino the size of the Empire State Building in New York. All from knocking over this one little five millimetre high domino.
And how many do you think that'd take? 200 dominoes? Maybe 300? It's only 29.
29 dominoes from one five millimetre high domino to something that's gonna take down the Empire State Building.
So, if we look at our software systems in this way, every little failure has the potential to cascade out into something massive.
And so we wanna make sure that our culture is prepared to fail, prepared to recover, and prepared to do the best it can.
This is where I see Post Incident Review coming in. The failure is inevitable but you have a choice at the end whether you wanna learn from it or not.
So, Post Incident Review is exposing, first of all. If you do this well, you're gonna put things on the table that maybe you didn't really want other people to see. You're gonna spend time looking at what happened, what went wrong, how you responded, and how you can improve. I think a good place to start with understanding Post Incident Review is to actually understand how incidents flow, how things happen.
And this how I always thought things went.
Something goes wrong, bang, boom, crash.
You get everyone together, you get people you need, you're ready to go and you fix it.
It's all fixed, patched up.
You're pretty confident that's not gonna happen again but maybe it gonna happen on Christmas Eve, you're not sure. But, you think it's fixed and then you get back to work because we've all got a project manager breathing down our neck saying, we need to get this feature out the door or our runways gonna run out or just the boss is gonna come down and yell at you. Or, just simply, we're pretty much all code addicts and we love running code and like building things and that's why we're here, right? But, unfortunately, when we're looking to build something that's long term sustainable, that's not really good enough.
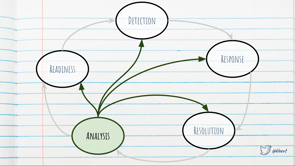
We need to start thinking about our incidents as life cycles.
And the first step in my incident life cycle is detection. First, before you can say an incidents happened you have to say, we know that an incident is happening, we've found out about it.
It's not good enough just to say it's happened. It's like, okay, we understand now this is happening. What are we gonna do about it? How're we gonna respond? The response phase is the most important part of your incident.
This is where you get together all those people. Where you triage something to understand is this something that's just gone wrong all of a sudden? Has this been going wrong for a week? Is it a false alarm and you know, it's just because old made casters, you know and everything's okay alarm and it's going off. In the response phase you work out what're you gonna do, how're you gonna fix this? Are you just gonna turn the alarm off and go back to bed or are you gonna say, we're gonna get to the console in AwS and make this one change that will get everything back together so we can deal with it in the morning.
And that one change is your resolution.
Resolution and response are tied really closely together. A good response means that you'll have a good resolution, things will flow nicely and this will be almost a non-event. A bad response means that you've got half a dozen people in the AWS console kicking stacks, restarting things, hoping to make it better and they're all just getting in each other's way and this is just getting worse and worse.
But, eventually, you do resolve it.
Then, it's on to analysis.
And I'll flick back around to analysis.
'Cause the last stage is readiness.
And readiness is really important.
This is so key to making something that will last for a lifetime.
Readiness is where you say, we know things are gonna happen, things are gonna go wrong.
And finally, out of your readiness, you detect the next thing, and it all happens again. So, I'm here to talk about analysis and how that feeds back in to things.
Good analysis feeds in to your resolution phase. It says, hey, did you have enough people there? Were the right people there? Were you doing it right? It feeds into your response phase and says, how well did we do this? Could we find the things we needed? It feeds into your detection phase and says, are we able to detect things going wrong? Or did we find this bug because somebody called us and yelled at us through our call centre? Or, worse than that, were you looking to implement a new feature and you went into production to look at how it was working only to find that it wasn't working and hasn't been working for six months.
And no one's decided to tell you about it.
And finally, it feeds back into your readiness. The canonical example of great readiness is Netflix where they talk about the tsunami that goes ahead and just starts deleting things in production, takes things down.
So, they are provably ready for anything that's gonna happen.
And I'm not asking you to be that.
You're not ready for that, I'm not ready for that. What I'm asking you to do is write good documentation, have a good understanding about how your systems fit together.
Make sure the person who's on-call knows about the systems they're supporting.
You know, what are scaling groups, have all these things. And work out what you need to be able to deal with the issues that are gonna come up within your system. Obvious question for Post Incident Review is when should I run this? And I think there's two answers to that.
The first answer is straight away, as soon as possible. Because as much as we'd like to think we're all hyper-intelligent, amazing developers, our memories fade and we'd like to fill those gaps with fake memories that we now think are true. So, I think you should be running this within two days. So, as soon as you can within two days.
Maybe you can't run it within two days.
I've booked one in for when I get back to work next week. But, you just need to do it as soon as you can so you've got as much information readily available so you can all learn what happened and what you can improve on.
And the other answer is regularly, all the time, on the small things and the big things.
If you practise this on a little incident, something that affected three users or maybe didn't even make it to production, then when it comes time to deal with that security incident that you're really hoping doesn't get you on the news, you're ready, you're practised, and you actually know what you're doing.
As I said, I went looking into how to improve my Post Incident Reviews and I went through a few stages.
This is sort of a bit of my path of how I got there. I started with root cause analysis.
And this is an idea saying, we're gonna go and find the one thing that has caused our system to break.
And the best technique I could find for that was the five why's.
The five why's is pretty close to what it says on the tin. You ask the question why five times until you get to an answer that's a bit more meaningful than just, oh, the server went down, we fixed it, don't worry.
And the five why's is fantastic.
It's a really great technique.
And particularly if you're in a more of an analysis role, you'll have used this technique to step past that first question when someone says, "Who wrote this feature?" You'll say, well, why, why, why until you actually get to what they're trying to solve. But unfortunately for a Post Incident Review, there's a few problems with it.
First of all, it's not repeatable.
If you go and ask the development team why this issue happened, you'll end up with a different answer to if you asked the operations team.
And what you might end up with is people blaming each other. You might ask the development team why this happened and say, Oh it's 'cause the operations team didn't give us more space on that server, it's all their fault. And the operations team might tell ya that it's all because the does kept running too many logs and don't roll them. So, we start to end up with this blame culture building up, building up and that's not what we want. We all know that we don't want blame culture. But blame is a natural thing.
It happens to all of us, it happens when we're in pain. And, you know, an incident is pain.
Over time, blame leads to fear and fear leads to people hiding and misrepresenting facts. It leads to those fake memories, it leads to people saying, I'm not gonna tell anyone about this small incident that happened because if I don't tell anyone, no one's gonna point the finger at me, I'm not gonna lose my bonus.
And blame's a bit of a weird thing.
Who blames success on individuals? I'm sure none of you have turned around at the end of a successful project and gone, Bill, you Bill in operations, this is all down to you. The developers did a great job, the designers did a great job, but Bill you kept that server up the whole time. If you didn't do this, this project would not have gone ahead.
No one says that.
But they do turn around to Bill and say, it's your fault, mate, you've ruined it.
(audience chuckles) So, we don't want that.
Obviously, Bill's gonna try and find a reason that it's Jeff's fault and Jeff's gonna find a reason to blame it on Jan and then everyone's just not gonna get anywhere. So we wanna start blaming these processes.
Around everything we do there are these processes that say, this is how we do it and we can find issues in there that lead to how we can improve. So, Edward Deming said, "Blame the process, not the people." I think the best place to start with not blaming people is by going back to Norm Kerth's Prime Directive from his Project Retrospectives Handbook.
And that says, "Regardless of what we discover, "we understand and truly believe "that everyone did the best job they could, "given what they knew at the time, "their skills and abilities, "the resources available and the situation at hand." And this has gotta be true, right? Who here thinks they are people in their organisation that are actively trying to bring it down? They're trying to destroy it.
No one.
That's not where we work.
We're all motivated knowledge workers.
We're trying to improve things.
So, a root cause isn't good enough.
So, let's have a look at the idea that maybe there's multiple root causes.
The systems we're building a complicated and complex, as I said before.
So, there's gonna be more than one reason that things fail. For this, I came across the fishbone diagram which puts the problem over on the right, draws out a D line to it and then off that has these bones that are the primary causes. The things that are goin' to break.
Off the primary causes we put in our secondary and tertiary causes and these are sort of coming down to what our individual root cause failures might have been if we were doing root cause analysis.
And if you go through this, you'll find a whole bunch of reasons that your system is broken.
Because, say it's complex.
It's not adding two numbers together.
And this, again, is a great technique.
It's really useful.
It's gotten a long way and it's one that I use a lot when I'm planning out a big game deployment because it helps you to understand how the system might fail in the future.
But I think it lacks a little bit in the Post Incident Review phase.
This is where, because of these heuristics or biases, and we all have them.
They're natural things.
They're the reason that when you went to the coffee cart earlier you got a long black because you have (mumbles). Not feeling great, I don't want dairy today. Whatever reason that is, they help you save time, they help you get through things and they help you understand what's going on. But, unfortunately they make things seem more important than you think they are, more than they actually are in Post Incident Review. And they run this risk where they're gonna start ignoring things or just putting that one to the side. A few examples of these biases are the anchoring bias and the availability bias, which sort of put forward these two ideas as being more relevant.
Anchoring bias is the one we've all heard of in salary negotiation, you don't wanna put forward the first number.
You want somebody else to justify your value. And availability is that thing that's like, well, I can think of it, therefore it's important. And any of you have worked for the junior developer will have seen this, where they come to you and say, this thing's broken.
You say, are you sure? Have you read the error message? Have you actually looked at it? And then you've got the bandwagon effect which is the third one that I see as a big risk. This is where you're sitting in a meeting and everyone else is charging off with this idea and saying, this is what's broken, this is the problem. And you're sitting there going, well actually, look I know I'm the only designer here but if we just made the UI a little bit nicer, it won't wouldn't done this.
Or, you're the only operations person and you say, well, if we set better scaling the system would have stayed up.
But other ones, hindsight bias, outcome bias, confirmation bias.
All these things lead back to the sort side of blame people again.
It's like, oh, if you'd just done this you could've done that, you should've done this. And we start leading into this blame culture again that we really don't wanna have.
So, this is where I've landed now as what I think is currently the best way to run a Post Incident Review.
It's not the only way and in the future I might learn something new as well. And maybe you've got a great answer that you wanna come and propose to me later.
But, I start again with the Prime Directive. Just as we had before.
This is so important just to remind people that we're not here to blame, we're not here to criticise, we're not here to make things worse.
We're here to work at how we can prevent this thing happening in the future.
On top of that, I put down an incident summary. This is a quick overview of what happened.
A TLDR for your incident.
Your target audience for this is the CIO, CEO, you know, the Dev Manager.
Maybe you in the future as your flicking through trying to work out how you solved something the last time. It's somebody who doesn't have the time to go into all the detail but has important things to understand.
Then I get an objective timeline of events. And this is the key thing, I think.
This is where I see actually preventing blame starting is by getting more information.
Making it more public, making it better understood what's gone wrong.
Objectivity is hard, so I achieve it by getting as many people involved as I can.
Everyone who's been involved in the incident has something to add, can add in to this timeline of events, what they saw happening, what information they had, what decisions they made at the time.
On top of this, I like to get anything that's kind of an automated system.
So, if you're an AWS and you've had autoscaling happen or cloud formations gone down, or whatever it is, go ahead and grab all that, put that in there as well. And then go to Slack or whatever other messaging application you're using internal to your business and take all the information out of that.
This actually gives us a great way to understand what's gone wrong.
And then, get more information.
Actively don't hide what happened.
Go through and try and find out what people did and what they did do.
Avoid asking why X happened.
Why again is a blaming word that leads to people hiding things up.
Ask what factors informed the decision because there's a good chance that any decision that was made would have been made by anybody else as well. Because everyone's trying to do the best they possibly can. Out of this, take some key metrics.
Go ahead and understand who was in charge of the incident, if anybody was.
Understand who was involved, link them down. Go ahead and understand how long it took you to acknowledge that an incident was even happening.
How long did it take you to recover from the incident and how long did you stay in each of those phases I mentioned earlier? How long between when you detected something and when you responded? When you responded and when you remediated? And when you started remediating and when it was actually done? Spend some time to understand what the severity was. Was it a fatal incident that took down your whole system? Or just a moderate incident that had, you know, impact on customers, real customers, but maybe they could work around it or it was only a number of customers.
Was it low? Was it a single user incident that, you know, just this one person had a problem because they're on some wacky old browser that nobody's ever actually supporting anymore.
Or, again, was it an everything's okay alarm that's going off in the middle of the night just to tell ya that it's all sweet.
Out of your incident, spend some time going through, understanding what went well.
Something has gone well because otherwise this wouldn't be a Post Incident Review. Your incident would still be going on.
Spend some time having a look at all the phases and understand how you can be more ready.
This and the next step are really key in turning your post-mortem into a pre-mortem. Having a look at how this failure can lead to being better in the future and being more ready for what's gonna happen. Then, go and have a look at what went wrong. There have been things in this process that haven't gone so well.
If nothing else, you had an incident in the first place. But beyond that, they'll be bits that weren't so great, that maybe you're like, Oh, if we just had this piece of information an hour earlier this whole thing would've been done in 10 minutes. Spend time understanding what lead to the actions that were taken because just saying, Oh, that action wasn't good enough is not gonna help anyone. You're gonna identify processes that failed or were missing the pieces that you're like, Oh, I wish I knew about this.
So, have a look at all the phases and again, try and feed back into everything.
And particularly focus on how you can be more ready going into the future.
Document out your action items.
As you've gone along through all your Post Incident Review, they'll be things coming up, somebody saying, Hey, we could've done this.
We need to do this in the future.
Let's rewrite everything because it's all in Angular now and we want to be in React. Let's go back to Ruby on Rails because Ruby on Rails never fails.
Make things, identify the action items you can take that are both small as well as large.
A big system rewrite is gonna be hard to commit to but there might be one thing you can do in a small way to improve things for next time.
Make sure you commit to some issues.
And for those you commit to, make sure you're putting them into your issue tracking systems, putting them into your back logs.
Assign the people and try to prioritise them out. If you've got a product manager that is maybe a bit hard to work with, bring them in to the process.
Make sure that they understand the value of these action items you're putting forward and how it's gonna make the product better in the future. And finally, make sure your action items feed back into all stages.
Again, this is how we turn a post-mortem into a pre-mortem. So, in a quick overview of what I've covered. I've talked about moving from that incident flow to an incident life cycle, where you detect, you respond, you resolve, you analyse and you're ready.
I've talked about how you can avoid blame by having an objective and honest timeline of events that helps everyone to understand what's been going on. I've asked you to identify what went well as well as what went poorly because there is always good things even amidst the worse situations.
I've asked you to track your actions and I've asked you to run your retrospectives on little things as well as big things.
So that you're more prepared for when the big things fail. And finally, turn that post-mortem into a pre-mortem. You can tweet at me @kleetut if you've like anything. If you haven't, if you think that my shirt is stupid, if you think that my shirt is fantastic, let me know. And, I'll see you around.
(applause) (upbeat electronic music)
We all know that the beautiful world of software is like a basketball balanced on a Jenga game. It’s fine while it’s fine but all it takes is a semi colon in the wrong place, a bad database failover or some unlucky road worker to cut a cable and the whole world comes crashing down. Fortunately we’re all good people and when the pieces are on the floor we pull together and get it all balanced again. But then what?
It’s not good enough to just forget about it. Sweep it under the run and pretend it never happened. Production incidents are part of life. More than that, they are great learning opportunities. By examining what went wrong and identifying the contributing factors, we can not only learn how to prevent this happening again, but also pre-empt other issues within our system.
This talk looks at the strategies for Post Incident Review starting with the common place practices including the Fishbone Diagrams, Sticky Note Brainstorming and the Five Whys methods of root cause analysis. This talk will go beyond these practices to show how leveraging modern monitoring practices along side ChatOps we can the contributing factors, not just a single cause.
These contributing factors can be used to find actionable outcomes that not only help prevent the same thing happening again but feed back into the incident life cycle to make the team better prepared to Detect, Respond to, Remediate and Analyse the next incident.
Last year on Christmas Eve, Klee got a phone call and had to jump onto his laptop and fix problems… glass of champagne in hand. But he realised this kept happening and needed to change.
Like any other team, NIB are trying their best to do a good job, with all the buzzwords (agile, pairing, TDD, CI/CD, devops…). But like everyone else, customers always want more and legacy code keeps growing. Things will inevitably go wrong. You need to build a culture that copes with failure and is prepared to recover.
Post incident review determines if you learn from incidents or not.
Production incidents are a lifecycle: detection, response, resolution, analysis, readiness, and back to detection. #code19 @kleeut pic.twitter.com/lM6vpsamIK
— Jason O'Neil (at #code19) (@jasonaoneil) June 21, 2019
Incident life cycle:
- detection – working out that something is happening
- response – you work out what you’re going to do
- resolution – going ahead with a fix
- analysis – pulling apart what happened (this feeds into all the other steps in the life cycle)
- readiness – preparation for next time
- …then back to detection
When should you run a PIR? ASAP! Within 2 days. People forget very quickly and replace real memories with their own version of events. Run PIRs regularly, on smaller incidents as well as big ones – so you’re practised and know what to do.
The path to a great PIR
Root cause analysis – get right down to the thing caused the system to break; and the best solution is the Five Whys technique. Keep asking ‘why’ until you get past the surface reasons for an incident. But beware of blaming an individual; and beware that the people you ask will determine the answer you reach. Blame culture leads to fear; and fear leads to people hiding what really went on.
Blame is weird. People don’t blame one person for a big project’s success, so why do we blame a single person for a big project’s failures?
Blame the process, not the people. – Edward Deming
"This shirt is banana's" @kleeut #code19 ? pic.twitter.com/UF1bA67glv
— Aaron Powell ➡️ Web Directions Code (@slace) June 21, 2019
Go back to Norm Kerth’s prime directive:
Regardless of what we discover, we understand and truly believe that everyone did the best job they could, given what they knew at the time, their skills and abilities, the resources available, and the situation at hand.
A good tool is a fishbone (Ishikawa) diagram, that lets you identify primary and secondary causes for a specific problem.
But you have to guard against biases:
- anchoring – the first piece of evidence is the most relevant
- availability – I can think of it so it’s true (juniors do this a lot)
- bandwagon effect – getting swept up in the crowd
- others – hindsight, outcome, confirmation
…many of them quickly lead back to blame culture. Yet again go with the prime directive of retros.
Other useful things to do:
- Create a TLDR summary of an incident and its resolution.
- Create a timeline of events, with multiple points of view.
- Elaborate
- don’t hide what happened
- don’t ask ‘why X happened’ if you can instead ask ‘what contributed to X happening’, the factors that led to a decision rather than the decision itself
Key metrics:
- who was involved
- time to acknowledge
- time to resolve
- severity
Remember to go through what went well – something has gone well, because you’re in a PIR and not still trying to fix it!
Action items:
- Document them as they come up
- Identify impact and urgency
- Commit to some but usually not all
- Actually do the ones you commit to – put them into tickets and schedule them
- Feed back into all stages of the life cycle
If you can do all this well, your post-mortem can become a pre-mortem: something that will help you avoid doing this again.