Front end migrations in legacy code
(upbeat music) (audience applauds) - Hi, everyone, I'm Tanvi.
I'm originally from...
So I'm originally from Mumbai in India.
This is how Mumbai looks through lens of some really talented photographer and this is how it looks from my parents' apartment. It's a very busy city.
Although I've been staying in San Francisco, United States since few years, I post about everyday life of coder, everyday life of programmer in Silicon Valley, about my workouts and about other beautiful places that I was at on months ago.
So when John and i started talking about me speaking in this conference, I was working at Yelp.
However, I recently accepted an offer with Uber. This is just a disclaimer that today I'm neither representing Yelp nor Uber.
So what are we gonna talk today? Is about what is legacy code.
I had this notion about legacy as something very positive. My elders and parents have always always told me that do something and leave your legacy behind.
Until I came to the world of programming, I realised legacy is not so positive work.
So today, we will go through why legacy code debt is a concern, how you can introduce modern code to a legacy code base and then we would talk a little bit about front-end migrations.
So before we start, I want to tell you a little story about Alice getting lost in Wonderland.
Some of you might already have heard about this story, well Alice was this little tiny girl, she's chilling by an ocean and she sees a rabbit passing by her.
She decides to follow the rabbit in the rabbit hole. Little does she knows what lies ahead of her and Alice is lost, confused and she doesn't know how to survive in the Wonderland.
Why am I telling you this story in Web Directions Code conference? It's because when I joined Yelp, I thought that I was lost in Yelp's Wonderland.
So Yelp has this culture where new hires get to push code into production on day one.
So I wrote a little tiny bit of code and then have a spot of deployment and it took me half a day to just get my trivial code to be pushed into development and I was confused. I didn't know why it took so long but very soon I found out that the code base where I was deploying the code was more than a decade old and it was a legacy code base and hence, it took me so long to get through the production. I had similar experience when I joined research lab in Arizona State University in the United States. When I joined the lab, I was told that we were working on separating the client and server layers and rewriting whole bunch of code to make an intelligent tutoring system.
So the older version of the code didn't work really well in the newer Android and iOS devices.
So we had to rewrite all the functionalities of that code. I had some similar experience when I started working at Oracle in 2013.
With all my experiences, what I learned was that this code which is written by someone else, which is not very well documented and which is often super tightly coupled is called legacy code and it's often confusing and messy to deal with.
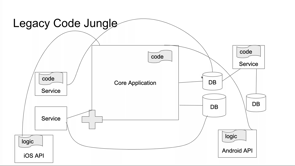
So how is legacy code generated over time? Let's say I have a simple application which is supported by a smaller size database. With growing features, core application code grows and so as the databases.
Things work smoothly, and no one has complaints. Now as part of natural progression, number of contributors contributing to the code base increases and all engineers have different styles of writing code.
So now they make newer services, some work independently, some still heavily depend on the core application. Notice that the core application code continues to grow and with some more passing time, this happens. So even though we have some services working independently and sometimes we need them to do similar things that our core application code is doing.
If I have to give an example, a core application code is assigning a unique session ID to each session that user is logging into.
Now your are independently working service doesn't do that. So what looks easier is copy that piece of code and paste it in your service or even worse, sometimes engineers don't know that what they newly coded was already in existence, probably in more specialised manner, probably not so much in a reusable state.
As a result, there is lots of code duplication, specialisation, there is also logic duplication that happens and over time, a tangled dependency relationship is built between the components and the application. What serve the best earlier is now be serve still good and yet, things work fine.
So why is legacy code a concern anywhere? Well, it's not really concern if your application is not gonna grow in future or if you're working for a company is not gonna go grow in future. But if your application has a projected growth, then the code that can be can come to haunt you very soon. So let's dig into detail as to why legacy code base is a concern.
Architectural decision.
So in a monolithic application, mostly core application is doing whole bunch of work that any model view controller kinda application is supposed to do.
And it is extremely hard to scale this kind of application. Unless the code is broken down into smaller maintainable modules, there's not much of reusability either code duplication looks like a quicker way compared to working on reusability where engineers and managers are constantly juggling between tight deadlines and delivery and planning. When there's a team of engineers working in collaboration, it is not only hard but sometimes impossible to track the duplication that each engineer adds. Altering or modifying some part of the code base can have adverse effect on set of larger part of the code base which you didn't anticipate and a small task that can require an engineer to interact with various teams and stakeholders because there's no clear ownership defined. So due to the problems associated with scalability, reliability, tight coupling and ownership, architectural decisions end up taking lot longer than it should take.
Maintenance.
This one is super straight forward.
Ease of making changes is directly proportional to how complex the code base is.
The more the complexity, you're gonna take longer to make any small change and to introduce any new feature. Also, deployment time adds up and it eventually reaches a point where engineers are just sitting in the deployment pipeline for like half a day or for a day to get their code pushed.
Testing.
So before we get into this, I have a question for all of you all.
Cross your heart and be honest when you answer this. So how many of you have told this to yourself or your team that you will ship the code right away and then come back to writing the test in future? Like next week, next month, next life.
No one? Really? Yeah, I'm part of that too.
But unfortunately, testability of code defines how reliable your code base is.
When it comes to changing any sort of environment, you're changing the backend, you are moving from using Windows Server to Linux server, how well is your code gonna perform? It all depends on how well you have written the test. So if you wanna test any unit changes or any integration changes, functional changes, make sure you have solid tests that catch any unusual things that could happen to the code.
In legacy code base usually, there are insufficient tests and that's why it's so hard to track what must be happening when something goes wrong. Performance.
So if your application is end user facing and if you have lots of user, performance is something that usually you should be concerned about. So in legacy code base, there's creative routing that engineers add over time.
Engineers add few things and then they leave and then there are new engineers working on it and newer engineers don't know why we introduce something that we did long ago and we are usually hesitant to touch that piece of routing.
We don't know what happens (talks).
So with so many request routing, eventually what happens is any request that comes to your application ends up going through lots many layers than usual and it ends up taking more time to get the response. So measurement of time budget in legacy code helps finding those kind of health check for the system. Okay so if I did my job well and if you all have experience working with legacy code, you know that legacy code base and growing code debt is definitely a concern.
How do you fix it? Unfortunately hammers don't fix everything, takes lot more to fix this kind of problem. Bear with me for the next few minutes as I read the secret of fixing this trouble. So how to introduce modern code to legacy code base. There are two kinds of situations with the code base. One is when one start to realise that growing code debt could be a problem in future and second one is, you know for sure that you are in a sinking ship. So preventive measures when taken seriously can save a lot of time and efforts for an organisation.
First and foremost is to recognise the problem. Very simple, right? Before we move into next slide, I want to give a warning about a GIF that I have used in the next slide that it contains uncensored content.
So if you are below age of 18, please close your eyes. So how to recognise if legacy code is actually a problem for you.
One of the most important things is to identify the problem. When you see tight coupling of unlike components happening or when there is difficulty in supporting more users or this one is very simple, you see your engineers getting frustrated when they have to work on the code base, some specific code base and you see Your managers always complaining about indefinite development delays, you generally don't need any more clues, look into reactive measures as soon as possible. Foresee the future.
Another one that comes with experience is not to fall for immediate gratification and think about the future.
As a developer, you know the code base more than your manager does or your PM does. So give hints to other stakeholders of the project that at some point, growing code debt is gonna be a problem if it remains unaddressed.
Put your foot down if you have to but don't be a showstopper.
If you are someone who's looking to lead up a technical position, if you are looking to get promoted, look for this kind of catches.
If you show that kind of faithfulness and if you show that kind of capability to actually work with legacy code and to fix it, it's something that can go in long run.
Control adding new code to the legacy code base as simple as it sounds.
However, how do you actually implement this? Know you tell your engineers not to add code, they'll still do it, you educate them, they forget what they were supposed to do.
So best ways to invest time in creating technical guards. If someone tries to add more code, let the code fail, let the builds fail.
Keep track of the test coverage that you have. If the test coverage is below certain mark, let the builds fail.
This can introduce (talks) to an organisation, engineers will complain, managers will complain that, "Hey, we were not able to go into deployment pipeline, "our tests are failing, what do we do?" Try to explain them why you added technical guards, try to show them the bigger picture of how you are trying to help the organisation by addressing the growing code debt.
Reactive measures.
These could be very different for different kinds of situations.
These measures are really hard to generalise. So you should really look at what works best for your organisation and your code base.
Some of the questions that one can ask to themselves are, is it okay if I shut down the whole application and rewrite it? This was something that we did in research lab at Arizona State University.
It was possible for us to shut down the whole application and create another version of it.
However, when you're working for a company which operates at a larger scale, it probably is easier to iterate smaller things, isolate those smaller services, fix those legacy or growing code debt and then merge it to the larger code base.
I can't emphasise enough for this point.
Smaller refactors are the way to go.
When there's huge application and you don't know where to start with, just look at what your team owns or look at what are some very crucial services, can you segregate that into smaller modules and then tackle them.
Smaller modules are very easy to track and monitor and having smaller reliable modules are much much better than having large flaky code base. Broadcast and communication.
So spend money and time in education.
Educate your engineers, educate other developers in the community and let them know about any refactor which you are tackling, let them know about any refactor in progress. There should be awareness in the organisation so that when the piece of code that you are working with, if it has some unusual effect on some other part of code that other team owns, they will know whom to report to, they will know that that could be linked with what you're working with.
Monitor the metrics.
So code reliability is determined by tests that you provide. Make sure that you know how much piece of code is covered by tests, what modules are not covered with tests and also make sure that you have time to decide on the metrics study you wanna monitor.
So when we had refactor in progress at Yelp, we had huge Splunk dashboard that we put on TV screens and put near our team's spot. So if anything goes unusual, we know that we shall look into it as soon as possible. There are a lot of tools, a lot of third party applications that your organisation can use.
SignalFx, Splunk are very popular for tracking the metrics.
Also, there's this tool that a lot of companies use in beta called Bugsnag.
It helps in reporting client side errors.
Dark launching.
So a lot of big companies do AB test kind of experiments before they roll out new features.
If I have to give a very simple example, if a person has to decide if some sort of button should be blue in colour or yellow in colour. So in that case, these companies run experiments to find out what colour is most liked by the users. So some users are shown blue colours while some other users are shown yellow colour button and then they find out which is the most well perceived colour by users. This prevents personal biases and we should be trusting data more than people. So it's a good idea to roll out the refactor code in this manner.
Serve the refactor code only to 1% of the cohort or 25% of your total users and track or monitor the performance of the refactor code that has recently been pushed.
If things don't look great, go back, iterate from there, if things look great, then replace the old code entirely and push this out to a hundred percent of the audiences. Automated code refactoring.
There are ample of code refactoring tools that could automate refactoring efforts.
Yelp created one named Undebt.
Undebt allows defining complex find-and-replace rules using Python that can be applied quickly to an entire code base with a simple command. So try to automate as much things as you can. Spending time in automation can save a lot of time in doing manual refactoring.
So automation goes long way.
Coming to front-end migrations.
This is one of the favourite images that now I like to have a look at with time. So in last few years, in front-end world, we have had lots of new things coming every morning. There has been Checkready, there has been (talks), there has been Bootstrap, WordPress, Angular and then recent one is React.
So with passing time, things keep changing in the front-end world and it's almost inevitable to not go through front-end migrations.
If you are a front-end developer, you know if you don't keep up with what's happening in the outside world, in five years of time, you're gonna be out of job because if you are used to working on Angular, you don't know if it's gonna be still popular five years down the line or 10 years down the line.
So question is how to tackle these migrations. Can we make the process of migrations as painless as possible? Let's first start with diving into the root. Why do you care about migrations? Do you want to migrate to React because the whole world outside is talking about React? (talks) can be a good enough reason for migration. Or do you wanna migrate to Angular because that's your personal favourite framework to work with? Nope.
Recognising problem in current code base is a golden step in the process.
It's very important that the team gets together to come up with existing problems and provide unbiased reasons for how the migration could address some of these problems.
After this, comes the step of defining problem. Problem definition should be no, as concise as possible. You ask your PM, you ask a new hire who recently joined your team that what are you accomplishing this quarter? And they should be able to give you answer in a statement that we are working on to migrating from Checkready to React in an iterative way.
When you have a solid technical document in place, life won't throw only lemons at you and I can vouch for this one.
In a lot of big companies like Google, LinkedIn, developers demand for a reasonable time out of their schedule just to write the technical specs and work on proof of concepts before they actually start allocating resources on to migrations. So imagine for companies operating at scale of Amazon or Google, there's always someone working on migrations or someone working on deciphering the legacy code and reducing the tech debt. I found this format on internet which I thought I could share with you all. So this technical proposal guideline is kind of something that covers mainly all the aspects of why you should be writing technical document. So some of the things which are really essential is identification of the problem and justification for the proposed work.
What is the problem that your current code base is going through? And then really working on the theory of what work are you proposing and then giving a proof of concept to that theory and to see if that theory works with the code base that you have, what your organisation has and identifying critical needs at this point can be very, very important or can be very useful. If you know that your code base has not been migrated in over like five years, you know that there's gonna be a lot of issues that you will have to deal with when it comes to scaling because a lot of things change in cloud computing in last five or 10 years, you probably want to add AWS storage to your code base. What are some challenges that you could possibly face. If you can identify those things early on, that could be really helpful.
And then coming to writing the technical approach. It's very healthy to discuss about all the choices that you have on table when it comes to what are different approaches that you could take for a migration.
So let's say my code base is in Checkready and now I have option as to where what new frameworks I'm looking at.
I have Angular, I have React, I have something else. So just make a table of what weighs the most. If your engineers already know React, that could be possibly a plus point.
If Angular framework is something that could go well with your back end, that could be a plus point there. So just weighing out all the options and discussing about all the technical approaches.
Even though the ones that you're not taking, putting them onto document and sharing this with larger audiences can give a lot of different perspectives.
And then a little bit of project management work, defining the task early on and defining the estimated timeline as to how much time a specific task could take could be useful and a PM could then take over project scheduling and then this is something that falls into an area where a PM knows as well as a developer and tech lead knows better, it's about estimated cost. A cost of spending your service in AWS instance, how many workers you are gonna be needing? Will you need to use monitoring platforms outside of what you have already been using? Is that gonna cost you? What is the cost for each developer day that you're gonna spend doing the migration. So yep, this is like a document that is something similar to what a lot of companies use.
I wanted to give an example of why we decided to go through a migration at Yelp in 2017.
This is the screenshot of our styleguide component that we display on that Yelp styleguide website. So we have some basic components that the entire organisation reuse more and more so that is less of code duplication.
One of such components was spinner and this is how the code look like when we only had jQuery and JavaScript in the code base. So engineer had to make sure that they used the relative class names, they all support the definition of spinner, spinner button and then they write this on click function. However, we figured out that this probably doesn't give the best developer's experience. If a developer misses on what is the definition of spinner button, this thing is not gonna work. So we identified that we can make this lot better and this is the screenshot of how the spinner component looks in React. All you gotta do is import the spinner container component and then rest everything is extracted.
So just identifying such pattern that, "Okay, migrating into React "can give better developer experience, "we could save on lines of code, "things are gonna be much faster," those kind of things should fall into the document is what I'm trying to highlight.
So after defining the problems, next thing in the technical spec that we can focus on is defining the strategy.
Do you have any reusable components or other root level styleguide components that your organisation uses? If so, do you wanna tackle them first? Do you wanna first migrate to a smaller components and then look into how those components are used in bigger services.
Another thing is building the infrastructure. So if you wanna migrate to React, if you want to render React on server side, do you have means to do so? Or will you need your code base of Java or Python to give a way for this piece of code that you want to render on the front-end on server side? So make sure that you have the infrastructure ready and then you look into rest of the things.
Build community of supporters.
So when there is a huge migration involved, it's not only your team who wants it, probably there are other teams in the organisation who are interested in that and who can get benefited from this kind of migrations.
So look for help.
See if any of those engineers are ready to or willing to work on some things that can make your life easier.
Do they have more allocation in terms of resources (talks) use them.
Metrics monitoring and support.
Make sure that you spend more time on knowing how you're gonna monitor the performance before you get into the migration 'cause the worst case could happen is you migrated your code from one technology to another framework and then eventually found out that this only made your application slower and that will be a bummer if you know that after you spend months into migration.
Also attack small problem first.
This one is my favourite, can't emphasise more. After migration steps, let's fast forward to the times when let's say your team successfully finished doing a migration. You went out, had drinks, celebrated the victory and moved on to next project.
Don't do that because what efforts that you put, your team put is really valuable for some other team or it's really valuable for other engineers who are probably looking into going through similar migrations.
So make sure that you keep monitoring the results. After three months, after six months when you have more users, do things look differently? Keep an eye on that.
Build case study with whatever work that you did whether it's successful or whether it's a failure. Make sure that you shared your case study with others so that others can learn from that.
Retrospectives are something that we always did in Yelp after every project that gets over, all the engineers, PM, EM who worked on that project, we come together in a room for like 30 minutes, 45 minutes and we look at what we did in the project and if we could do something differently that could change for our future projects and broadcast this in the community.
If you know that, if you're starting a new, if you start to use a new framework and if others are interested in using that framework, then you will automatically have that kind of support in the organisation.
This is a project retrospective template which I think is very similar to what a lot of companies use.
So this usually talks about the work that you put, did it go well, if so what did go well? What didn't go so well? Are there any challenges that are still bothering the team? Is there any way you could improve? Could you improve in communication? Could you improve in writing the tech spec? Could you improve in implementation? Or any sort of other things.
So yeah, that's all I got.
I hope this was useful.
Working on legacy code is something that I have been doing in a lot of jobs that I switched and from my experience, I found out that existence of legacy code is a supernatural phenomena in front-end world and there are a few things that only you can answer, that only you can know in your code base, know if modularity works versus how much dependency your code should have and a hammer doesn't fix everything. It takes lots of planning, communication, patience and dedication to execute migration.
These migrations are inevitable.
Also escape from the wonderland of confusion. And I also wanted to like share a few things here. So this is Twitter engineering blog that I had subscribe probably in like 2012 and I always get a mail when there's new post that they have.
It just gives an idea of what companies like Twitter are using, how they are tackling their migration strategies, how they are introducing new things.
This is something similar so like GraphQL is an another new thing that I had worked on before leaving Yelp.
And I took a lot of inspiration from how other companies started using GraphQL. So following few people on Twitter is also my favourite thing to do.
So yeah, that's what I got.
- [Man] All right, thank you.
(audience applauds) (upbeat music)
From plain old JavaScript to jQuery to React / Angular! How do you deal with migrations to newer front end tech stack? Or even worse, how do you introduce newer technology within legacy code jungle?
This talk will provide helpful suggestions on how to deal with the tangled web of legacy code created over time. It will address approaches to effectively plan for refactoring to comply legacy code with a modern framework.
Tanvi starts with the story of Alice In Wonderland, going down the rabbit hole – little does Alice know what lies ahead. She’s lost and confused and doesn’t know how to survive in Wonderland.
This is how Tanvi felt when she joined Yelp. Yelp has a tradition of people pushing code on day one – and it took half a day just to get a trivial change pushed. It was a legacy code base that was difficult to work on. Tanvi had to learn how to survive in this strange Wonderland.
Tanvi Patel navigating the legacy code jungle #code19 pic.twitter.com/fewEWWxKuE
— Web Directions (@webdirections) June 21, 2019
How does the legacy code jungle grow? As the size of the team and code base grows, different styles come into play; and the code starts to get messier. Eventually you find duplication of logic and a tangled set of dependencies that are difficult to unpick.
So why is it a concern? If your application isn’t going to be kept, not so much. But if you need to keep growing and extending the application, it causes problems:
- architectural decisions – scalability, re-usability, ownership and tight coupling
- maintenance – code gets more complex, changes take longer, deployments take longer
- testing – code gets harder to test, particularly when “we’ll come back and write tests later”. Legacy code bases rarely have sufficient tests.
- performance – the multiple layers of tangled code slows down the app. It can help to set a time/performance budget.
So how do you fix it? There’s no one-size-fits-all solution.
Preventive measures:
- This may mean taking preventive measures – this may happen when you recognise the problem, looking ahead and realising you need to make changes to avoid future problems.
- Recognising the problem: tight coupling of unrelated code, frustrated devs, slow updates.
- Forsee the future: don’t fall for immediate gratification. Put your foot down if you have to.
- Control adding new code – avoid adding to legacy, invest in training, use code guards.
Reactive measures:
- rewrite or iterative fixes? This depends on the team and context. Do you have the opportunity to shut down the app or parts of it, to rewrite?
- smaller refactors are usually the way to go – break it up into smaller chunks, that can be more easily addressed and subsequently monitored
- broadcast information – educate everyone about the refactoring that’s going on
- monitor with metrics – invest in writing tests, monitoring and error detection (including client side with tools like Bugsnag)
- dark launch – run experiments and test with small cohorts, monitor before rolling out to 100%
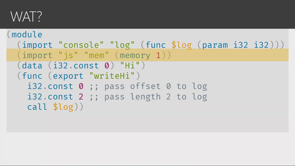
- automated refactoring – Yelp built their own tool ‘Undebt’ that defined complex find/replace rules in a python tool
Wild Wild Web. #code19 pic.twitter.com/lUSoao7RDa
— Connor Deckers (@connordeckers) June 21, 2019
Frontend migrations:
- the frontend changes relatively quickly, so it’s likely you’ll need to change your UI at some point
- have good reasons to migrate – FOMO/“I like X” is not a good reason
- define ways to do it – create a proper technical specification (Tanvi showed an example of a formalised tech proposal and project plan)
- identify components that can be migrated – example of changing a spinner from jQuery to React
- define strategy – are you using any common components that you can refactor in place? what infrastructure will you need? who are your supporters in the organisation and how will they get involved? what metrics and monitoring will you use?
Post migration:
- monitor the results
- build a case study – it may be useful to others, so share the knowledge
- run retrospectives – what might you do differently in future?
- broadcast that information in your community
Legacy is a natural phenomenon, migrations are inevitable. It takes planning, communication, patience and dedication.
Escape from the Wonderland of confusion!