Mastering the JavaScript Engine: A Deep Dive into the V8
Introduction to JavaScript Engines
Anirudh Sharma, from Delhi, India, opens his presentation by introducing the topic of JavaScript engines, with a focus on Google Chrome's V8 engine. He aims to discuss the V8 engine from theoretical, practical, and developmental perspectives.
Understanding JavaScript Engines
Sharma explains why developers should care about JavaScript engines, highlighting their role in executing code and the impact on technologies like WebAssembly.
Advantages of Understanding JavaScript Engines
He outlines the benefits of understanding JavaScript engines, including better technology differentiation, insights into code interpretation and compilation, and the ability to write optimized code.
Agenda: JavaScript Fundamentals and V8 Engine
Sharma sets the agenda for his talk, which includes a recap of JavaScript fundamentals, a deep dive into the V8 engine, and how this knowledge can help write optimized code.
JavaScript: The Language of the Web
He discusses JavaScript's role as the web's language, its synchronous and single-threaded nature, dynamically typed characteristics, and support for multiple programming paradigms.
JavaScript's Execution Context
Sharma explains the execution context in JavaScript, covering memory creation, code execution phases, and how execution contexts are managed in a call stack.
JavaScript Engine Components
He details the components of a JavaScript engine, including the memory heap, call stack, garbage collector, web APIs, and task queues.
Deep Dive into V8 Engine
Sharma provides an in-depth look at the V8 engine, discussing its architecture, the role of bytecode, and the TurboFan compiler.
Evolution of the V8 Engine
The talk shifts to the historical evolution of the V8 engine, its various iterations, and the introduction of optimizing compilers.
V8 Engine: Ignition and Bytecode Interpretation
Sharma covers the introduction of the Ignition interpreter in the V8 engine, its benefits, and the role of bytecode in optimization and deoptimization processes.
Parsing in JavaScript Engines
He explains the parsing process in JavaScript engines, including the roles of the scanner and parser in transforming JavaScript code into an abstract syntax tree.
Exploring Abstract Syntax Trees
Sharma delves into abstract syntax trees, how they represent source code, and demonstrates how to visualize them using tools like astexplorer.net.
Just-in-Time Compilation
The presentation moves to just-in-time compilation, its advantages, and how it combines interpretation with ahead-of-time compilation.
Optimizing Compiler: TurboFan
Sharma explains the role of the TurboFan optimizing compiler in the V8 engine, detailing its function in processing bytecode and type feedback.
Optimization Techniques in JavaScript
He discusses strategies to optimize JavaScript code, focusing on object properties, function argument types, and object property ordering.
Writing Optimized JavaScript Code
Sharma concludes by emphasizing the importance of writing optimized JavaScript code and how understanding the V8 engine's architecture can aid in this process.
Closing Remarks and Q&A
In his closing remarks, Sharma thanks the audience, shares his contact information for further discussions, and opens the floor for questions.
Hi everyone.
I hope you are having an awesome conference so far.
So I am Anirudh Sharma.
I am here from Delhi, India, and I am currently a pre final year undergraduate pursuing Bachelors of Technology.
So today I'm here to talk about the JavaScript engine and particularly the V8 by Google Chrome.
So we'll talk about the V8 engine, theoretically, practically, as well as how it is relevant to, every one of us as developers.
So already Mark has given the introduction and we can start with the presentation.
So the first thought that comes to our mind is why should we care actually about the JavaScript engines?
We are coding in all our front end frameworks or our back end technologies.
But why do we need to dive deeper and deeper on the low level to understand how the things are worked on by the browser engines and how your high level code is converted to the low level code.
The three reasons that I can think of are, first of all, you can better distinguish technologies like WebAssembly on the web.
You understand how JavaScript and WebAssembly are differently executed in different pipelines in the browser.
Secondly, you get to understand how your high level code is interpreted and compiled to the machine code through different methodologies and, what is being currently pursued by every browser engine.
Thirdly, we'll talk about, how you can write more optimized code.
I am sure that you all try to pursue the good practices.
But, there's even more to that.
If you understand how the code is being executed, you can write optimized code on your developer level.
So this is going to be the agenda for this talk.
We'll have a very quick recap of the JavaScript fundamentals and the particularly the runtime environment.
Secondly, we'll dive deeper into all things V8 engine.
And lastly, we'll see how this knowledge can help us write more optimized code.
We're talking about JavaScript.
It is the language of the web, originally developed to have the dynamic content and, later evolved throughout the years to what it is now.
Secondly, it is synchronous and single threaded.
Executed, one part of code is executed once at a time.
And, thirdly, it is a dynamically typed language, so you don't need to specify the types, for the variables and the properties.
Next, it is a prototype based inheritance model, different from the class based model that you might be aware of being used in C++.
And lastly, it supports functional programming.
So it is a multi paradigm programming language.
It supports functional programming, the class based programming, and a couple more.
You get to work with closures and basically use all its advantages.
Next up, talking about the execution context.
So everything in JavaScript happens under a global execution context, which is created as soon as your script file is, JavaScript file is loaded in the browser.
And there are two phases in the execution context.
First is the memory creation phase, and second is your code execution phase.
The two components being memory component and the code component.
In the memory component, in the first interpretation only, your variables and functions are declared, but they have undefined values and they are not initialized basically.
And in the code component, that is the code execution phase, the values are assigned to the variables and the functions.
And the interesting thing here is whenever your new function call is made while in the code execution phase, a different execution context is created with its own separate memory component and code component.
And all these are stacked up in a call stack so that everything is returned in the order.
When your complete code is being executed.
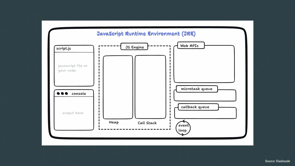
So this is how the runtime environment looks like and the different components of it.
You have the JavaScript engine at its heart with a memory heap, a call stack, and also a garbage collector, which is actually missing in this one.
You have your access to the web APIs, like the Fetch API, your navigation, Bluetooth API, and all those.
There are two types of queues, microtask queue and the callback queue.
The microtask has a higher priority, so it takes back the callbacks from the promise, from all the promises and the fetch API.
While your callback queue also takes callbacks, but it is of a lower priority, and these are, pushed into the call stack once it is empty and your first phase of, code execution is over.
So talking more about the JavaScript engine.
As we talked, there is a memory garbage collector and your call stack.
So at the bottom of the call stack, there is a main function that is your global call, which is put into the stack at the start of your execution.
And then eventually all other functions are stacked up into the stack and following the LIFO principle, they are popped out.
So that everything is written in order.
So now finally, getting into the engines and the, there are, different types of browser engines available and, being used by different browsers.
V8 being used by Chrome, Node.
js and Deno for the server side and also Chromium browsers like Brave and a few others.
The SpiderMonkey is being used by Mozilla Firefox with its different compiler within than what is in the V8.
Your JavaScript core is being used in Apple Safari.
Chakra was being used in Internet Explorer and, for a couple of years in the Edge as well.
But recently Microsoft Edge has also shifted to the V8.
And, the same thing is with Opera.
It used to have Carakan and but now has V8, for the engine in it.
So now what exactly does a JavaScript engine do?
this is your source code, which is the JavaScript and then comes your machine code.
And these are all the main steps that are being happening along the way to get your code executed.
So this is typically for what we are at now, but it has not been same in the past few years.
The engines have evolved and we'll be talking about that.
From where and why did they reach for at what they are now.
So there is parsing at the start.
Then you get your abstract syntax tree.
There is then interpretation and finally compilation so that we get to the machine code.
So this is exactly what the V8 engine architecture looks like at present.
You have your parsing at the start.
whenever your JavaScript source code is, downloaded through the network, then you have a abstract syntax tree created, which is then, used by the ignition interpreter to basically generate byte code, which is your source of truth, for further execution.
And you don't need your JavaScript for anything, for further in the execution.
So you can get rid of that from your memory.
And then eventually that bytecode is used by the TurboFan compiler to generate the optimized machine code based on your machine architecture.
So we'll talk about them in pretty much lower level details, but before that, let's have a look at the evolution of the V8 engine over the couple of like last couple of decades.
Originally in 2008, V8 was created, taking into consideration the complexity that was being, introduced in the world of JavaScript.
So you had your same parser abstract syntax tree from the start, but initially you had Codegen as the baseline compiler and it was the only compiler.
So you got your semi optimized code.
There was no, like a second level optimization.
And this was the machine code that was being used to basically execute your JavaScript on the browser.
In 2010, the team introduced a two way process, which was first one was the baseline compiler.
And secondly, there was an optimizing compiler, which was Crankshaft.
So the changes that were made was that the, the first compiler was used to just quickly run the JavaScript on the web, load, load the initial things and get the type feedback, which was later used by the crankshaft to optimize the code in a much better way so that you don't need to go through the baseline compiler again and again for similar functions.
And then in case.
your type feedback gets wrong at some point because you can, obviously change the properties and the types in JavaScript later on in the code.
So your optimized code is then de optimized to, again, to the, baseline compiler and the optimization takes place again based on the new type feedback that is gathered.
So in 2014, your turbofan compiler was introduced as another optimizing compiler and the crankshaft and turbofan were being used parallelly based on different conditions and use cases.
So the optimization was being switched between those as per the need.
So now coming to the compiler pipeline in 2016.
So the, the architecture was as complex as this.
There were three, like ways to compile your code into the machine code.
And the new one that was being, was introduced was the Ignition and the, bytecode interpretation.
So what happened in that was that instead of directly compiling the JavaScript into the machine code, you were using bytecode as the source of growth in between.
So the Ignition was an interpreter.
Before that, the Full-Codegen and the optimizing compilers were being used.
So interpreter was introduced to reduce the memory usage and also get the bytecode in between so that you don't have to keep your JavaScript in the memory.
You can get rid of that because the optimization and deoptimization was being done through the help of the bytecode only.
So coming to the final 2017 architecture.
the previous ones were removed and this was kept as the one because the things were getting complex and the team wanted to go, with the best one for the future evolve evolution and the enhancements.
So this was the one that was adopted.
Also talking about the WebAssembly pipeline, this 2017 was the year when the WebAssembly was also taking off and the Chrome worked on the different pipeline.
So WebAssembly pipeline has two compilers, a baseline compiler called Liftoff, and then the optimizing compiler is the TurboFan only.
So as you can see this image, so whenever a function call is made the liftoff compiler takes it and compiles it to the machine code.
Now, if the function call is made more than two times, the function is considered to be hot.
That is, it is being called again and again.
So the TurboFan takes the command to optimize it so that you don't need to go through baseline compiler again and again in case of a similar function call in the later parts of your code.
And then you get a optimized code and then it is used for further execution.
Now coming to the first part of the architecture, which is the parsing.
So parsing is basically transforming your JavaScript code into a much better structure by removing the unnecessary things like semi colons or other stuff which is not required for the execution part.
And there are two parts to the parsing.
One is the scanner and second is the actual parser.
So what scanner does is it converts the JavaScript file into a list of tokens.
And these tokens are the one that carry the code without all the unnecessary details.
The work of parser is to actually take that list of tokens and convert it into a tree, which is known as the abstract syntax tree.
So it is a very structured form of, you can say the visual of the code, which we'll say, see in the next slides.
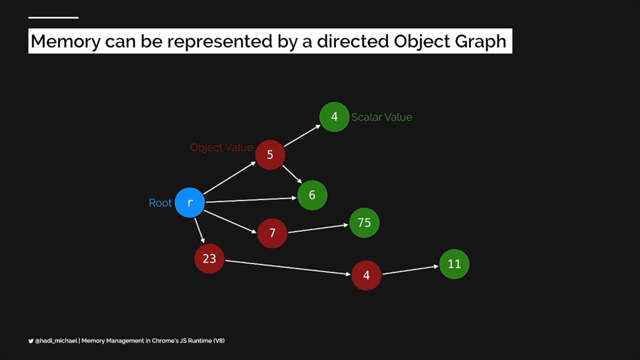
So coming to the abstract syntax tree, this is a tree that represents the source code and at each node, the, a new construct occurring is denoted.
So if you see through this picture, yeah, you can see, a typical tree starting with the function literal, then the block scope and the further variable or the function declarations as per the code.
These variable proxies are created and eventually literals are assigned to a different branch whenever the object is initialized.
So to, to see how was abstract syntax tree looks like.
You can go to this website called astexplorer.net.
You can type in your code and see how the syntax tree looks like.
So for example, I have taken this code example of where we have initialized a constant number with the value 5 and there is a simple function that returns the value triple of that number.
So if you put that on the left hand side, we get this tree.
You can also see the JSON format.
If you are comfortable in that, but the abstract syntax tree is something like this, which can also be brought back to the original project flow by implementing simple root traversal.
If you are familiar with the tree data structure.
So this is your base program and you can see the different value properties attributed to it.
I'm not very sure what everything and why is it being included, but I can walk you through it.
There is this firstly variable declaration and, if you further expand this, you will see the ident identifier is, the declaration with the name number you can see here.
And then the literal, which is five, is being assigned to it.
It, is included in the literal, property.
Collapsing it back again.
And then going to the function declaration, which is the second part of this code on the left hand, you can see the body with the block statement and also a params is being included here because the number is being passed to the function.
Then in the return statement, we can see it has shown an argument with the name binary expression because three times of the number is a binary expression.
The operator is mentioned, and the right identifier is your number again, while the left one is the number three.
yeah, you can see this and also JSON is the all expanded form if you wish to go through it.
So that is how a abstract tree looks like.
Coming back to the presentation.
Now before we get into the later parts of the architecture, the thing that I would like to discuss on is the just in time compilation.
So there are generally two types of compilations which are ahead of time and the interpretation.
The ahead of time compilation as the name suggests, the code is compiled already and then executed later.
Everything is compiled at once, so it is used in languages like C++, Java, while the interpretation is used in dynamically typed languages like JavaScript and Python where your code is executed line by line.
So what just in time compilation is, it is a kind of a perfect combo of both of these.
To basically achieve better speed and effectiveness in case of dynamically typed languages like JavaScript itself.
Cool.
So finally, Turbofan and Ignition are coming.
So Ignition is typically a bytecode interpreter for JavaScript used in the V8 engine.
So why it was first of all introduced in the architecture, we already had the baseline compiler CodeGen.
So the three reasons were first of all, reduced memory usage.
The, as we discussed, the bytecode is the new source of truth and you don't need JavaScript any longer after your abstract syntax tree is being interpreted to the bytecode.
So the code is being removed from the memory and the memory is freed up for other tasks.
Secondly, there is a reduced startup time.
So in case of compiling with the baseline compiler, your high level code was compiled to machine code directly.
So it was considerably taking longer time than what was being taken in compiling in interpreting your JavaScript code to the bytecode.
So the startup times were considerably very fast and the websites were loading quicker than how they were performing earlier.
And the last thing was reduced pipeline complexity, as we could see that in 2016, there were three types of ways and the team had to define different use cases and conditions for which one to pursue in different types of code execution.
So finally, the complexity was removed and we had just one architecture for all possibilities.
what is Bytecode as we discussed it, is the source of truth for optimization and de optimization.
So whenever a de optimization from the machine code back to the interpreter is happened, so you get your original bytecode and then the new type feedback is utilized to, basically create a new compiled machine code for the, present architecture of the machine.
Secondly, we talked about JavaScript code is now no longer needed, and you can get rid of that from the memory.
So you can have a look at the different byte codes.
So your byte code is half readable.
If anyone is familiar with the, how many of you have had a chance to, learn about microprocessors or assembly language?
Cool registers.
Yeah.
So you might be able to figure out, quite a few things from this.
So if I walk you through a couple of commands in this, if you have a look at the LDA0 first command, the A in that stands for accumulator, which is the main, register, while there are other general purpose registers as well in your system.
So A is the accumulator and LD means load.
While the zero is the zero value, so that LDA zero depicts that load value zero in your accumulator.
Then for the second one, it means load a small integer of eight bit into the accumulator and so on so forth.
The binary operators add, sub, multiply- they are, pretty explanatory in themselves.
If you just add and write a register name in front of that, it means add this and what is in the accumulator.
So accumulator is your main register.
So yeah, these are all the bytecodes.
These are like pretty helpful when you are trying to decode the bytecode for any code, base.
And we'll have a look at one of those.
So for example, this is your one liner code in the high level JavaScript.
Result equals to 1 plus the property x of the object and here is the bytecode and the machine code for that.
So in the bytecode, if you see LDSMI, we talked about load the small integer in the accumulator star R means, star R means the assigning the next value to the register R.
And then the later on add or the load accumulator with the name property.
So you can take help those help of those previous codes in the last slide to basically understand to a good extent that what the bytecode is depicting.
And lastly, machine code, which is almost, non readable to the humans.
There are a few things that you can like basically interpret from it, but that is not very useful to us for the present thing.
Coming to the Turbofan finally, it is the V8's optimizing compiler.
What it does is it takes bytecode and they type feedback from the initial run by the, interpreter, and then combines, compiles them to, and create an optimized code.
So for in case of the optimization, the earlier optimized code is thrown away, and, using the new type feedback, it is compiled to a different machine code all together, which is used for further calls if no more de optimization is required.
Now to, start with the next stage of the presentation, we need to be familiar with what hidden classes are and also inline caching.
So hidden classes is a concept to basically access the object properties in a very faster way, if they have been, used in the previous parts of the code.
So for example, if we take this simple example, so whenever your, user function is executed, a first hidden class, for example, named user zero is created.
So you are always directed to this hidden class.
If this sort of function or an object based on this is being called in the later parts of the code.
And then event, further, whenever you assign the, property to this object, a new hidden class is created.
We'll see how these are being created.
So for the initial thing, your, a new user object, for example, is initialized, like a user zero equals to new user.
So as soon as that is created, you are directed to this first hidden class, which was created in the second line, user zero.
And this, hidden class is further redirected to other hidden classes if you, assign the other properties in the further lines of the code.
for example, then you assign the name variable to that particular object.
So then the class pointer takes you directly to that second hidden class, which was, hidden class user1 and, hidden class user1 is connected to the initial class and they are, redirected to each other through the pointer, the offset is the, index of the property.
So the name property is on the offset zero and further your phone and address would be on one and two.
So this is very helpful in the case of accessing the object properties very faster.
Otherwise it takes you through this complete process.
And yeah, and finally, when you assign a phone number, so this is a third one being created.
And there would be one more for the address as well.
So inline caching is basically nothing but, having track of the object that is being, called again and again through the hidden classes.
So you don't go through all this process once again, and just directly access that, hidden class for, once.
So that is not very helpful.
Coming to the garbage collection and the V8 engine.
So there are generally two types of, algorithms or methods that we can say are used for garbage collection in general, not for V8.
and the two, they are mark and sweep.
And secondly, the semi space collector.
Mark and sweep is, very traditional algorithm in which there are two stages, for the mark.
The first stage, which is called the mark stage, it is basically going through the root set in the heap memory, and then marking all the, objects which are, marking all the z's [???] Which are active and being used.
So they are not removed from the memory.
And in the second stage of the algorithm, which is the sweep stage, the, sorry, the, all the variables or the functions that are not being used are swiped off from the memory so that we get rid of them and have further memory to be available.
The second one is the semi space collection, which was, derived later on because Mark and Sweep had, had to scan the entire heap which was, very slow, and, secondly, your program was paused during the duration, so the, things were a bit slow at that time.
what the semi space collection did was it, splitted the, memory heap into two equal spaces and, used a from space and to space, between those, to recursively point different variables and functions in the memory heap.
And this was considerably faster, although used a little bit higher memory, but the advantages were pretty more.
And it was used at different places more often.
what V8 does is it uses a good combination of both of these.
your memory heap is created into two parts, a young generation, and the old, generation, the, semi space collector takes part, takes care of the younger generation while the Mark and Sweep algorithm is used in the older generation.
So for example, your first object gets through the first garbage collection and it is currently active.
So it is moved from the nursery part of the heap to the intermediate one.
If it gets through the second garbage collection as well, then it is shifted to the old generation and the old generation is now coming under the Mark and Sweep algorithm.
So the benefit of using this type of architecture is that in the old generation, since it is using Mark and Sweep, is this type of garbage collection is done not very frequently in the code.
So the things are not blocked.
More frequently, if they, were just using mark and sweep and the young generation, since it is using semi space collection is done very frequently to get rid of the unnecessary variables and the functions from the memory.
Now coming to the last parts of the, last part of the presentation, whatever we discussed, how this is helping us to write more optimized JavaScript, because it is not at all, all theoretical.
So how, Can we improve our code?
First of all, we have to declare object properties in a constructor.
So if you, have a look at this example, you have a point class which has a constructor with, values being assigned to x and y.
Now, a first hidden class is created when an, object is made for the point class and, the another hidden class is not created if it is, a P2 object is created with the same class again, because it is of the same type as we discussed in the hidden classes.
But if you access the P1 object and add a new property z there with the value 3, so another hidden class is created.
So you need to declare object properties in the constructor only because otherwise the more hidden classes will be created and the object, your V8 engine will have to de optimize again and optimize again.
So this will cost more time to access the object properties further in the code.
Second is quite important, which is fixed function argument types.
So being a dynamically typed language, you need not mention the types in the, your, arguments, but, if you see through it, you can pass the numbers, strings, booleans in this type of function.
So for the first thing, it is, called monomorphic.
So one hidden class is created for this.
If you go with the string part, it becomes polymorphic.
And as soon as you cross four types of shapes for the, for that particular hidden class, it is considered megamorphic and, the engine, permanently avoids optimization for that, the de optimization and optimization process.
So anytime after this, your add function is being called, it is always, taking the de optimized byte code and that, extra access time to compile it through the optimizing compiler to the machine code is being required, which basically hinders your performance, making it slow.
Lastly, there are two more things to take care of.
First is the for-in loop, should be, used for object iteration.
So you could use the keys method, which is available on the object, or you could have a simple iteration.
But, the Google team had done micro benchmarking for the object iteration, and it is around four to five times faster with the for-in loop when you are looping through the object properties, rather than the other ways.
So it is always preferred to use this.
And lastly, the fourth point is to keep object property ordering constant.
So for example, you have a function where you can, add to, mention two values in the arguments for an object you initialize with the one, and then later access the object and add the another property.
While, in the other case, if you mention the, second property first in the argument and then later add on to the, object access later on, so these are considered as two different things because in the first one, the A, A property is mentioned earlier rather than the B one, while in the second one, B property is mentioned first.
And A is being, initialized by accessing the object.
So these are two different orderings and the different classes are being created again.
And which hinders the, your performance because you have to go again through the optimizing complier.
So I guess that is it for what you need to take care of to write optimisable JavaScript at the developer level.
So yeah, thank you very much.
These are my socials and obviously I am here for the today and tomorrow as well to discuss anything.
Thank you.
I guess we can take questions now.
Do you write JavaScript but are unsure of how it is executed under the hood? Are you interested in knowing more amazing stuff about the V8 JavaScript engine? Attend this talk to get an in-depth overview of the JavaScript engine and learn how this knowledge can help you as a developer to write more optimized JavaScript code. You will learn how exactly your high-level code is converted to bytecode and then to the optimized machine code with the magic of the V8 engine.