Intuitive APIs and Developer Education
(upbeat music) (audience applauds) thank you for that kind intro.
Hi everyone, I'm Bear.
And I like to generally start my talks by getting a sense of who I'm speaking to in the audience. So if you wouldn't mind humouring me on a few questions, I would love to know how many of you are software engineers in the room? Okay, basically everybody, great.
And how many of you are building APIs that other people use, whether it's people inside your company or a public API? Okay, quite a lot of you.
How many of you have the mixed luxury of designing that API system from scratch? Wow, that's quite a lot! And how many of you are working with existing code systems that you're adding to? A similar amount, I think everyone's raising their hands for everything, probably.
But that's accurate, 'cause it's kind of a false question. Whenever you're building a new API system, you're never truly doing something from scratch, because there are standards that have come before, there are expectations that people have when they're going to be using your API that you want to adhere to usually so that you get an intuitive feel for your API. And intuitive is the right word here, because what we're looking for is not just something that generally makes sense.
When we say intuitive, what we're looking for is an API that people can guess at without having to read your documentation.
Like if I know your general object model, I should be able to figure out what different methods are going to look like so I can kind of feel my way around without having to read or consider every last thing. And so that has benefits.
We are all invested in designing APIs that make sense. It's a really common engineering interview question, is talking people through how you would design a new API. Because there are sort of general agreements about what makes sense and what doesn't.
That's why it's a fair interview question.
And ultimately, it's because we want people to use the things we build.
So there are benefits to building things that follow existing patterns, but there are times when you come up against a new set of design challenges or a new set of functionality that makes you want to break from convention because your API is doing something new or unusual that makes it so that the old ways that other people know about and are conversant with break or just don't quite work right or it feels forced. And so what I'm going to be talking about today is a few case studies, some of which I worked on personally and some things that I just observed as an API user, of times when people have broken from convention and had to make the decision about whether or not you try and force an old design pattern on something that is new and unusual or whether you decide to say, "You know what, "we're going to do the thing that makes sense to us, "and we're just going to try and educate people "along the way so we can bring a community with us." It's harder than it sounds.
And so some of the things that I'm going to be talking about today are how you think about making that choice. So, hello, my name's Bear (chuckles).
I currently work at Slack.
I lead our Developer Relations team.
And our team is responsible for writing all the API documentation for Slack. We build our STKs and developer tools that kind of smooth the path for people getting started on our API.
And as Lachlan said, before that I did the same thing at Twitter and at Facebook and also on a product that Facebook bought called Parse. We're really invested in getting people using our APIs. And so you may be wondering, well what exactly is Developer Relations anyway? The whole point of having a Developer Relations team is to teach people how to use the products that you're building and smooth the way so that they can get started faster and that they have an easier understanding of the scope of what they can build, best practises, and get any help along the way. So the net result of being in Developer Relations is that, from having taught a lot of people how to use APIs and using a lot of other APIs ourselves in the process, we develop pretty strong opinions about API design because we see all of the ways that people struggle and fail to use the things that we build as well as all of the happy path success stories where people get started and are just fine. So we've spent a lot of time experimenting with different methods of teaching people how to use things. Is a quick start that sort of works automatically and then you learn the complexity later the best way to go? Do you put some of the important complexity up front so that people have a good mental working model of how the whole system exists and then kind of get them into the practical steps later? I don't have one hard and fast solution for all of those things, but these are the types of problems that we deal with all the time.
And then because we're spending all of this time with our customers and our developers, we spend a lot of time in the room with product teams and engineering teams talking about, not just what is best-case design for using an API, but how people are actually using it and struggling with it in the field so that we can make better design decisions to smooth the path for them.
So along the way it's a really important skill in Developer Relations to be able to talk about abstract concepts in a way that makes sense to other engineers. And this is something that is a lot harder than it sounds. For a lot of new Developer Relations folks I ask them an interview question which is what is recursion? How many of you are thinking that you have like a really good answer to that right now? Yeah, it's hard.
It's hard, and it's interesting to see what path people take when they say, "Okay, recursion, am I going to talk first "about the concept of how it works? "Am I gonna jump straight into an application "like if you were trying to do a factorial? "Here's a way that you could use it." And it's interesting to see people's different mental models around it. It's a bit of an aside, but this is the type of stuff that we spend time steeped in every single day. So the overall message that I have, before we dive into some of the case studies of how this played out for different people, is the way that you can best make a decision about whether you should conform to something existing or break with tradition is to base this on who you're trying to get to use your API. What context do they have about building and also about your system? Because that matters too.
What incentives do they have? Are you trying to proactively get them to build on something that you've built? Or do you know that you're solving a pain pint for them? Is there some sort of financial incentive that they have to learn the system? And then what bothers them about what already exists? What would actually be more painful to build against? And then you can decide from there.
So I'm gonna take us all the way back to 1999, 20 years ago today when we were at the cusp of a new system for the web for APIs called REST.
And I want to give a huge shout-out to the team over at ReadMe.io, who wrote a wonderful article on how all this developed in the context of existing APIs like SOAP, and different standards that weren't really standards. The problem that people had with APIs at the time was that there wasn't much consistency.
Some of these APIs were pretty fragile and they weren't really built for the web in the way that we think about now, where REST APIs are stateless, they have a uniform interface, they are built on the clients server model, and they're cacheable.
These are all properties of REST APIs that are pretty critical to their functioning and also fairly critical to them being suited for the web as it was.
So Roy Fielding had a dissertation where he wrote about what REST actually is.
And I'm going to give you a second to read this. But the idea is that you have a network of webpages, a virtual state machine where the user progresses through the application by selecting links, which are state transitions, resulting in the next page representing the next state of the application being transferred to the user and rendered for their use. Now, how many of you read this and are like, "I know exactly what he's talking about?" And that's exactly the problem, a lot of this was couched in the language of computer scientists.
This was about state machines, this was about state transitions and how you can think about this abstract notion of information exchange across the web.
Even in the previous slide where we're talking about things being stateless and cacheable, for many of us who've been working in the web for a long time, this is intuitive language by now, but for somebody who's a beginner, this is actually a really high wall to breach to figure out what on Earth this means, practically speaking.
And so, in 1999, nobody was using REST.
And then over the next year or two a couple of companies adopted it for their APIs. One of the first was Salesforce, and they were quietly doing it in kind of a closed programme so they didn't get a lot of broad public education around it.
And the next was eBay.
And so, eBay, when they released their API kit, they had the work to do of both teaching people about eBay's API, but also about REST.
So if you look at this early documentation, it tells you, very basically, what you can get inside there. And they ground it in information like saying that you can get item numbers, item descriptions, prices, and they give you information about the response format and some of the very, very basic notions of what an API is and does.
And so this had a few effects.
The first thing is that they made REST more concrete, because it's really hard to read that long chunk of text from Fielding's paper and really understand what it means. But when you say, instead, you wanna build a store on eBay and you can make a request to eBay that says, "Get item, with some ID, "and we'll return you information about that item." That makes pretty good, clear sense.
And so without getting too much into the mechanics of what REST is and does, they just told you, "You can fetch information about an item from us." The next thing they did that was really critical was that they provided sample code, because it's all very well to say, "Yeah, you just make this call." But if people don't even know how to approach that, if this is the first time they've seen REST, it is really, really important for them to have a practical working model of how they can do that. And then the next thing, and I can't overstate the importance of this, is that people had an incentive to learn.
And that was that there was money to be made in eBay. So people will jump over conceptual walls and hurdles if they know that there is a reason to do it. And so it shouldn't be surprising that the next big adopter of REST was Amazon. And so, as those gained popularity, come like 2004, 2005, people were pretty familiar with the model because there was a little bit of a gold rush. If you went over to eBay, if you went over to Amazon, you could use their APIs and you could build a business. So that was worth getting through the process. Fast-forwarding a little bit to 2006, we've got a new model, still REST, but a new business model in Flickr.
So, for those of you who were not web citizens in 2006, Flickr is a photo sharing site.
And one of the things that they allowed other companies to do was pull user generated content from Flickr into their applications using their API.
And so this introduced a few interesting things, the number one thing being, if you were eBay, you owned all the data and people could pull it directly from you.
In the case of Flickr, who owned the photos? The people who uploaded them.
So you had to have this exchange between the person who wants the photos, the person who actually owns the photos, and Flickr as this middleman.
And so they had an interesting set of educational challenges themselves.
So you can see in this documentation from 2006 that they're covering a lot of the basics still, about what an API is and does.
It says, the Flickr API consists of a set of callable methods and some API endpoints. And you can imagine, if you're writing documentation about an API in 2019, you probably can leave that implicit, like your API has some methods and it has some endpoints. And so they're teaching people the basics here, because that's where people were in 2006.
They needed to be told, "You need an API key "and we're going to give that to you.
"You need to have some way of accessing our information "and that is going to be through," the next slide, when they talk about the authentication API. And this was the sticker for a lot of things inside Flickr. And we're going to go back to this a little bit later when we talk about the development of OAuth. But this was an important thing in what because Web 2.0, is the notion that there's all of this user-generated content that you can both tap into and contribute to that could help you build your business.
So even in this area, there's (laughs), there's a note at the bottom saying, we've got some suggestions of how you can handle this. But at the end you say, if in doubt check them all out. Which is kind of a big ask for developers, it's like work through it, see what works.
Let us know, we would appreciate that.
And so what really made the difference for Flickr and adoption is having developer tooling. Now, Flickr didn't, the company that built Flickr, did not actually build all of these STKs.
There was a huge ground-swell of community support building STKs in all of these languages that you see listed on the left.
And that is something that is hugely important for two reasons.
One, STKs do a lot of heavy lifting for you, for reducing the complexity of what it is that you're building and lowering the barrier to adoption. The other thing is that taking on this developer-friendly attitude where you enable people to help each other helped Flickr do even better.
Because they were relying on this community, they were giving them props by listing them up here and they were able to reach many more people. Because, you know, there was an STK for Perl, (laughs) you could reach everybody with all these, and real basic.
So what you can see from Flickr's education model is that they still were at a place where you needed to explain high level, what was going on at all, and then it added the wrinkle of who's data are we talking about here? And those community STKs were pretty critical in making sure that people didn't have to worry themselves too much about how the mechanics of authentication worked. So fast-forward a few years to 2010, and we have an interesting new entrant in the market, the Facebook.com, as it was called when I first joined. And with the Facebook.com, there was an interesting thing about programmatic access to the data that they had. This is what you would get if you were looking for information about me, Bear. And this is also information that you would get in 2012, because now it's substantially more complicated with user IDs and everything.
But if you wanted to know about who I was you would get just a JSON Blob back with my name, an ID, maybe a few other things about me like my birthday or my relationships status. And that's interesting, I am an object in the Facebook Graph.
But, so here's me and my friend, Elizabeth. She is also an object in the Facebook Graph. And between us, there is a connection, we are friends, that is a two-way connection, great.
But what else about me and Elizabeth? We also watched the same movie and we also were tagged in a photo together. And I even poked her (laughs).
That's a one-way connection.
And so all of this was interesting because the connections were actually as meaningful as the objects themselves.
And that is a radical departure from what REST is really designed to accommodate. Because so much of the data that was valuable inside Facebook was not necessarily about a photo, for example.
What you cared about was who's photo, who's in it, who's liked it, what relationship do all of these objects have to one another. Because that is the important data.
And so REST, as a model, not necessarily the best to capture that and to access that data.
And so folks inside Facebook were like, "Okay, how do we do this in a more efficient way?" For any of you who did formal computer science things, you can see that this kind of suggests a Graph, because there are bidirectional and unidirectional connections between nodes. But again, that gets us into the early Roy Fielding problem of we're couching this a language of computer science. And so we still did.
Facebook called their new protocol the Open Graph. And the idea with the Open Graph was that we should be able to let developers represent their apps and their objects inside that broader social Graph that was created by Facebook.
And this seemed, at the time, like a fantastic opportunity. Imagine if the web, all of it, were semantically connected in ways where you could explore not just what existed, but how things related to each other.
It's a really compelling idea.
And so it took good hold and people's imagination. But again, if you look at the Open Graph protocol, the way it's described is that any web page can become a rich object in the social Graph. What does that mean? I don't know.
For instance, this is used on Facebook to allow any webpage to have the same functionality as any other object on Facebook.
Now, if you've spent a lot of time on the site you can probably infer what that means.
But maybe you can't.
And so I was on the team in 2011, 2012, where we were thinking about how do we get developers to use the Open Graph and contribute to data inside the Graph.
So on our developer site, we're like, "All right, we should frontline this, we should tell people that this is very exciting." So we said, "Hack the Graph." Which was the big language then, it was like everyone was a hacker and we wanted to build things and move quickly. So Hack the Graph, and then what happens when you click Hack the Graph? This is the onboarding page to help you figure out how you would define actions and objects inside Facebook. So you click, yeah, Hack the Graph, I'm super excited, let's go! And then you come to this page.
And it's probably too small for a lot of you to read, so I'll tell you, at the top it says what are action types? Action types are the actions that people can perform in your app, straightforward. Define how your app activity is presented in stories that appear in the News Feed, Ticker, and Timelines. Remember Ticker? From this page, you can set up what your actions will be called and preview how they'll be displayed.
And so in this page, you name a verb and then you have to define how that verb gets conjugated in different scenarios, like what happens if it's plural, what happened if it's in the past, and so on. And then you can click continue and move on. And then from there, you're asked to create an Object Type. And the Object Type could have anything you want, you need to define what a plural is, and you continue on to create aggregations. Now, the tricky thing with this was that we kind of assumed that because people were familiar, broadly, with object-oriented programming, the notion of defining an object would be pretty straightforward.
But it turns out, it really wasn't.
And a lot of developers put in either branded language or, you know, stories that will enable you to foo a baz. And you're like, "What does this mean?" You're getting all of this junk information in because people were really confused about creating object type and structure.
So we had kind of over-engineered this explanation of what it was that they were being required to do in order to contribute data back to the Graph. The thing that further complicated all of this is that we required that there be a live webpage that we could scrape that had object information about any object you wanted to put inside the Graph. This changed around 2014, 2015 when Facebook started hosting those objects. But the idea was that you had to have a webpage for every single object that you wanted to put in. So we put developers in this sort of weird position where they were like, "Okay, so the object exists in my app, "but it also needs to be a webpage, "and I also need to mark it up like this." It was incredibly confusing for a lot of people. And so they didn't have an easy time getting through it. And what happened instead was the place that really succeeded was in the markup language that people were using on webpages, and particularly webpages from media, webpages for news articles, and songs.
Because what people really connected with was, not necessarily the abstract notion of the Graph, but just the really straightforward markup. This is a news article, and so I'm going to add a tag that describes the URL, the title of this content, the type of content it is, in this case it's an article, and what the image URLs are and so on.
And so publishers were like, "Okay, well, this is a really straightforward mental model, "and also I easily get the benefits of being represented "in some of the unfurls and the story types on Facebook "that give me basically everything I want "out of this format." So the thing with Open Graph was that we had this grand vision about how it would play out. And the places it was sticky were in music, in movies, articles, and books.
And so that's where you often see a lot of things represented today still.
You no longer have the ability, as far as I know, to create arbitrary objects on the Open Graph. It kind of failed as an experiment.
But, big caveat, it did pave the way for GraphQL. And I know Ben is gonna tank a little bit about GraphQL in the next talk, stick around. Because what people did slowly start to get, over the course of several years of having the Graph API, is this notion of having multiple objects where the data is not just in the object, it's in the connection type.
And it's a really useful model, for many other services. But the thing that made it concrete, that helped people understand was using Facebook. I could talk to you, well, actually, I probably shouldn't talk to you about Graph theory (laughs).
It was like a required class in CS undergrad. But when you talk about the practical application, of like, well, you've got friends.
And there are photos that you might be tagged in and how do these all relate to each other it makes it much more concrete so that this, instead of being something that's unparseable gobbledygook, helps you understand, oh, okay, so I'm looking for my albums, I only want about five of them and there are albums with names, I only want to see two of the photos and what I care about is the picture and any tags that were on the photo.
Which would have been completely unparseable in a REST API. So the conclusion from there is that we had a lot of hurdles early on, teaching the developer community.
And we didn't do a great job.
And, ultimately, that ended up being okay.
Because now people get GraphQL.
It hasn't stopped people using the Facebook API, but I think there is an important moment to be honest with ourselves, as developer educators, that the reason that they persevered on the API had nothing to do with the quality of our education. It wasn't because we made it so, so easy for people to use. It's because tapping into the API gave people access to really useful data and gave them an opportunity to talk up their software.
So when you're thinking about context that people had, only the context of using Facebook, the pain points that they had, they were our pain points. Developers didn't really think about how painful it would have been to consume this type of data through a REST interface. But, ultimately, they had the incentives and that's what made them persevere.
So when you're thinking about doing this type of education, don't assume that developers on your platform have any formal computer science education. I think that was one of the early downfalls that we had and that I also saw with early days of Android. I've given another talk where I do a Wayback Machine look at Google's Getting Started for Android, circa 2010. And it talks to you about like how the whole system has set up their processing power, so like how threads work inside Android.
And so that's, if you think about Getting Started as a, let's truly start you at the beginning, let's begin at the beginning, instead of something more task oriented like let's get you to success quickly.
So as more and more people are becoming developers who are not going through formal CS programmes that might be grounded in the mathy, algorithmy version of computer science, don't take for granted that people know about some of these mathy concepts. Many of them will learn, but it's going to be a big barrier to adoption as you try and teach them.
The things that were really helpful were making it concrete. So those meta tags on news articles, as we saw before, the Get Item in eBay's API, that is what people can really understand and hang their hats on, even better if they can see it.
And so those applied uses made it much more easy for people later on, like 10 years later on, to understand, oh, okay, this is why GraphQL is such a useful concept, or setup design.
So I said, when I was talking about Flickr earlier, that we would come back to it.
So I'm gonna come back to it now and talk a little bit about this authentication problem. We're gonna put GraphQL to the side for now and think about the education issues that we have when getting developers to use a brand new model of data access.
So in the Flickr services, they talked about having multiple different ways of you being able to design the sign-in process. And this worked for Flickr, people were managing to access photos, again because they had that big incentive. The big incentive was the business of Web 2.0. You can get in on this gold rush by making businesses off of photos.
But as more and more user-based services proliferate where there were all of this user-generated content and there were companies that wanted access to that content that were not their service provider, it became clear that we needed a useful standard for how we would grant access to that third party. And so around 2010, 11ish, OAuth became the new standard that a few companies were trying to adopt.
It came out of Facebook and Twitter and a few other companies in a consortium.
And the idea behind OAuth was that you wanted to give permission to a third party to access your data without literally sharing your credentials. There shouldn't be a way that you had to give your email and password login, there should be a representation of the access that a third party had to your data.
So how many of you have had to read the OAuth spec? Oh, I'm so sorry.
That's a surprising number of you.
That's like (laughs) a quarter of the room. So, again, we're gonna go back to this, like reading the dense text and being like, what does this mean? In order for the client to access resources, it first has to obtain permission from the resource owner. Straightforward.
This permission is expressed in the form of a token and matching shared-secret.
The purpose of the token is to make it unnecessary for the resource owner to share its credentials with the client.
Unlike the resource owner credentials, tokens can be issued with a restricted scope and a limited lifetime and revoked independently. And that was the really key thing for OAuth, is that if you give people your credentials, it wasn't just a security issue that now they can login as you, they had unlimited access to your account.
There was no way to represent restricted access and only to specific things so you knew exactly what you were allowing people to do on your behalf. And so that's what OAuth tried to fix.
And whether you find this unintelligible or actually pretty straightforward, it's a major problem that multiple services had to deal with.
So, for example, here's Twitter.
You had to decide whether an application can connect to your account.
And this was not just a developer education issue, this was a really important user education issue. Because when you pop up this screen, do people really understand what it means to give a third party access to your account? I think we've seen, in the last five years particularly, that no, they don't.
And so in designing the system and in designing the things like the user prompts, you have a certain responsibility, both to your developers and to your users to make sure it's clear what's happening in this transaction right now.
Because all you see is Deny and the Allow button, that is nice and blue and says, "You should allow this, "that's gonna help you move forward." And you have to figure out what that means for your end user.
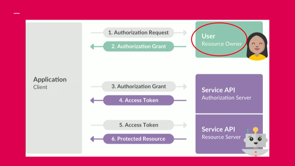
So OAuth itself is kind of a pain (laughs). It involves multiple different token exchanges, authorization requests, first to your user. When they grant it, it goes back to the core application, the client.
Then they send an authorization grant information back to the service API, which sends an access token back. And then once you've got that access token, then you can use it to sign requests that you have for specific resources.
And it's up to the service API to decide whether or not they should give you back that resource based on what's in the token.
And so this is a very simplified model of what this actually looks like.
There are like, I wanna say 10ish steps, and they rely on tight timing between each of the interactions.
And it is a beast to implement.
So this is why people use STKs (laughs).
Really, this is probably the biggest reason that anyone has for using the Slack STKs, for using Facebook's STKs for sure, Twitter, absolutely. Because that OAuth process is quite complicated. But it's so foundational to success on the platform, that you don't have an option.
You can't not do it.
So tooling is one of the things that is most important for getting people to success on the platform. So that made good sense for a lot of different services, Twitter for sure, Facebook for sure, Flickr for sure, anything where the resource owner is the user. So, working back to that green slide, it didn't say user.
It said resource owner.
And that's something that is critical to distinguish when you are working in an enterprise case. OAuth works beautifully for user access grants to their own data.
But it sort of breaks down when you think about how it would work on behalf of a company.
So Slack works with company data.
Our users, our customers are all members of a company. And when you think about how you interact with your company's data, you generate some of it, you generate IP every time you open up your code editor or write a doc, you have access to certain things that are being shared with you, either by your colleagues or by management, by HR.
And your company owns a lot of things that you may not. And so you personally have access to a subset of resources that the company has access to. And that's right and proper and good.
But now if you're thinking about what it should look like for an application to live inside a system like Slack where the end user isn't just you, it's everybody in your company, potentially, this starts to break down a little bit.
Because if I'm an admin and I am working at ACME Corp and ACME Corp wants everyone to just use one file provider so you don't have docs in a million different places that are really hard to find, hard to lock down, I don't have that level of control if you're asking all of my users for individual user auth grants.
I want to just say, I as the admin grant access to just this one file provider and it should be used for everybody and I don't want the 10,000 people that work at ACME Corp to have to individually say, yes, I too opt into this, yes, I too opt into this, yes, I too opt into this. Because, one, that's too complicated, and, two, it makes it really hard for people to actually go to that one file provider because it isn't just provisioned for them. So these were the types of problems that we're facing and are still facing at Slack when we think about applying the OAuth model to the enterprise. So in 2017, we started up a project that we called Workspace Apps.
And the idea was to kind of make a waffle, a little like bend over backwards to suit this case where there should be a single representation, like a single token, of an app's access to an entire workspace.
Now for those of you who don't use Slack, the basic model is that everybody belongs to a workspace. A workspace is a collection of people and also channels, and channels are where a conversation actually happens. So you're talking about a collection of a collection. So it's, there are layers here of needing to understand Slack's model before you can understand Workspace Apps.
And the reason this is important is because this is a screenshot of the admin experience for installing apps in a Slack workspace, and have to make all of these decisions about all of these requests that they're getting. And this is a pretty tenable thing to do if you only have 10 requests that are coming in from your company.
But imagine that you, ACME Corp has grown dramatically, and instead of being 10,000 people, it's now 100,000 people. This UI breaks down pretty fast, and also, it is a huge pain in the ass to have to administer that and think through all of the possible scenarios. So thinking about the admin, thinking about control and who should have what in mind, we built the Workspace Token.
And, again, this is taken directly from our education materials now, but that summarised what we had at the time. And if you read through this, I'm not gonna read aloud to you again, don't worry, there's a lot in here that you need to have context on in order to be successful.
We talk a lot about workspaces and what a workspace-level installation is. We talk about public channels, private channels, direct messages, and other conversation types. What does that mean? If you've never used Slack, if you're not really into our whole object model, it's very opaque.
And the trouble, too, is that we introduced a handful of really compelling features in this.
We added progressive permissions model, which was interesting because progressive permissions in the user case is super useful.
If you think about what happens even on the OS level on your mobile phone, you can start using an app and if it immediately asked you for camera access, you may be like, "Slow your roll, app, I don't know you, "I don't know what your about, "I don't know what your gonna do "with my data, with my camera." But if you've used it for a little while, then they jump in after you've shown intent to use the camera, and say, "Hey, would you like to enable the camera?" And then you say, "Yes, thank you." And that's really useful.
But in the case of an enterprise, your admin doesn't want you sneakily adding extra permissions after they've only allowed a certain set of permissions on the workspace. So this was something that, for the user model, made perfect sense and being back-ported to the enterprise kinda didn't.
Things like token rotation and deep linking into Slack, these were all good benefits.
But at the end of the day, managing data access in the enterprise is an entire line of business. IdP providers, that's a redundant, it's like ATM machine, but yeah, IdPs, people who use, sophisticated user groups inside the enterprise spend a lot of time thinking about this, and it is a beast to manage.
So thinking that we could just sort of easily hop over that by mucking with the way that we were doing OAuth was a little naive, and also presented some substantial hurdles to our end users.
So what we learned from this was that, early on when we were just using kind of Vanilla OAuth and granting user access in a workspace, it made it easier for developers to use our stuff. Because they knew OAuth.
They have had to use it for dozens of services. And so it was pretty straightforward, especially if they were using our STKs.
But the problem that people ran into was that there was a lot of Slack-specific, I don't want to say cruft, but extra overhead that you had to learn that was an abstraction.
Like, what is a workspace, what is an org, what is a resource, what is channel membership and how do I mentally model this? And, in the past, the way that we had skirted around this was with the concept of a bot.
And so, hands up if you've used a chat bot ever? Yeah, so the thing that's easy about chat bots is that they're users, they're users that are essentially your front-end for a service.
But when you think about what that user has access to, it's like well, am I in a conversation with them? Yes, then they probably have access to the data about our conversation.
Are they not in the conversation? I would assume they don't.
And because people have that existing mental model of how that should behave, what things have access to, it was a lot easier for them to lean on.
So even though we rewrote our documentation, supported this with tooling, there weren't really incentives for developers to totally rewrite their apps because we were like, "You know what, this is kind of broken "and we think it would be really great "if we just kind of re-architected the whole system." That's terrible, that's a terrible developer experience. And we listened to our community when they told us that. So we actually killed this project.
We walked it back in October of 2018.
And the commitment that we made instead was to alter our existing off-protocol to make it a little bit friendlier to all of the use cases that we needed to solve for the enterprise without people needing to completely rework their understanding of access inside our system. So even if now you're kind of tuning out and being like, "Okay, seems interesting," it's not, it's not for a lot of people.
And that's why it was really hard to get people to actually adopt this.
So the takeaway from there is that when you're deciding whether or not you're gonna completely bust out, the context that people have matters.
People had some amount of context, but there was just so much to learn in order to make Workspace Apps work that we ultimately decided that it wasn't the right way to go.
So it's important to know some of the details of the failures in these couple of cases, because it's very easy to assume that like, oh, if you write great documentation, if you build up a community of people who support this API, eventually people will get it.
And that's sometimes true, but you hear, or rather you remember, a lot of the success stories and don't remember a lot of the failures that never made it off the ground because it required too much of people to re-conceptualize what they were working with. So thinking deeply about how much people know and what you would have to teach them in order to get your new model to work is super important. So whenever you're thinking about making this plan, if you have the luxury of architecting a new API from scratch, and that doesn't necessarily need to be like company, or back to API, it can be a new language, a new framework, what context do people already have, what incentives do they have to learn, are you fighting for market share or are people coming to you because they have a pain point? And make your decision from there.
Who are my developers? This is something that is especially important when you're getting off the ground.
You might wanna say, "Well, it's everybody. "Everybody should be using this." And that's never true.
Start with people who you can easily define as a core group. And then from that definition, ask yourself what do they already know and what do they expect? The key thing is when might they give up? As developers, we often don't dog food our own platforms enough and go through some of the pain points of starting from scratch again, especially if you've been working on something for years. Going through and finding out where people might give up. And especially if you can gather data on that. Where in the funnel are people just dropping off because it's too hard to understand, and how can you convince them to keep trying or make it less hard when they do hit those pain points? And so that, in a nutshell, is the crux of what I'm trying to solve for my developer communities. And that is the job of Developer Relations. And it's also the job of anybody who is designing these systems.
We're all in this together and we can move the web forward. This is what this whole conference is about. But we have to bring one another along with us. So when that comes to things like writing articles or just answer a question when somebody asks you something that you understand and they don't, we're all in this together.
Take the time to educate your peers.
And, thank you.
(audience applauds) (upbeat music)
API standards, from SOAP to REST to GraphQL, have evolved to meet the needs of API providers and developer consumers. They make APIs “intuitive” by making them predictable. When product designs bump up against the constraints of standards, you can choose to force a fit or break from convention and invest in educating developers about your choices.
Through case studies (incl. Facebook’s Open Graph, Slack’s workspace apps project) we’ll examine the tradeoffs, consequences, and some learnings about how to get your developer community to come along with you.