Incident Management–Talk the Talk, Walk the Walk

Introduction to Incident Management
Hila Fish, a senior DevOps engineer at Wix, begins her talk by introducing the topic of incident management. She emphasizes the importance of not just talking but also walking the walk when it comes to effectively managing incidents.
Incident Management Mindset
Fish discusses the necessary mindset for managing incidents, covering the structured process of incident management and the essential characteristics required to be a successful incident manager.
Reality of System Failures
She delves into the inevitability of system failures, stressing that everything fails at some point. Fish emphasizes preparation and the right approach to handling these inevitable failures.
Structured Process for Managing Incidents
Fish presents a structured process for managing incidents, detailing the stages from identification and categorization to notification, escalation, and eventual resolution.
Resolving and Recovering from Incidents
The talk progresses to strategies for resolving and recovering from incidents, focusing on choosing the most effective remediation steps and ensuring system stability.
War Room Conduct and Incident Management
Fish discusses the concept of a 'war room' during critical incidents and the importance of having a calm and collected incident manager to coordinate efforts.
Necessary Qualities for Incident Management
She outlines the key qualities needed for effective incident management, including the ability to think on one's feet, operate under pressure, and maintain a humble approach.
Proactive Approaches in Incident Management
Fish concludes her presentation by emphasizing the importance of a proactive approach to incident management, including preparation, knowledge sharing, and continuous learning.
Final Thoughts and Q&A
In her closing remarks, Hila Fish summarizes the key points of her talk, reiterating the importance of a structured process and proactive mindset in incident management. She then opens the floor for questions and further discussion.
Okay.
So thank you very much for joining me in this conference in Australia, for me it's exciting.
So yeah, so this talk will be about incident management and basically how to talk, not only talk to talk, but also walk the walk when it comes to incident management.
So when I was in high school, the common belief was And if you actively listen in class, you'll have 50 percent of the exam prep already in your pocket.
And I want to show you how I adapted this belief to an actual approach that you can take in your day to day and after an incident took place that will allow you to come prepared to incidents that will pass your way.
And in addition, I'm going to also cover a structural process of any incident that you can follow and that way you'll know what to do and also characteristics that you should have and how to perfect them in order to be a better incident manager.
So very quickly about myself because I don't have much time.
I'm Hila Fish.
I'm a senior DevOps engineer and I work for Wix.
I have 15 years of experience in the tech industry, which means that I encountered a lot of production incidents in various teams, small, big ones.
So that's why I'm qualified to talk to you about it here.
The agenda for today, as I mentioned, first of all, we will cover the mindset needed for managing incidents, and then the incident flow, the structured process, on call traits, and the proactive approach.
First of all, just to have a basic guideline here, what is incident management?
Basically, it is a set of procedures and actions taken to resolve critical incidents.
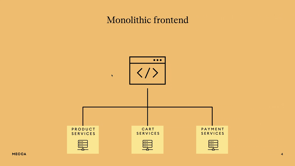
So it is an end to end process that defines how incidents are detected and communicated, who is responsible to handle them, what tools are used for investigation and response, and what steps are taken for resolution.
So the thing here about incident management is that you, we should really reframe our perspectives from, putting out fires, Perspective to having a structured process.
And why is that?
Because we have pages and not all pages we get are becoming an incident.
When is it an incident?
Once we have loss in revenues, customers data and more.
And without incident management process, a defined one, it could potentially lead to losing valuable data.
Downtime could potentially lead to reduced productivity and revenues.
And also the business itself could be held liable for breach of service level agreements, and we don't want that.
We have agreements with our customers, and we need to honor that.
So that's why once we think about incidents and, hey, we need to figure things out and putting out fires, we need to leave that and have a structural process saying that something will happen and we are equipped to deal with that.
And that's basically what I mean when I cover and when I say business mindset.
So we have systems and we are all tech people.
But we don't need to only think about our systems and, and what they are all about, but we need to also cover the why.
Why we're doing things in a certain way.
How is this system related to the business impact and what it's aimed to achieve.
So that's why, having this mindset is very important, and business mindset, in general, is needed to grasp the overall impact and also to mitigate any damages.
Once we know the full extent of something, we know how can we mitigate those damages.
And that's why we should have a structured process to manage incidents.
Wait, something happened?
No, don't worry, something, nothing happened.
What I want to cover here is the fact that everything fails.
Okay?
All the time.
Who said it?
I am.
But, first of all, it's odd to, to quote myself, so now, I'm not gonna do it, but second of all, AWS CTO Werner Vogels have much more credit than me, so here you go, I quoted him.
Everything fails all the time.
The production systems that we have, third party systems that we buy from other vendors, even our monitoring systems that are meant and designed to, and monitor our production systems, they also fail.
Also us, as human beings, will fail.
We need to sleep, we crash, and then we need to restart ourselves by sleeping.
So everything fails all the time, and once we know that, yeah, incidents are mayhem by nature, but once we know that everything could fail, potentially, all the time, we are equipped to deal with it, and that's why we don't have this putting out fires mindset.
We know that.
Something happened, okay, I'm prepared for it, and I know that I need to deal with it properly.
So wait, structural process, how can it be?
Because incidents are mayhem, right?
How can it be a structural process?
So basically, there is a structural process, and I'm gonna cover it in a bit.
And basically, a structured process could lead to incident prevention, improved mean time to resolution, MTTR, cost reduction because downtime was reduced or eliminated entirely, and to preserve our business, customers, and reputation.
So basically, this is the structure that I'm talking about.
I took, I always follow this throughout my career, but then I found this, defined structure in OnPage, so that's why I quote it from here.
And we have these five pillars, and, in each pillar, I'm going to show you which questions you can ask yourself in order to progress to the next phase, and then have, a structured process.
The pillars are identify and categorize, notify and escalate, investigate and diagnose, resolve and recover, and also, once the incident gets closed, there are still things to be done also in that phase, and we'll cover each one.
But beforehand, there are two kind of people that I dealt with in my career.
The people that say that during an incident you can keep calm because I'm an engineer, so keep calm.
And the ones that say, I can't keep calm, I'm an engineer!
So these are the two types I encountered.
But what I'm gonna say here is that you can keep calm if you ask yourself these questions.
So first of all, in the pillar of identify and categorize, this question, do I understand the full extent of the problem and the business impact?
If so, awesome, you can dive right into the troubleshooting and debugging and to notify people.
And if not, you should gather more information.
And sometimes we have the alert, but we are not sure what is the business impact.
And we also always need to know what is the impact in order to understand if, which leads us to the next question, can this, alert that we found, wait and be handled in business hours or not?
If you're not sure, then ask.
Use the information that you have and escalate if needed.
And maybe you found that the alert is, classified as critical, but then it's something that is minor and can wait for business hours.
So also fix the alert, severity, because we don't want to face it again.
And also, update any runbooks accordingly.
And I want to I'm going to touch on the runbooks a bit later on.
Another question here that you should ask yourself.
Was I notified about this issue from the proper or expected channels?
A.
K.
A.
If I got alerted from PagerDuty or OpsGeni, that's great.
If I got alerted from a user complaint?
That's bad.
So if I know about this issue from the proper channels, that's great.
If not, you should add a note to self to fix it, create a Jira ticket or something like that, to have, make sure that next time something like this happens, you are alerted properly.
Because again, business mindset, we don't want to have a bad experience for our users, that they are the ones to let us know about an issue.
We need to know about it, up front.
The next pillar that I'm going to cover here is notify and escalate.
So once we understand the full extent of the problem and who should we, if we need to contact people or not, and if we need to, handle it right now or during business hours, now let's understand who should be notified about this incident.
So we have two paths here, during the incident and in general.
So during the incident, you should decide by incident importance.
So if the incident is critical, you should alert, support teams, customer success teams, because they need to communicate this to our, customers to know that there are issues and we're on top of them.
And in general, maybe there are internal teams that have flows that rely on our systems for their flows.
So if there are teams that you know about, you should alert these teams as well to say that, hey, this system is currently down or unstable.
So wait with your flows and just know that something is happening right now And, Escalation.
So first of all, it was notifiy, FYI, to know about something, but Escalation, also, divides into two, pillars for resolution, so maybe I check my side of things, everything looks good, but then I need to escalate to the dev teams because I'm a DevOps engineer, I deal with the infra, and then the dev teams deal with the application itself.
So maybe I need to, escalate to the dev teams for resolution and also for the so like resolution or F-Y-I.
F-Y-I for the support or customer teams and other teams to help me, fix this issue.
Next pillar, investigate and diagnose.
So what information is relevant towards the incident resolution?
Because I had, incidents where people just talked and talked and talked and didn't really get to something in progress towards resolution.
You know what I'm talking about.
So that's the fact.
And we always need to focus on what's important to this incident because that way we can focus and get towards the proper resolution.
And the fact is that focusing on the non relevant will steer you off and throw you off route and make you lose valuable time doing debugging.
And we don't want that.
We want to minimize downtime as much as possible.
And sometimes flow comprises of different parts, right?
So if, let's say you ask someone and then, you need help with database, don't tell them that you checked the entire chain.
They don't care about it.
Just say, hey, I have issue when application needs to communicate with a database.
I have this error.
Please help me.
And that way they are focused on what's the problem and that's it.
Cool, I did some debugging.
Awesome.
Now, did I find the root cause, and do I understand the root cause?
If so, then great.
If not, investigate some more and escalate if it takes long, because again, business mindset, we need to minimize downtime and not just, yeah, I'm on top of it, and I'm gonna touch a bit about this being humble later.
And also about the root cause, think about possible remediation steps that can be determined, and we can think about it only if we know and understand the root cause, and to expose any underlying issues, because who of us didn't have an alert at 4 in the morning where the service just stopped, and then, it's 4 in the morning, I'm just gonna start, and then that's it?
Sometimes it works, but sometimes it happens again, so just don't just start it again, take your time, investigate what's going on in order to understand why is the service getting stopped, in the first place.
Resolve and recovery.
Which possible remediation steps is, step is the best one to take?
So let's say, understand the root cause, there are possible things that I can do here.
What is the best solution to take, so the best solution is the fastest solution to eliminate downtime without compromising the system's health and stability.
So why fast?
Because first of all, we want to go back to sleep faster, right?
But also because, again, a business mindset, and I'm going to say it quite a lot of times because it's like a mantra that you should have, we want the service to be up and running.
So that's why it should be the fastest one.
So let's say you found a fastest one, but let's say, you decided to do a patch, which is okay, because if it's four in the morning, all the relevant parties decided that this is the way to go, that's okay, but during business hours, permanently fix the issue, because we don't want our system to be stable, and not just put a band aid on it.
And also, a preventively occurring issue is a priority, and why?
Because of?
Business mindset.
Why is that?
Since we don't want to waste resources for the business, not money, and not because downtime will happen again if we don't really fix it, and also resources.
Because if it happens all over again, someone needs to deal with it.
And dealing with it all the time is wasting resources for the company.
So that's why preventing recurring issues is a priority, and permanently fixing something is also a priority, because we want to make sure our systems are stable.
And last but not least, closure of the incident.
We have remediation steps, everything is good.
Now, do I need to notify anyone on the incident's resolution?
Because we need to be end to end communicators.
So if we notify people, like support teams, now we need to tell them, hey, the issue should be resolved by now, please communicate it to our users, and let's see if everything is okay or not.
Maybe they'll say, no, I still experienced some stuff, so we need to know about it.
So communicate to our support teams, communicate to other teams that rely on the systems, and basically have to be an end to end communicator.
Eh, check the alerts.
Were the alerts okay.
Or they need tweaking either severity or, there are a lot of times where the alerts are false positives.
So if something like that happened, fix it, is relevant instant run book in place.
And is it outdated or, and needs updated, eh, and needs updates.
So run books, if you don't know, is basically procedures that you write that can, something that can be automated, and that's why you need to have a written procedure and basically you do it when you have a complex thing to decide about that you need judgment.
So if you have, really, I have 10 minutes.
Oh my God.
Okay.
So runbooks, update them to help you, the future you and your team members.
If you detected stuff, that can be fixed, like log rotates that you saw that didn't work and stuff like that, prevent other incidents and create, Jira tickets for them.
And if you need postmortem, write down the notes as soon as possible to have an effective meeting.
And even if you don't need a postmortem, then share the knowledge, most only, in a round book or in a daily brief.
Everyone will benefit from it.
They will learn, learn from your line of thought.
They will learn from the, system flaws.
Then it's a win-win for everyone.
A little bit about war room conduct.
War room is when you have, more than four or five people that needs to handle something, and then it's very crucial to have an incident manager that will divide the work.
And why is that?
Because I had a, a very critical incident where it was on Zoom because it was during COVID, and then I just, they, again, they talked, and he pulled to this direction and pulled to this direction, and nothing really progressed after 10 minutes.
I was new at that company only a month in, and then I unmuted myself, and I'm like, okay, Can I just pitch in a bit?
And I took upon myself the role of Incident Manager, and then I started to divide the work.
I listened to him and said, okay, there's a proper way to start application, right?
And there's no runbook for that, right?
So please write a runbook for that, because once the incident gets resolved, and if you're not available, I want someone to be able to start the application properly.
So I started to divide the work properly, and then, only then, stuff started to get along and progress towards resolution.
So incident manager is very, important.
They need to be calm and collected by the work and not afraid to reduce people's, conduct because if there's too many people, too noisy.
So if someone finished to do something, okay, thank you, now go away.
Okay, we want it to be as less noisy as possible.
Very quickly, necessary qualities for incident management.
There are a lot of qualities, but I want to cover here the ones that I saw that are most Important and how to perfect them.
Think on your feet.
Impromptu action taker.
So sometimes you have an incident that is familiar to you and sometimes not.
So you need to think on your feet how to do it.
Participate in brainstorming sessions and basically have a can do approach.
If someone pitches you an idea, a lead, don't say, I don't think it's related.
Try it, okay?
If you have no other leads, try it.
Have a can do approach.
Operate under pressure.
I had an incident where I was also new at work, and then it was like 200 alerts immediately, and then I called the guy, and I was like, okay, I have this, I tried this, I tried that.
What to do?
And I looked at the screen when I said that, and then crickets, silence.
And I looked at him, and he was like, shocked.
He was I was totally shocked and then he said so many alerts, like a mantra, so many alerts, like that, and that, that's it.
I'm like, dude, snap out of it, snap out of it.
It was very, yeah, Yeah, pressure sometimes happens, but the thing is that in order to practice it, you need to collect information, relevant information, since stress is a symptom of being out of control.
And if you have relevant information, that will help you decrease stress levels, because when you know what to do, you are in control.
Collect information, then you'll be less out of control, and everything will be good.
Work methodical, faster incident resolution, if you work methodically.
How to do it with the incident management structure that I showed you before.
Humble.
Please be humble if you need help.
Don't, it's not your time to shine.
Okay?
You have plenty of times to showcase your abilities and you need to think about the business.
And if you say, no, I got this, and you have no leads and you waste time in debugging, it doesn't help you, it doesn't help your company, nothing.
So if you're humble, if you're stuck, please be humble.
Ask for help, it will showcase that you care about the company.
And make a habit out of it.
If you check the clock every time you are stuck on something, 10 minutes in, ask for help and then it will be a habit for you.
Sense of ownership and initiative.
So if I escalated the incident that I have to someone else, it doesn't mean that I'm finished, I'm off the hook.
I'm still on call.
I need to be on top of things and to make sure it is still being handled because I had times where I handed it to a DBA at 2Am.
And then 15 minutes in and again, crickets, nothing.
Are you on it?
Are you on it?
Did you go back to sleep?
I don't know.
We need to know what's going on.
If you escalated, please make sure the issue is still being handled throughout its incident life cycle.
Check status says ongoing.
No, please don't.
I don't, have that.
Okay, good communicator, we talked about it.
Communication guidelines can be set up, okay?
If you're not good communicator, that's okay.
We can set up a channels that I practice it at home.
I promise you it was 30 minutes.
Communication guidelines can be established to say, hey, you need to communicate this in this channel after 10 minutes you need to escalate to this, that, this can be established and then you know exactly how to communicate things in the incident.
And last but not least, you need to care.
You can't do anything that I showed here without caring, so if you don't care, please check yourself and in order to do that, get more involved and ask questions to find your motivation and only if you care, you'll be able to do anything.
We covered mindset, incident flow, and on call traits.
Very quickly, how to be proactive in your day to day and after an incident took place, to be, to come prepared for, for incidents.
And why is that?
Because, like the Fugee's song, Ready or Not, here they come.
PagerDuty, OpsGenie, VictorOps, you can't hide, okay?
So you better, come prepared.
And it sounds much better when I'm not speaking that quickly, but okay.
Okay.
After an incident took place, what can you do?
So on call shifts, handoffs, summaries that you can write in Slack to help your team members understand what's going on in the shift.
And that way it's good for audit purposes, but also for a team member's success, because if they know what happened last week, then they can, track things that are ongoing or in progress or reoccurring things.
So it's good for everyone.
Post mortem notes, as soon as possible, write them down, but also, I have something here, there.
Also, do a mental check.
Even if post mortem is not needed, do a mental check with yourself, retrospective, to see if something you can have done better.
New tasks.
If you detected anything that could help prevent the next incident and stabilize the environment, create JIRA tasks to cover that as well.
Modify loads.
Fix any false positives and don't wait for the next on call to do it because they will wait for the next on call to do it and they will wait for the next one and then it will never happen.
So please fix it yourself.
Runbooks, as we stated, needs to be updated and to have them even in place because not always there are runbooks in place, and to make sure you attach them to incidents that every incident you have a link to the relevant incident, relevant runbook, and that way, you know exactly what to look for.
You don't need to search the entire knowledge base.
And maybe there are candidates for self remediation that you can check in order to do setup, and then, things can be, fixed on its own.
And if you have an issue that you handled, share the knowledge more thoroughly than an on call shift handoff, because again, people can learn from your line of thought.
They can learn about system flows from this knowledge sharing.
And on your day to day, things that you can do in a regular day to day, not even when incidents happen.
So the on call shifts handoffs that I mentioned before, read them in an ongoing basis.
And why is that?
Because production happens all the time, not only when you are on call.
So this is your way to understand what's going on when things happen, and it's through these handoffs.
So read them in an ongoing basis.
It won't take very long.
It's just a summary, so it's very useful.
Escalation point of contact.
So if I know, who's responsible for system X from the dev side, I know exactly who to escalate in the middle of the night, and I don't need to wake my team leaders up to ask who's responsible for X, and then he'll get mad at me, and, it's not nice.
So if I know, I save debugging time, I save a lot of time, and this, this is awesome.
Understanding system architecture, so if I know weaker areas or vulnerabilities or sensitive or blast radius scopes, it will help me to identify what's prone to fail and have a go to fix that.
Learn application flows, so understanding system architecture is internal stuff in the system itself and application flows is between systems.
So we need to know both things because if we know the entire chain, we know exactly if an error occurs, you know where to check it in the chain.
And even if the error log is not really, helpful, then it can still know the flow of things, okay, I check this now, I check this and you have a flow to things and then the debugging will be much more methodical.
Team members tasks.
So again, it's very easy for me to focus only on my tasks, but production changes all the time, not only for my tasks, but also for my team members tasks.
So get involved, see what are the changes that they're doing, and see how their changes could potentially impact production, and that way you know exactly, if something happens, oh, I can link it to what they did, and that's great.
Deployments, changes in prod.
Tasks are general and deployment changes are direct changes in production.
So anything that could happen in production, understand the impact in order to link it to any incidents that could happen.
And then you have escalation point of contact.
You can, drill down and understand what was the change and then fix it yourself if you know it well enough so that's [not audible].
And last but not least, be a go to person.
If you build it, they will come.
So if you are a go to person, you will get push notifications to you.
People will come to you to consult the things, to tell you about things that they did, and then it will eliminate the need for you to go to fetch the updates by yourself, because people will come to you to do it.
After I talked very, quickly, I hope that it was okay.
In order to talk the talk and work the work, when it comes to incident management, have your qualities in check, make the process structured, and be proactive.
And that way you will come prepared to any incidents that will cross your way and prevent the next incident from happening.
And less incidents means Less downtime and means less downtimes mean, business success, which is eventually, your success.
Thank you very much.
Incident management can be challenging and throw you curveballs with unexpected issues, resulting in data loss, downtimes, and overall money & hours of sleep going to waste, BUT! There are practical things you could do to make it a smoother process and handle it better.
Remember when we were at school, and people said – “Actively listening in class guarantees 50% prep for the upcoming test”?
The same goes for being proactive at work in ways that will instantly prepare you to manage incidents better (at night or in general).
In this talk, I’ll cover the proactive ways you could take and incorporate into your day-to-day routine, in order to prepare you for a smoother and more efficient incident management process.
I will also show the best practices I’ve finalized over the years that helped me get a clear vision of how to manage production incidents in the quickest & efficient way possible.
Embracing the tips I’ll give you will guarantee you’ll not only talk the talk but also walk the walk when it comes to incident management.