Evolving code at scale

Introduction to Enterprise Code Evolution
Jake Lane opens his talk by addressing the challenges in evolving enterprise codebases, focusing on the need for strategic migration of commonly used code to newer technologies.
Approaches to Code Migration
He discusses various approaches to resolve issues in enterprise code, focusing on manual migrations and risk appetite when updating code for customers.
Legacy Code and Migration Necessity
Lane highlights the presence of outdated tools like JQuery and LeftPad in enterprise codebases and the urgency of migrating to more current solutions.
Challenges in Code Migration
He delves into the complexities of migrating code, particularly in the context of moving from one API to another and addressing legacy code issues.
Manual Migrations and Their Challenges
Lane discusses the manual approach to code migration, highlighting the risks of human error, especially when dealing with large codebases.
Code Standards and Tooling
He talks about using code standards and tooling like ESLint to enforce good coding practices and discourage outdated or deprecated patterns.
The Importance of Auto-Fixing in ESLint
Lane emphasizes the significance of auto-fixing in ESLint and how it helps reduce developer friction in adhering to code standards.
Using TypeScript for Code Quality
He explores the use of TypeScript in reducing deprecated code and improving overall code quality through enhanced type systems.
Ratcheting Concept in Code Evolution
Lane introduces the concept of 'ratcheting' to prevent new uses of deprecated patterns, ensuring gradual improvement in code quality.
Transforms and Codemods
He discusses the use of transforms or codemods, such as JS Code Shift, to automate code changes efficiently across large codebases.
Risk Appetite in Code Changes
Lane talks about risk appetite in the context of code changes, comparing different risk scenarios to determine appropriate strategies.
Speeding Up Code Evolution
He provides insights into accelerating code evolution, emphasizing the need for strategic and safe migrations to ensure code reliability and maintainability.
Tools and Strategies for Efficient Code Changes
Lane concludes his presentation by discussing tools and strategies that facilitate efficient code changes, including automation and the use of codemods.
Cool, thank you very much.
I hope it's actually as exciting as it sounds, because I'm talking about enterprise code pretty much, so don't be too disappointed, I'm just gonna get that out of the way.
So today I want to talk about, three major things.
So the problem space I'm talking about, so I'm just going to, give a quick introduction.
And then some of the approaches that you can take to resolve these sort of problems.
And then a little bit on risk appetite.
So basically talking about, real life enterprise code.
You don't want to mess up code for your customers, right?
So to get started, think back to 2009.
If you're having trouble, this is a movie that was released.
I don't know why they thought it needed a sequel, but here we are.
And imagine you've just started a company.
It's hard to think back to the tools that are around back then.
But if we move forward to the current year, and you're, like, still working on the code base that is related to, what you build, you're probably going to have some stuff like this.
JQuery, LeftPad, all of these sort of tools are probably still in your code base.
Like people would like to think, oh, nah, I've moved on, I deleted all the other stuff.
As someone who's worked in enterprise, no, you haven't.
If you have these, something needs to change, right?
Really, this is something that we all know is a terrible thing to have.
But, it happens all the time.
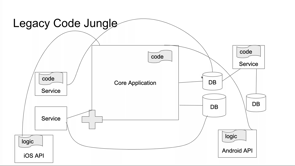
While I'm specifically mentioning a common scenario here, the greater problem that we need to solve is, like, how do we migrate commonly used code to something new?
So in general, there's a lot of cases where we need to get from one API to another.
It might not necessarily be legacy code.
This talk will hopefully be applicable to that.
But my goal is pretty much to give you the tools and ideas you'll need to execute this in the real world.
So not just theoretically, I'm not talking like you go and change like a ref app to something else.
This is like stuff you are releasing to production.
You don't want bugs.
So to get down to the approaches for solving these problems, I'm going to talk about manual migrations, as well as like code standards and transforms.
So the manual approach generally just, refers to like manually updating code by hand.
But the major consequence of this approach is, human error.
So we introduce bugs all the time.
Imagine if you're changing 10, 000 files.
You're probably going to introduce a lot of bugs, not just a little bit, like a lot.
So repetition generally makes this worse even.
I've found like when we've done migrations at Atlassian, we tend to like just get caught in our ways, and then we end up introducing systematic errors as well.
So code review doesn't really help at this sort of scale.
Because if you do this sort of thing, you're probably not going to pick it up.
You're just not going to notice differences.
Or if everything looks the same, you're going to notice everything being wrong.
So it's really hard to pick that sort of up.
So because of this, you're probably heavily leaning on stuff like validation tools, so like types, as well as like tests.
If you were to do a manual migration, you'll probably really need to write a lot of tests, but you also probably need to really bring up your types to a really good coverage.
So Yeah, so the main benefits of manual migration, are that they're super easy to do.
There's not much difficulty of actually changing the code if you can always just change it to what you want it to be, right?
Especially if you understand what the change is, it's quite simple.
But if it's, also easy to get started, because you're just changing to something new, you already know what's going on.
So you can just go change it, right?
So there's no real requirement to define any tooling around this.
You can just take what you've got, just go change it, normal feature development process.
But overall, manual migration I would mark as actually quite risky.
That might be something you can accept, especially because some of the other approaches I'm going to talk about might have some, inefficiencies into getting them going, but yeah.
Overall, at Atlassian we really try and avoid these nowadays because it's very expensive.
So the second thing I want to talk about is code standards.
I'm pretty much talking about using tooling to point people towards what you want.
As well as discouraging what you specifically don't want.
Generally, you can get this to a point where you actually just ban people from doing stuff you don't want.
That can be controversial in some codebases.
Sometimes people like to sprinkle ESLint disable rules all over the place.
Yeah, that can be a real problem, but ESLint is an example of one of these tools, because it does static code analysis for identifying bad patterns in JavaScript, it also provides feedback to the developer which can really be something key about enforcing code standards if it just went red and you didn't know why, there's nothing you can do, right?
The really important thing that I find for ESLint is auto fixing.
It's a super useful tool.
It really gets stuff over the line because when you auto fix, it means it's automatically, the developer doesn't have to think about what's going on.
If they did something wrong, you need to reduce that, frequent, like the friction between actually getting it right.
If you can just make it happen when they hit save, that's a massive win.
Yeah, so for ESLint, generally what I'd recommend is using a modern rule set, so make sure to keep these up to date, so ESLint recommended as an example, you might be familiar with the Airbnb rule set, stuff like that, there's all sorts of things, and you'll want to make sure to restrict imports that you don't want as well, that's really key here, so for example, restrict jQuery, stuff like that, they're very simple, but, you ESLint is powerful because you can really extend it to do what you want.
So you can use even more detailed plugins.
For example, here, there's a moment.js ESLint plugin that completely, bans Moment and provides you alternatives.
If you're familiar with Moment, it's actually deprecated and you're not supposed to use it nowadays.
You've probably got Moment in your codebase, especially if you haven't gone through and changed it, because it was just such a popular tool.
Time zones in JavaScript is just impossible without some sort of layer on top, right?
And jQuery is another example.
There's even the ESLint plugin for that.
So I would also recommend writing your own plugins.
It's actually really easy if you are familiar with ASTs or abstract syntax trees, but I'm going to go into a bit more detail on how, these sort of things work later on.
Second thing with the type system, when you use a type system like TypeScript or Flow, you can really reduce the, frequency of deprecated code.
If you use this app deprecated operator, that will mark your code like here, where it's very obvious that you shouldn't be doing this anymore.
So stuff like this actually really does help, like you may think it's, people just ignore it, but if people are like, have the choice between two functions, one's deprecated, it's very easy to pick the right one, right?
You can also detect and ban certain things with conditional types.
This is something that I found super useful for when we do migrations at Atlassian, because it means like we might not want to completely cut people out of using certain things, but we can also ban them from doing it in certain ways with the type system.
It's got an example here, how I'm using a conditional type never to make sure that if a component with this opaque type is used, we just ban it out.
I definitely wanted to make clear here as well that this is not the perfect solution because types are often suppressed for various reasons.
So they end up being 'any', so that any type can just be used anywhere and that can filter out a long way, right?
So you might just have oh, this type doesn't line up.
I'm going to chuck expect error on it and just leave it.
The implications of that can actually be quite large because if you reuse what has lost that type, that just spreads everywhere.
Another thing to keep in mind, if you use an untyped package, that instantly does the same thing.
And it's very difficult to work around because every time you interact with that untyped package, you're in trouble.
So I, I would recommend really improving your type coverage if you can.
It's probably one of the most impactful things you can do for your codebase health.
But yeah.
So next concept I want to talk about is ratcheting.
Has anyone here heard of this term before?
Okay, cool, I'm glad I added this slide.
So it's a very simple concept.
It's basically just, do not allow any new usages of a pattern.
And, the way we do that is we pretty much just grep the code, right?
So the usage count can only stay the same or go down.
So when you release a PR, it has to do that.
So that means eventually people are going to start reducing the amount of this and it will go down over time.
So you definitely want to make this sort of stuff really easy to run on your machine.
So if people are running into this in the build and they've realized that they've triggered this rule, they're not going to be very happy.
So try and make it super quick, even though it's running over the code base.
Stuff like ripgrep is really fast.
It's actually super easy.
Just chuck it in a pre commit hook.
And some stuff you can't just find with a grep, right?
Because it's more complicated.
Maybe it's like a structure that you want to avoid.
So what you can do is you can just make sure ESLint picks up that sort of issue and you just check the ESLint.
Very trivial.
The more exciting thing that I want to talk about today, I guess it's relative, are transforms.
Transforms or codemods, a concept that we use to pretty much just change from code from one state to another.
How many people know codemods?
Cool.
So it is a bit more familiar concept.
So JS Code Shift is probably the most popular tool for achieving this.
If you've ever used React, like if you bump React, it actually gives you some code [mods?].
Definitely recommend checking them out if you're doing a React 18 migration.
I think lots of people are doing that right now.
And yeah, the idea is that you pretty much just use an abstract syntax tree, format, which is just like a data structure for representing code.
And then you manipulate that in the code, and then once you've done that manipulation, that just turns back into code.
So AST Explorer is an example, of like how you can do this in the real world.
So an example here, hello world is just like a simple What we've got here is plain text and then on the right is the AST.
So that's represented in that data structure.
And you can see here the stuff like the variable declarator, identifier, literal, stuff like that.
That all represents that code.
And then on the bottom left here, we have, the actual codemod.
So that's calling out to JS code shift, and it's, changing that identifier.
And all it's doing It's just getting the name as a string, reversing it, and then putting it back.
So you can see on the bottom right there, that's the transform code.
So it's a very simple concept, and as you can see here, pretty trivial to do, right?
It's only a couple of lines of code, and you've already done that for effectively your whole code base, right?
You just run this command, and then it goes through.
So transforms are pretty easy to use, but they're also super flexible.
So if you're doing stuff like changing code, you don't have to worry about formatting.
It's, ASP will just do it for you, because it's just doing an in place change.
It's also super repeatable.
This is really important for when you're working at scale because it's easy to rerun.
For example, if you run into a merge conflict and you've manually gone and changed that code, you're gonna have to go understand what the merge conflict did and go fix it, right?
That really sucks, I can attest to that.
Especially when, I was a PR, I did, the other day, they ended up with 50 conflicts.
If I had to go and change 50 files, not doing that.
That's super useful.
It's also stuff that can be changed, to be part of your developer tooling.
Envision, what if you just put it In a bot, and it just did it for you.
You didn't even have to go and do anything, it just merged for you.
And, yes, that is a thing you can buy, by the way, that transformer.
I just, I needed a picture to add to this slide, and yes, if you go to that link, I think you can probably buy it.
Yeah, find and replace is also something that you shouldn't forget about.
ASTs are cool, but, you do have to write the codemod.
If you can just write a regex, maybe do it.
But keep in mind that, whitespace, stuff like that, different code structures might make it too complicated to do it.
So an example here is, like, how you can run this repeatedly.
Same benefits of running a transform.
You could put this in your CI if you wanted, and it automatically did it for you.
But yeah, it's very trivial to do at scale.
Yeah, cool.
So getting to the last, part of the presentation, I want to talk about risk appetite.
So in this example here, we just have a highway, right?
And the speed limit is set to 100 kilometers per hour.
In a highway, you pretty much have a really safe road, right?
It's lots of lanes, there's lots of safety features, you can see there's, stuff that blocks you from, hitting people if you went off the road.
There's, nothing really around to hit.
It's pretty, pretty clean.
But that's why the speed limit is 100 kilometers per hour, right?
Not because of other reasons, not just because it's convenient.
They had to have all of that for it to be a hundred kilometers per hour.
They considered all the risks and then they decided a hundred kilometers per hour is appropriate, right?
So you can compare that to a school zone, right?
So if you think about the risk of this It's not appropriate to go 100 kilometers per hour, right?
So we're on the completely other side of the spectrum.
So there's obviously other caveats as well that you can put on top of that.
So for example, a time frame, like if something makes sense, you can always change the risk as appropriate to the scenario.
I wanted to talk about three major factors of risk.
So first major factor is if your test missed errors.
So this is talking about the concept of like, how confident are you in your tests?
Like, how are you confident that your tests will pick up visual changes, so like visual regression testing, stuff, that would like visibly change to the customer.
Will you pick that up?
Secondly, functional changes, so unit tests, integration tests, stuff like that.
What's different after you've changed stuff?
So this really comes down to what you have decided is correct.
So if you think about like tests, you are writing the test.
You could still write the test wrong.
So that's another aspect as well.
So second aspect, incorrect changes.
So what if your choice is incorrect?
If you change something, You can go change the test, right?
You might need to change the test because it's different.
For example, you move to a new modal library.
You could have had all these features that existed on the previous one.
You might not have known about them.
And then you change to the new one and the customer just raises his ticket like, I can't use key shortcuts anymore.
You might not have known that existed, but it was there, and then you removed the feature implicitly, right?
So there's a few things to think about there of what are the actual impacts of your changes that you as a developer need to think about?
Third is the impact to customers.
So assume you've gone and released an error, what do you do from that point onwards?
So if you're an enterprise company, you might be familiar with some of these terms.
Especially because it's probably very strict guidelines, but at Atlassian, we talk about things like time to recovery.
So like, how long did it take, once the bug was released, for you to resolve the issue?
Blast radius, how many of your customers will be affected?
Are you only, releasing to a certain region and then you cause issues there?
Or are you releasing to, everyone all at once and then it's all blown up and you're in?
Third is measurement.
So you could have introduced a performance regression as well.
If you, need to know what is happening in your code base, you can't just rely on, people raising tickets.
You should be looking at metrics, right?
So what are the risks that you blow out, some of these metrics that you, track?
So to reduce this sort of risk, for tests, what I recommend is you try and have pretty good code coverage.
So unit tests, integration tests, VR tests.
And if you're migrating stuff, maybe if you have poor coverage, it makes sense to just improve the coverage for things that matter.
So you like go find what's actually relevant to you, go improve those tests, and then you move forward, right?
Second is, the risk of incorrect changes.
So manual testing, is really important for this sort of stuff because you don't actually know what's in the code.
That you didn't write, right?
If you go and test it, you can see what actually happens in the browser.
So this is difficult because you need to know what's going on.
You need to know what's going on for customers as well.
You need to replicate all different scenarios.
This is very slow.
Thirdly, for the risk impact to customers, stuff that we do at Atlassian, like feature flagging.
So the idea is that we do like an A/B test when we make our changes.
If the changes are bad, we can instantly hit a button and then it's gone from the customer's computer.
So that's important because if you go and trigger like a new AWS deployment or something like that, you're in trouble.
That's going to take 30 minutes.
That's probably too bad.
And you'll get like a lot of customers complaining, even though you've already shipped the fix, right?
So when you actually do a rollback, also important to have stuff like a runbook, so you know that like you can just reduce that time.
As quick, as much as you can, and be ready to hotfix just in case your rollback doesn't work.
So maybe you, it's too far in the past, and you need to fix something, you might need to prepare a fix that gets pushed really quickly through.
Also make sure to have monitoring.
So those metrics I was talking about, set up alerts.
So Opsgenie is a tool Atlassian has, but whatever alerting tool you have, you can just have alerts for your metrics to figure out, oh, stuff has blown up.
We need to go fix this now instead of waiting for tickets to roll in.
So the problem with all of these things I'm talking about is they're quite slow, right?
All of these concepts, like normal development, nothing special, but it are very slow if you're changing 10, 000 files, right?
How can we speed this up?
So if we make this change, how can we possibly come up with a way that we're not actually going to change things for the customer.
So for example, you're switching libraries, right?
Stuff shouldn't change for the customer.
But what about the code?
The code is changing.
Is there stuff that we can assume is equivalent?
The easiest thing to release is stuff that has no changes at all.
For example, you bump a library and then nothing changes.
That's exactly what we want, right?
So an axiom is pretty much just a statement that we assume to be true.
So the example here, these lines are parallel, so therefore we know they won't intersect.
That's a rule we just assume is true, right?
We don't worry about it once we've set that rule.
So if we break down the problem, you can test those axioms and decide that they're true.
So In this code example, the axiom would be that, the code on the first line is the same as the code on the second line.
So if you make those sort of rules when you're doing your migration, it makes stuff a lot easier because, the compiled code could look different.
But it's equivalent.
Stuff like that is very useful.
Another thing to keep in mind, like the third line, that is not the same.
Don't get caught up on those being the same and you using that as a rule, right?
That's what we're trying to avoid.
And then, yeah, so if we do this, we can apply a process similar to this, right?
Pretty much, say we have a set of code that we want to change, we could use something like a codemod, right?
If we do that codemod, there's risk that we're changing stuff to be different.
The way we can avoid changing stuff to be different is to decide what we consider safe and migrate only that.
But if we do that, there's going to be stuff that we know is unsafe.
So what we do then is we take another codemod, make it equivalent to something that we know is safe.
Or make a new thing safe.
Generally, it's effectively, you remove old edge cases until there are no more edge cases, and if you can't remove those edge cases, then you probably just have to go back and manually migrate it.
So this is something that we're applying in Atlassian today.
It's working really well for us.
But yeah, it's a relatively new process for us, but it's really sped up process because we're not relying on the sort of stuff I mentioned earlier, where we need all of that to be done, like manual testing, all the test coverage to be perfect, all of that.
So a good approach for big changes, is you make changes in multiple passes, so in the first pass just make it as trivial as possible, but if you make it as trivial, you want to cover as much ground as you can, so that means like the least complex stuff gets all knocked out when you're not even thinking about it, and as you go on you can take on more complex rules that you're setting up, so more complex axioms, so if you keep doing this, hopefully the passes will get smaller and smaller.
And then the stuff you have to think about more will be tiny.
You don't want to think about just like 1 plus 1 equals 2, a million times if you're manually migrating it.
You can just let your codemod do it, right?
So if you encounter something more complex, in each parse, you can also just move that on to the next batch, like an iterative process I talked about before.
Just split that out and treat it separately.
And yeah, everyone's probably quite familiar with scope creep as well, right?
I don't know, I forgot time to let it play out.
I'll pretend that you all know this.
You probably do.
Scope creep, try not to change things that are unrelated to your code.
But definitely don't lose information.
So it may be tempting to just go through and just fix something you've noticed is wrong, right?
If you're combing through a whole code base, you're gonna find lots of bugs.
But, if you try and scope this into your work, you're never gonna finish.
It's just gonna take up all your time.
So drop it and then come back later.
So that later is probably defined by your product manager.
But make sure it is documented well and the impact and all of that is documented well.
But yeah, you will never complete a project if you keep adding scope.
If you are trying to upgrade stuff as well, take small steps.
And finally, some tools I wanted to talk about that make stuff easier.
All the transforms and stuff like that.
I did mention that you can run them on Bamboo, but there's actually some really cool stuff you can do, once you're getting a bit more complex with it.
When you get merge conflicts, you can actually get Git to run for you, and automatically fix it for you.
Imagine, you tried to merge your PR, and then there was a merge conflict.
You could have a bot just run through and then fix that merge conflict for you.
Instead of, think of it like a merge strategy, right?
Like, how you have to pick incoming or current.
You could just let the bot just run the codemod and then that's the resolution.
Stuff like a PR generation tool can be really useful as well.
Say, you might be familiar with, Renovate or Dependabot, stuff like that.
You can do that with Codemods as well.
Another thing that's also useful is like a Codemods CLI.
It seems like a little thing, but when you run Codemods, you're touching a lot of files, right?
If you can have a Codemods CLI where you can really pick down and target on what you want to target, you can make this run on your machine really quickly.
Especially like if you run something like RipGrep over the top first.
RipGrip runs really fast.
You can find oh, I want a file with this import.
That will cut down like 10, 000 files into a very minimal amount of files, stuff like that.
But yeah, that's all I have today.
My slides are on GitHub.
Thanks all for coming.
When you first start building a web application, it’s easy to write code and pull in the dependencies you need. What happens in 5 years (or 5 weeks) when the industry has decided what once was a super useful library is causing enterprise computers to become fire hazards?
In this talk, we’ll cover how we can modernise our code to the new dependencies we want, build tools and processes to migrate to new code, and avoid breaking things without moving too slowly.










{kind=link}