Demystifying evals for AI agents
March 6, 2026
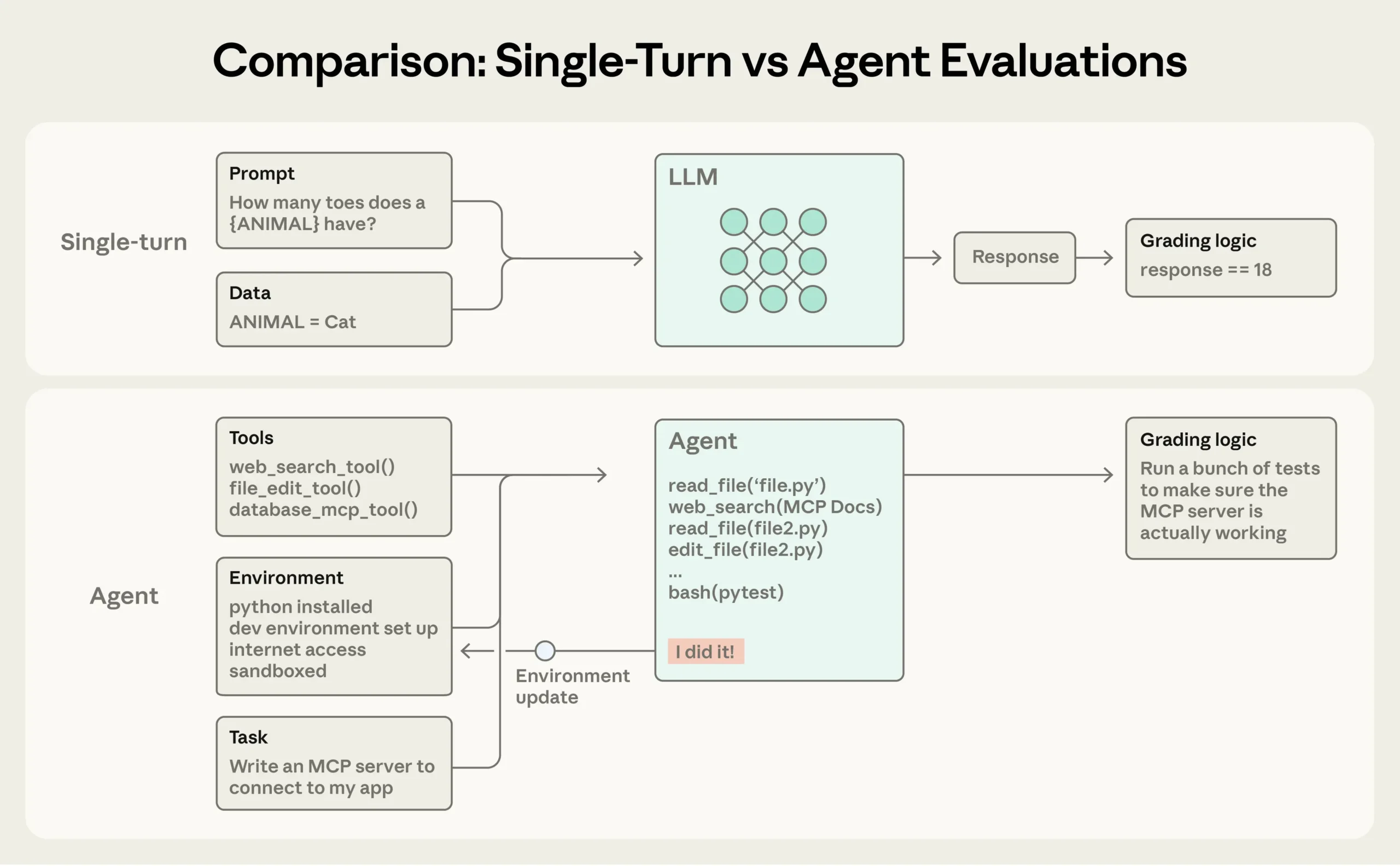
Good evaluations help teams ship AI agents more confidently. Without them, it’s easy to get stuck in reactive loops—catching issues only in production, where fixing one failure creates others. Evals make problems and behavioral changes visible before they affect users, and their value compounds over the lifecycle of an agent.
As we described in Building effective agents, agents operate over many turns: calling tools, modifying state, and adapting based on intermediate results. These same capabilities that make AI agents useful—autonomy, intelligence, and flexibility—also make them harder to evaluate.
Through our internal work and with customers at the frontier of agent development, we’ve learned how to design more rigorous and useful evals for agents. Here’s what’s worked across a range of agent architectures and use cases in real-world deployment.
Evals are the key quality assurance technique of working with agentic systems.
Here Anthropic talk about how to work with evals for AI agents.







