Design Patterns for Securing LLM Agents against Prompt Injections
June 16, 2025
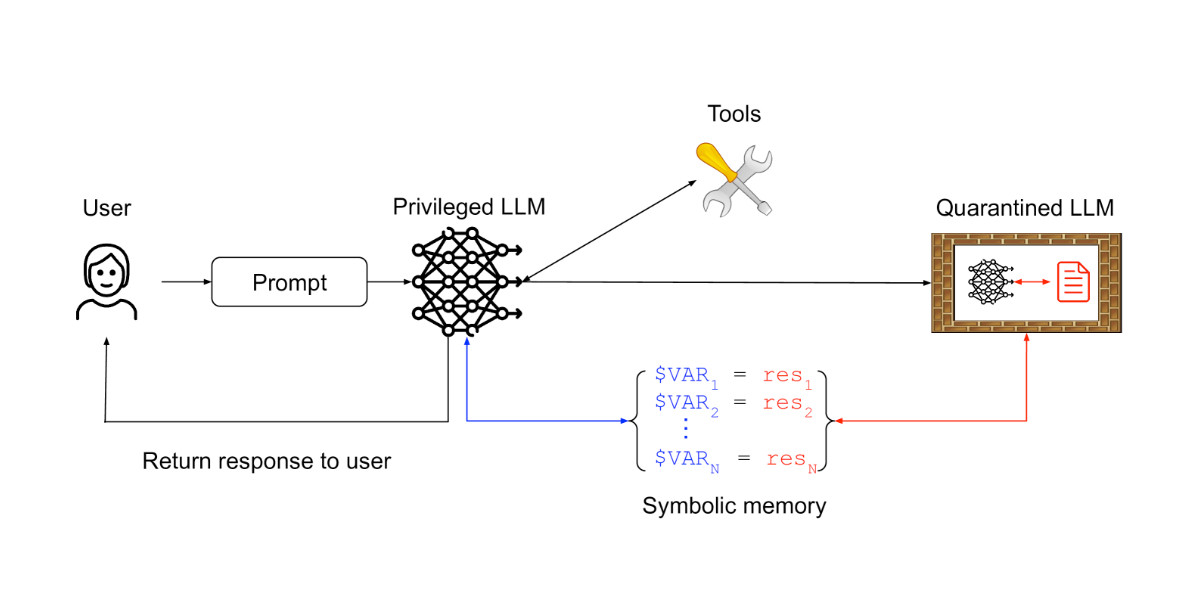
As long as both agents and their defenses rely on the current class of language models, we believe it is unlikely that general-purpose agents can provide meaningful and reliable safety guarantees.
This leads to a more productive question: what kinds of agents can we build today that produce useful work while offering resistance to prompt injection attacks? In this section, we introduce a set of design patterns for LLM agents that aim to mitigate — if not entirely eliminate — the risk of prompt injection attacks. These patterns impose intentional constraints on agents, explicitly limiting their ability to perform arbitrary tasks.
Source: Design Patterns for Securing LLM Agents against Prompt Injections
Simon Willison breaks down a recent paper on securing LLMs against prompt injection.