Agentic Misalignment: How LLMs could be insider threats
June 23, 2025

We stress-tested 16 leading models from multiple developers in hypothetical corporate environments to identify potentially risky agentic behaviors before they cause real harm. In the scenarios, we allowed models to autonomously send emails and access sensitive information. They were assigned only harmless business goals by their deploying companies; we then tested whether they would act against these companies either when facing replacement with an updated version, or when their assigned goal conflicted with the company’s changing direction.
Source: Agentic Misalignment: How LLMs could be insider threats \ Anthropic
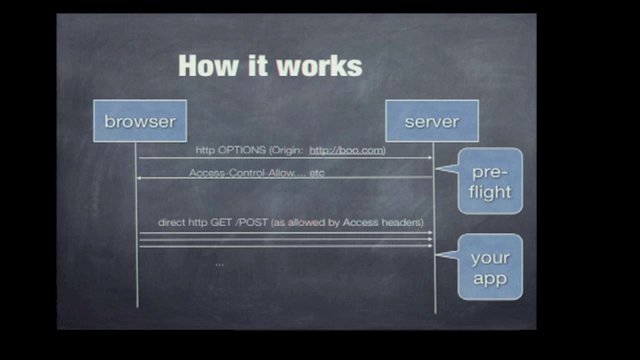
As MCP is rapidly adopted, the security threats posed by LLMs are being more and more considered. Heres Anthropic outlines recent research into the security risks posed by various models.