Learn how Web Components excel at progressively enhancing server-rendered HTML without worrying about additional dependencies, shadow DOM, or going full SPA.
We've long been a ling time proponent of Web Components here at Conffab, but they can be daunting to get started with.
But there are ways to start adopting the that don't require getting to grips with their full complexity.
Start thinking about them ass progressive enhancement and build from there.
CSS Intelligence: Speculating On The Future Of A Smarter Language
CSS has evolved from a purely presentational language into one with growing logical powers — thanks to features like container queries, relational pseudo-classes, and the if() function. Is it still just for styling, or is it becoming something more? Gabriel Shoyombo explores how smart CSS has become over the years, where it is heading, the challenges it addresses, whether it is becoming too complex, and how developers are reacting to this shift
CSS has evolved over the last 30 years from a straightforward replacement for decorative HTML tags like font and attributes like color to a sophisticated language for styling, layout, even generated content.
Here Gabriel Shoyombo traces its history and growing complexity and sophistication, and tasks a look at where the language might be headed in this excellent article.
How to Identify Your Unknown Unknowns in Web Development
If you’re a web developer, you know what HTML, CSS, and JavaScript are. Although massive topics by themselves, these contain many of your “known knowns.”
You’re aware of languages like TypeScript, WebAssembly, or Rust, that touch your world but are languages you may or may not be comfortable with. Those you are not, represent some of your “known unknowns.”
And then there are concepts like, let’s say, AT-SPI, palpable content, restricted production, __qem, or qooxdoo, that maybe you’ve never heard of, even though they can relate to your work. These are some of your “unknown unknowns.”
“Cool,” you say, “what am I supposed to do with this.”
Jens Meier observes in Web Development there are a lot of things we need to know, and many we don't know we don't know.
This analogy is lifted from a convoluted quote from US Secretary of Defence during the second Gulf War (and at other times over a 3 decade period) about known knowns, and unknown unknowns.
It's one I've used for years when framing for myself and others what we try to do with our conference programs–help people find the gaps in their knowledge, the things they don't now they don't know.
And that's a ket goal of Conffab too.
Before flex, before grid, even before float, we still had to lay out web pages.Not just basic scaffolding, full designs. Carefully crafted interfaces with precise alignment, overlapping layers, and brand-driven visuals. But in the early days of the web, HTML wasn’t built for layout. CSS was either brand-new or barely supported. Positioning was unreliable. Browser behavior was inconsistent.And yet, somehow, we made it work.
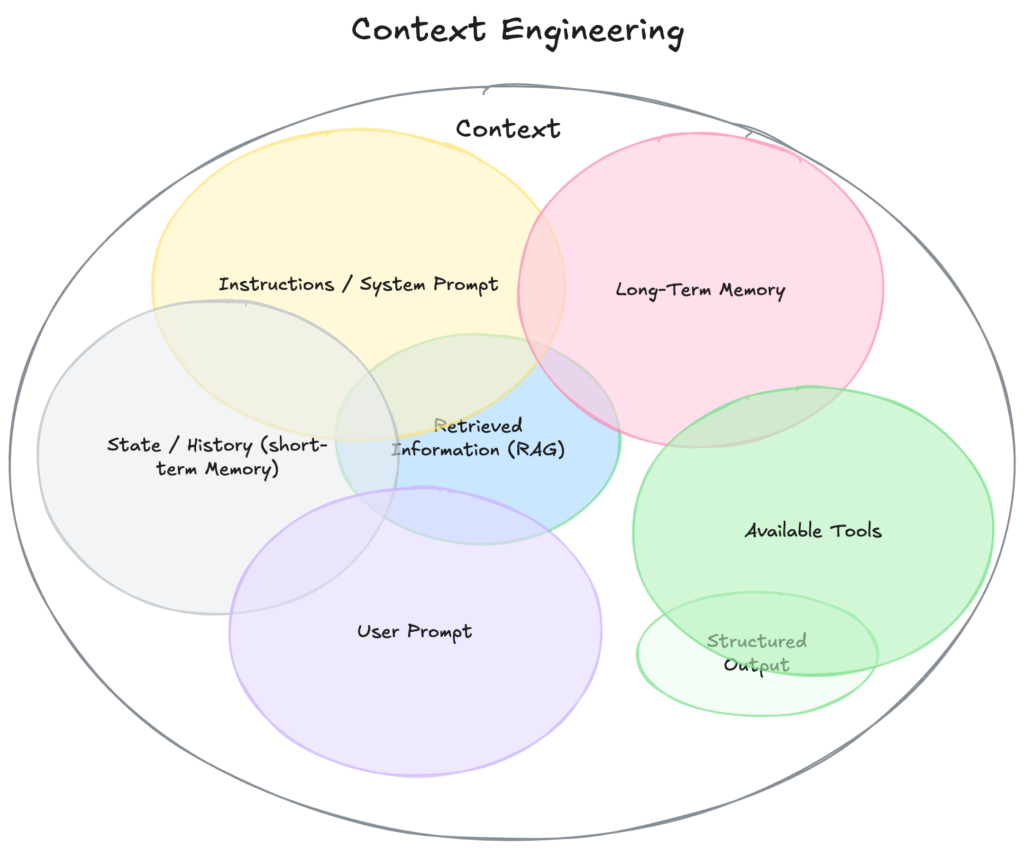
Context Engineering is new term gaining traction in the AI world. The conversation is shifting from “prompt engineering” to a broader, more powerful concept: Context Engineering. Tobi Lutke describes it as “the art of providing all the context for the task to be plausibly solvable by the LLM.” and he is right.
With the rise of Agents it becomes more important what information we load into the “limited working memory”. We are seeing that the main thing that determines whether an Agents succeeds or fails is the quality of the context you give it. Most agent failures are not model failures anyemore, they are context failures.
The term context engineering has recently started to gain traction as a better alternative to prompt engineering. I like it. I think this one may have sticking power.
In a 1912 commencement address, the great American jurist and antitrust reformer Louis Brandeis hoped that a different occupation would aspire to service:The peculiar characteristics of a profession as distinguished from other occupations, I take to be these:
First. A profession is an occupation for which the necessary preliminary training is intellectual in character, involving knowledge and to some extent learning, as distinguished from mere skill.
Second. It is an occupation which is pursued largely for others and not merely for one’s self.
Third. It is an occupation in which the amount of financial return is not the accepted measure of success.
In the same talk, Brandeis named Engineering a discipline already worthy of a professional distinction. Most software development can’t share the benefit of the doubt, not matter how often “engineer” appears on CVs and business cards. If React Summit and co. are anything to go by, frontend is mired in the same ethical tar pit that cause Wharton, Kellogg, and Stanford grads to reliably experience midlife crises.3
I’m not the only one thinking about how context management is the key to good LLM applications. Since publishing our post detailing how long contexts fail, a conversation emerged regarding the term “context engineering,” compared to “prompt engineering.” (Let’s be clear…I had nothing to do with starting the debate, it’s just a happy coincidence…)
Today, Andrej Karpathy weighed in, supporting “context engineering”:
“People associate prompts with short task descriptions you’d give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
When generative AI first started getting attention, the role of the Prompt Engineering and Prompt Engineering got a lot of attention. That's waned over time, but the focus on the prompt as the key way of interacting with LLMs remains. Some like Drew Breunig suggest it's context not the prompt alone that we should focus on. Here he explains.
Design Leadership in the Age of AI: Seize the Narrative Before It’s Too Late
AI is transforming the way we work — automating production, collapsing handoffs, and enabling non-designers to ship work that once required a full design team. Like it or not, we’re heading into a world where many design tasks will no longer need a designer.If that fills you with unease, you’re not alone. But here’s the key difference between teams that will thrive and those that won’t:
Some design leaders are taking control of the narrative. Others are waiting to be told what’s next.
We've focussed a lot of on the impact of LLMs and generative AI on software engineering, but these technologies are also transforming the process and practice of design. Here Andy Budd suggests design leaders need to take this transformation seriously and take charge.
Tech companies are only pretending to innovate, through copying futuristic aesthetics from science fiction without understanding their purpose.
Technological progress has always come from humanity’s grasp exceeding our reach; before we could build drones we needed to imagine flight. However, our successful flying machines bore little resemblance to their fictional counterparts. Design has not learned this lesson, and continues to try to wow users by recreating familiar aesthetics of futurity, rather than the outcomes depicted in this media. And whenever it does this (as with any aesthetics-first effort) the result is always a failure. The inevitable future disappears like so much smoke.
We've become fixated on monolithic patterns like SPA for all web content, when perhaps different approaches make sense in different contexts. Here Den Odell explains the Islands pattern and when it might be best deployed.
A short history of web bots and bot detection techniques
Did you know your favorite website can detect when you’re browsing it in public transport and when you scroll it laying in your bed? Today we’ll learn how they can do it and how this info is used to fight bots.
If you build websites especially ones with any kind of forms, you'll doubtlessly run into the scourge of bots filling them in and submitting them.
Learn how to detect if your visitor is a bot and what to do about it.
CSS animations have come a long way since Apple first introduced them to the web in 2007. What started as simple effects like animating from one color to another has turned into beautiful, complex images twisting and flying across the page.
But linking these animations to user behavior like scrolling has traditionally required third-party libraries and a fair bit of JavaScript, which adds some complexity to your code. But now, we can make those animations scroll-driven with nothing more than a few lines of CSS.
Scroll-driven animations have increased browser support and are available in Safari 26 beta, making it easier for you to create eye-catching effects on your page. Let me show you how.
At this point, almost every software domain has launched or explored AI features. Despite the wide range of use cases, most of these implementations have been the same (“let’s add a chat panel to our app”). So the problems are the same as well.
Something about the chat interface that came with the release of ChatGPT and GPT3.5 which powered it was the killer feature for LLMs. The reasonably capable GPT3 had been around for a couple of years, and a relatively small number of developers had been exploring it via the API and playground, but it was the release of ChatGPT in late November 2022 that ignited the modern generative AI wave of excitement, innovation and it's fair to say hype.
The breathtaking success of chatGPT (gaining 100M active monthly users far faster than any product that had come before it) meant that the chat pattern came to dominate AI related product design and features.
But surely there's many more interaction patterns out there to be discovered and refined. Luke Wroblewski has been thinking in public a lot about what comes beyond the chatbot.
Separation of concerns is a computer science principle introduced in the mid 1970s that describes how each section of code should address a separate piece of a computer program. Applying this principle results in more modular, understandable, and maintainable codebases.
Web designers & developers of a certain age might remember the separation of concerns applied to the three languages of the web: HTML provides the structure, CSS provides the style, and JavaScript provides the behavior of a web page.
Separation of concerns is a long standing computer science pattern, and one which standards based web developers adopted around the turn of the century n architecting the code of web sites.
Here Brad Frost revisits the concept for modern web development.
The End of Code as We Know It (The Third Wave is Here) – YouTube
The “Third Wave” of Software: Moving from classical source code to natural language instructions.English as Code: How LLMs are turning English into a functional programming language.
The Philosophy of BMad: Why the method is designed as a human-readable agent framework, not just another tool.
Mastering the Future: Why software engineering principles are more important than ever in the age of AI “vibe coding.”
This video is for anyone who wants to understand the “why” behind the AI revolution in coding. If you want to see what the future looks like, and how you can become a master of it, this is for you.
Of all the fields being impacted by LLMs, software engineering is currently one where this is definitely happening.
Now software engineering (or SWE as the kids say these days) is much more than writing code, but that is certainly a significant aspect of it. And as we've covered recently and will doubtless do frequently, there's a lot of speculation about what that will look like in an era of LLMs.
What Developers Should Know About Modern CDNs and the Edge
“Traditionally, CDNs and Edge have been under the control of, like, IT or Ops — or security, or both. […] Developers frankly [didn’t] like it, because it just made it harder for them to do their jobs; it’s not something that enabled innovation. I think today, the demands of the applications require […] developers to really think about how […] the [software] architecture can use the infrastructure correctly. Now, the infrastructure should still be operationally an abstraction — they shouldn’t actually have to care about where our PoPs [points of presence — Fastly’s edge nodes] are. They should just care that they’re fast.”
We've covered CDNs and particularly edge computing (with the likes of CloudFlare workers, Fastly Edge compute, AWS Lambda) quite a lot on Conffab.
In this interview Fastly co founder and chief architect Artur Bergman, with the New Stack's Richard MacManus (you should read his ongoing series at Cybercultural on the early Web) discusses how CDNs and edge computing are moving the responsibility for infrastructure away from devops and toward developers.
Give your coding agent browser superpowers with DevTools access via MCP
When working with coding agents it’s essential to provide them with the signals they need to determine whether they’ve done the right job or not. The typical signals come from inspecting the generated code, type-checking, linting, and running tests. What’s missing though is access to the application itself. If we could provide the agent with the tools needed to inspect and interact with the application at runtime, it would allow it to check its work directly rather than infer it from the code.
There’s been a lot of buzz lately about playwright-mcp which does exactly that. I figured I’d try it out this weekend but turns out it doesn’t play nicely with Electron, which the app I’m currently hacking on is using. This gave me an idea though, what if we could leverage the Chrome DevTools Protocol (CDP) in a more direct fashion?


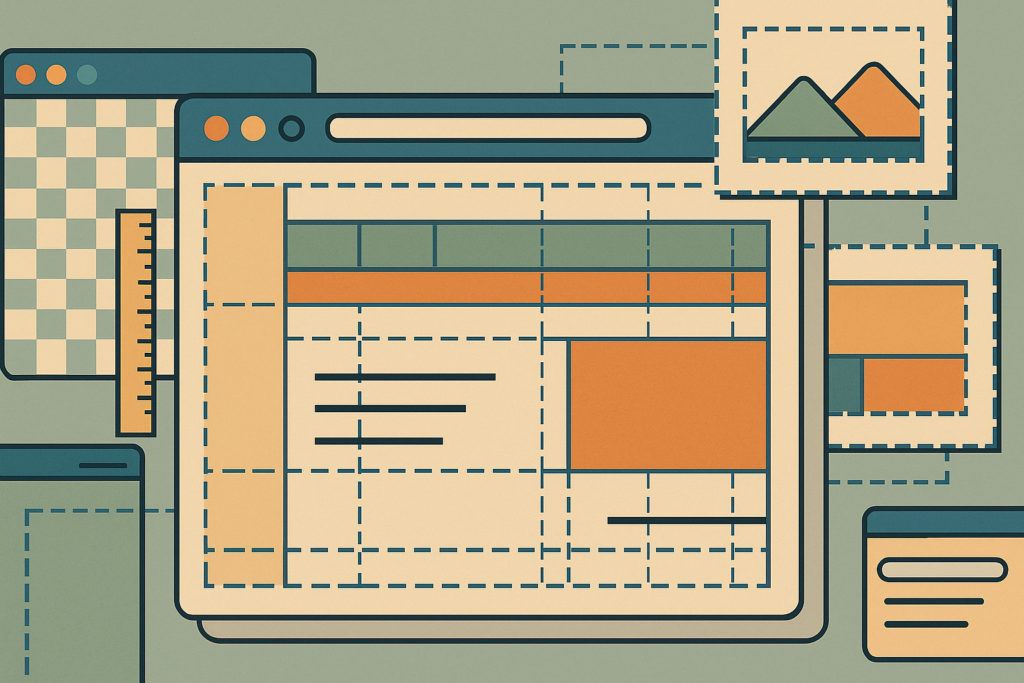











Separation of concerns is a computer science principle introduced in the mid 1970s that describes how each section of code should address a separate piece of a computer program. Applying this principle results in more modular, understandable, and maintainable codebases.


