For decades, the only way to modify an application’s state was through a human interface. That assumption is starting to break. Most human-computer interaction has been built around two patterns: issuing commands (typing, clicking, speaking) and manipulating representations (dragging, resizing, arranging, formatting). Every productivity tool ever built is designed around one or both of those. The keyboard, the mouse, the touchscreen. That is the full vocabulary. The interface and the product were, for practical purposes, the same thing.
The Interface Is No Longer the Product

This essay captures the transitional moment we're in, where all systems, the software systems we've been building for decades have been effectively designed for humans, but we're already, and increasingly, the users, will be agents.
What do software products look like in that world
The Center Has a Bias | Armin Ronacher’s Thoughts and Writings

Whenever a new technology shows up, the conversation quickly splits into camps.
There are the people who reject it outright, and there are the people who seem
to adopt it with religious enthusiasm. For more than a year now, no topic has
been more polarising than AI coding agents.There is a difference between saying “this looks flawed in principle” and saying
“I used this enough to understand where it breaks, where it helps, and how it
changes my work.” The second type of criticism is expensive. It costs time,
frustration, and a genuine willingness to engage.But what does the center look like? I consider myself to be part of the center:
cautiously excited, but also not without criticism. By my observation though
that center is not neutral in the way people imagine it to be. Its bias is not
towards endorsement so much as towards engagement, because the middle ground
between rejecting a technology outright and embracing it fully is usually
occupied by people willing to explore it seriously enough to judge it.
This piece by Armin Ronacher captures very well how I've been thinking about the apparent schism between very experienced software engineers, some of whom are strong proponents of AI for software engineering, and others of whom are strong opponents.
Cybersecurity Looks Like Proof of Work Now
AI, security, software engineering
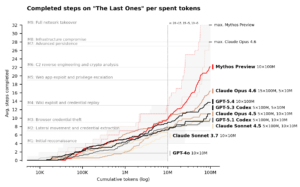
Last week we learned about Anthropic’s Mythos, a new LLM so “strikingly capable at computer security tasks” that Anthropic didn’t release it publicly. Instead, only critical software makers have been granted access, providing them time to harden their systems.
This chart suggests an interesting security economy: to harden a system we need to spend more tokens discovering exploits than attackers spend exploiting them.
While there has been skepticism, to say the least from some quarters as to the claims about Anthropic's new Mythos models capabilities when it comes to cybersecurity, third-party analysis is now suggesting that it does have capabilities we've yet to have seen in large language models to date.
Here Drew Brunick makes observation that bad actors are now only bounded by money and that in the ongoing Red Queen dilemma of cybersecurity the only response Istio spend more money more quickly on tokens defending against vulnerabilities in your software and the software that you rely on.
Slop Is Not Necessarily The Future\

A couple of years ago, “slop” became the popular shorthand for unwanted, mindlessly generated AI content flooding the internet including images, text, and spam. Simon Willison helped popularize the term, though it had been circulating in engineering communities in the years prior.
I want to argue that AI models will write good code because of economic incentives. Good code is cheaper to generate and maintain. Competition is high between the AI models right now, and the ones that win will help developers ship reliable features fastest, which requires simple, maintainable code. Good code will prevail, not only because we want it to (though we do!), but because economic forces demand it. Markets will not reward slop in coding, in the long-term.
I must admit to not being a particular fan of the term "slop" when it comes to AI-generated content of any kind, to be quite honest, but particularly when it applies to code.
The overall argument is one for another day. Here Soohoon Choi argues that there are economic incentives or code generators to increasingly improve the quality of their output. And that empirically maps onto what we have seen over the last several years.
Eight years of wanting, three months of building with AI – Lalit Maganti

For eight years, I’ve wanted a high-quality set of devtools for working with
SQLite. Given how important SQLite is to the industry1, I’ve long been puzzled that no one has invested in building
a really good developer experience for it2.A couple of weeks ago, after ~250 hours of effort over three months3 on evenings, weekends, and vacation days, I finally
released syntaqlite
(GitHub), fulfilling this
long-held wish. And I believe the main reason this happened was because of AI
coding agents4.Of course, there’s no shortage of posts claiming that AI one-shot their project
or pushing back and declaring that AI is all slop. I’m going to take a very
different approach and, instead, systematically break down my experience
building syntaqlite with AI, both where it helped and where it was
detrimental.
Stories like this are valuable because particularly for those who aren't working extensively with AI for software development, it can be hard to even imagine the scale and capability of these systems now.
So, particularly if you're still a little skeptical, or perhaps you use Copilot, but not an agentic system, I highly recommend you read this article to get the sense of what a capable software engineer with these technologies is now able to do in a matter of weeks although this is a very complex project and in far less time you can certainly build very sophisticated systems.
Components of A Coding Agent – by Sebastian Raschka, PhD
AI, AI Engineering, coding agent
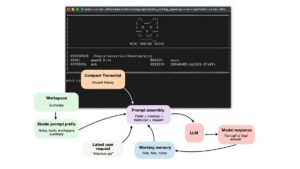
In this article, I want to cover the overall design of coding agents and agent harnesses: what they are, how they work, and how the different pieces fit together in practice. Readers of my Build a Large Language Model (From Scratch) and Build a Large Reasoning Model (From Scratch) books often ask about agents, so I thought it would be useful to write a reference I can point to.
More generally, agents have become an important topic because much of the recent progress in practical LLM systems is not just about better models, but about how we use them. In many real-world applications, the surrounding system, such as tool use, context management, and memory, plays as much of a role as the model itself. This also helps explain why systems like Claude Code or Codex can feel significantly more capable than the same models used in a plain chat interface.
Sebastian Raschka brought us the books Build a Large Language Model (From Scratch) and Build a Large Reasoning Model (From Scratch) And here it turns his attention to examining how coding agents or coding harnesses work.
The Cathedral, the Bazaar, and the Winchester Mystery House – O’Reilly

In 1998, Eric S. Raymond published the founding text of open source software development, The Cathedral and the Bazaar. In it, he detailed two methods of building software:
The ideas crystallized in The Cathedral and the Bazaar helped kick off a quarter-century of open source innovation and dominance.
But just as the internet made communication cheap and birthed the bazaar, AI is making code cheap and kicking off a new era filled with idiosyncratic, sprawling, cobbled-together software.
Meet the third model: The Winchester Mystery House.
Drew Breunig, who has done as much as anyone to explore and popularise the ideas around context engineering, reflects on the current state of software engineering through the lens of a classic late 1990s piece, The Cathedral and the Bazaar.
He argues we are now seeing a third approach, the Winchester Mystery House approach to software engineering.
I think it's important to try and understand and reason about the obvious profound transformations that are happening within the domain of software engineering.
And this piece by Breunig is definitely a valuable contribution to the conversation.
damn claude, that’s a lot of commits | AI Focus
AI, AI Engineering, coding agent
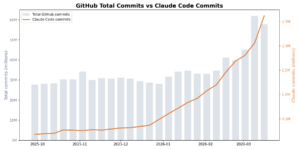
The week of September 29 2025, there were 27.7 million public commits on GitHub. Claude Code accounted for 180,000 of them, about 0.7%. By the week of March 16 2026, total weekly commits had grown to 57.8 million (itself a 2.1x increase, likely driven in part by AI tooling), and Claude Code accounted for 2.6 million, or 4.5%. All AI coding tools combined now sit at roughly 5% of every public commit on GitHub. For context, GitHub’s Octoverse 2025 report recorded 986 million code pushes for the year, with monthly pushes topping 90 million by May 2025, and that trajectory hasn’t slowed down.
Claude Code went from 0.7% to 4.5% of all public GitHub commits in six months
Firstly, how did I not know that Semi Analysis had a podcast!
Here Paul Kinlan has a deeper look into the numbers associated with coding agent commits to public repositories on GitHub Actions. There's certainly a bunch of caveats here, but still the numbers are remarkable.
Encoding Team Standards

I have observed this pattern repeatedly. A senior engineer, when asking
the AI to generate a new service, instinctively specifies: follow our
functional style, use the existing error-handling middleware, place it in
lib/services/, make types explicit, use our logging utility rather than
console.log. When asking the AI to refactor, she specifies: preserve the
public contract, avoid premature abstraction, keep functions small and
single-purpose. When asking it to check security, she knows to specify:
check for SQL injection, verify authorization on every endpoint, ensure
secrets are not hardcoded.A less experienced developer, faced with the same tasks, asks the AI to
“create a notification service” or “clean up this code” or “check if this
is secure.” Same codebase. Same AI. Completely different quality gates,
across every interaction, not just review.This is a systems problem, not a skills problem. And it requires a
systems solution.
The style, conventions, patterns of a codebase are things that the developers who work on it slowly internalize through experience, through exposure to code. But rarely from sitting down and reading documentation as to those properties of a project.
And we know LLMs are really good at taking such documentation and incorporating it into the context of how they work.
So here Rahul Garg proposes
treating the instructions that govern AI interactions (generation, refactoring, security, review) as infrastructure: versioned, reviewed, and shared artifacts that encode tacit team knowledge into executable instructions, making quality consistent regardless of who is at the keyboard.
Quantization from the ground up | ngrok blog

Qwen-3-Coder-Next is an 80 billion
parameter model 159.4GB in size. That’s roughly how much RAM you
would need to run it, and that’s before thinking about long context windows.
This is not considered a big model. Rumors have it that frontier models have
over 1 trillion parameters, which would require at least 2TB of RAM. The
last time I saw that much RAM in one machine was never.But what if I told you we can make LLMs 4x smaller and 2x faster, enough to run very capable models on your laptop, all while losing only 5-10% accuracy.
Sam Rose writes, develops, incredible visual essays that explain complex concepts in very approachable ways like this piece on prompt caching from late last year.
He returns with a long and detailed explanation of quantization, the seemingly magical property of LLMs that by reducing the precision of the floating point numbers which capture the weights of the model substantially, we don't actually reduce the capability of the model much at all. Which then allows us to run models with less memory and greater performance.
We Rewrote JSONata with AI in a Day, Saved $500K/Year | Reco

A few weeks ago, Cloudflare published “How we rebuilt Next.js with AI in one week.” One engineer and an AI model reimplemented the Next.js API surface on Vite. Cost about $1,100 in tokens.
The implementation details didn’t interest me that much (I don’t work on frontend frameworks), but the methodology did. They took the existing Next.js spec and test suite, then pointed AI at it and had it implement code until every test passed. Midway through reading, I realized we had the exact same problem – only in our case, it was with our JSON transformation pipeline.
Long story short, we took the same approach and ran with it. The result is gnata — a pure-Go implementation of JSONata 2.x. Seven hours, $400 in tokens, a 1,000x speedup on common expressions, and the start of a chain of optimizations that ended up saving us $500K/year.
Stories like this are data people should take on board when thinking about how they work with AI technologies and the value of them.
I think if you are not working extensively with these technologies, and even if you are, it can be hard to fathom just how capable they are and what their implications might be.
I Built a Design Team Out of AI Agents – MC Dean percolates
Then I decided to share some of the tools I’ve been using to learn about working with AI more deeply and to explore what it means for design as a practice. I made a set of design skills you can use with any model and a set of Inclusive design skills.
This has been pretty handy but next I wanted to explore how a group of design agents would perform and play around with that idea. There’s plenty of room for improvement here, but it has been a very fun experiment and I learned heaps.
MC Dean shares a range of design skills she's built for working with AI as a designer.
Reports of code’s death are greatly exaggerated
AI Native Dev, coding agent, software engineering

Until probably late 2025, I would have largely agreed with the sentiment of this comic. Having been working professionally as a software engineer for decades, having studied software engineering in the 1980s at university, I’ve seen the promise of high order abstractions replacing Human programming in languages like C or Java or Python or people of the language of your choice touted over and over again.
Whether it was 4GLs in the 1980s, or low-code, no-code more recently, the holy grail of programming seemed to be getting rid of programmers.
Time and again it turned out that unless you very meticulously specified what you wanted a system to do, it didn’t do what you wanted it to do. And very meticulously specifying what you want a system to do is, or has been until very recently, indistinguishable from programming.
That’s not empirically true anymore. It’s baffling. It’s almost unimaginable. But reasonably imprecise descriptions of what you want a system to do can get you very close to the system you had in mind.
Theoretically, it’s hard to imagine. It flies in the face of decades of theoretical and, in reality, empirical experience.But, as Galileo was supposed to have said when provided with all kinds of effectively theological arguments against a heliocentric model of the solar system, *Eppure si morve*–”but it moves”.
Coming to terms with the empirical reality of how large language models work, what they do is a singular challenge. Not just for software engineers, but for many people with the knowledge of their field.
This is one of many such examples.
Using Git with coding agents – Agentic Engineering Patterns – Simon Willison’s Weblog

Git is a key tool for working with coding agents. Keeping code in version control lets us record how that code changes over time and investigate and reverse any mistakes. All of the coding agents are fluent in using Git’s features, both basic and advanced.
This fluency means we can be more ambitious about how we use Git ourselves. We don’t need to memorize how to do things with Git, but staying aware of what’s possible means we can take advantage of the full suite of Git’s abilities.
Simon Willison continues his "book shaped" project on agentic coding. The current chapter focuses on Git for agentic coding with an overview of some of the most important features as well as how best it works. with them with HNT coding systems.
Code Review Is Not About Catching Bugs

My former Parse colleague Charity Majors – now CTO of Honeycomb and one of the strongest voices in the observability space – recently posted something that caught my attention. She’s frustrated with the discourse around AI-generated code shifting the bottleneck to code review, and she argues the real burden is validation – production observability. You don’t know if code works until it’s running with enough instrumentation to see what it’s actually doing.
But I think the “code review is the bottleneck” crowd and the “no, validation is the bottleneck” crowd are both working from the same flawed premise: that code review exists primarily to answer “does this code work?”
Code review answers: “Should this be part of my product?”
That’s a judgment call, and it’s a fundamentally different question than “does it work.” Does this approach fit our architecture? Does it introduce complexity we’ll regret in six months? Are we building toward the product we intend, or accumulating decisions that pull us sideways? Does this abstraction earn its keep, or are we over-engineering for a future that may never arrive? Does this feel right – not just functionally correct, but does it reflect the taste and standards we want our product to embody?
We've been hearing "code generation was never the bottleneck" for quite some time from people who are skeptical about the impact of identity coding systems on software development.
They observe, rightly, that other parts of the software development cycle are equally, if not more, time-consuming. One of those being code review.
Code review is a practice, not an outcome. What's the outcome we're trying to achieve? And it is, as Charity Majors has observed elsewhere Validation.
Here David Poll digs a little deeper and observes...
Tests answer “does the code do what the author intended.” Production observability answers “what is the system actually doing.” Code review answers “was the author’s intent the right thing to build?”
You need all three. None of them substitutes for the others.
My Google Recruitment Journey (Part 1): Brute-Forcing My Algorithmic Ignorance

About 2 months ago, an email from xwf.google.com dropped into my inbox,
referencing an application from a year prior that I even forgot about.
My initial classification was that it is not possible and that this is just spam.
But after the screening call, the reality hit: I will have two online interviews (one technical, one behavioral) in just a week.
And not just a regular interview to another company, these will be interviews for a company
that I still consider as one of the top-of-the-world factory of engineers.This was a critical state. I’ve worked as a software developer in telecommunications for a few years, focusing on high-level abstraction:
routing, message processing, and writing business logic.
In my hobbyist gamedev projects, even though sometimes I liked to make some pathfinding algorithm or to do a CPU 3D rasterizer by hand,
at the end of the day my metric for success was simple: if it runs at >60 FPS without drops, it ships.
One of the critiques you frequently see of AI across a broad range of applications, from education to software engineering to pick a subject area, is that by relying on them we dumb ourselves down. We don't do the work. We cheat. We get to the solution without doing the work that helps us understand the solution.
In my increasingly significant experience, this is a philosophical or even potentially a theological concern rather than an empirical one. That's not to say you can't do those things with these technologies. But on the other hand, as the following article will demonstrate, you can do quite the reverse.
Over the Christmas New Year period, I worked my way comprehensively through Anil Ananthaswamy highly recommended Why Machines Think, a history of machine learning and its mathematics.
I worked my way through it by giving Claude every section as I read it and clarifying things that I didn't understand, asking Claude to question me as to my understanding, and I came away, I think, with an enormous uplift in my understanding of machine learning.
Now onto this article and the anecdata.
The technical interviews for Google have long been considered incredibly exacting and relying very much on detailed understanding of computer science concepts.
Unless you're fresh out of university, it's likely you're going to have to extensively refresh your knowledge of many computer science concepts, because you probably haven't been using many, if any of them, extensively in your day-to-day work.
Here's a first-hand account of using LLMs to prepare for a Google technical interview in a couple of weeks. There might be some strong pointers for you, not just if you want to innovate in Google, but if you want to start thinking about how you can use these technologies as ways to sharpen and deepen your knowledge.
Production Is Where the Rigor Goes
AI, o11y, observability, software engineering
In early February, Martin Fowler and the good folks at Thoughtworks sponsored a small, invite-only unconference in Deer Valley, Utah—birthplace of the Agile Manifesto—to talk about how software engineering is changing in the AI-native era.
This document represents an almost incalculable amount of engineering skill, practical expertise, and battle-hardened wisdom, from some of the leading voices and actual titans in our field. It’s also a fascinating capsule of where the industry is at in this weird, compressed moment of change, from people who aren’t trying to sell you anything.
Across decades of software evolution, the same misunderstanding keeps recurring. Constraint removal is mistaken for loss of rigor. But what actually happens, when things go well, is rigor relocation.
Control doesn’t disappear. It moves closer to reality.
If [code] generation gets easier, judgment must get stricter. Otherwise, you’re not engineering anymore.
We've covered the recent symposium by some world-leading software engineers on AI and software engineering held a few weeks ago. Annie Vella gave her thoughts
Here Charity Majors, another participant, reflects on what you feel were particular omissions or shortcomings. Above all, the importance of production and observability.
Compile to Architecture – The Phoenix Architecture

For a long time we’ve treated frameworks as the target of software development. But if systems are meant to be regenerated and replaced safely, the real compilation target has to be the architecture itself.
The industry is still trying to generate applications.
A React app. A Django service. A Rails API. A FastAPI backend.
That instinct made sense when writing software was the expensive part. But in a world where code can be generated quickly and cheaply, the real constraint has shifted. The problem is no longer producing code. The problem is replacing it safely.
A few months now ago, in <a href="https://webdirections.org/blog/stack-collapse-developer-experience-ai-and-the-collapse-of-the-front-end-stack/">Stack Collapse</a>, I suggested that the layers of abstraction we built on top of the underlying browser capability, the DOM in the browser APIs, was no longer something we should be doing.
Here Chad Fowler explores a very similar idea.
andrewyng/context-hub
Coding agents hallucinate APIs and forget what they learn in a session. Context Hub gives them curated, versioned docs, plus the ability to get smarter with every task. All content is open and maintained as markdown in this repo — you can inspect exactly what your agent reads, and contribute back.
The legendary Andrew Ng asks "Should there be a Stack Overflow for AI coding agents to share learnings with each other?"
And that's what he is building here.
Google Engineers Launch “Sashiko” For Agentic AI Code Review Of The Linux Kernel

Google engineers have been spending the past number of months developing Sashiko as an agentic AI code review system for the Linux kernel. It’s now open-source and publicly available and will continue to do upstream Linux kernel code review thanks to funding from Google.
Roman Gushchin of Google’s Linux kernel team announced yesterday as this new agentic AI code review system. They have been using it internally at Google for some time to uncover issues and it’s now publicly available and covering all submissions to the Linux kernel mailing list. Roman reports that Sashiko was able to find around 53% of bugs based on an unfiltered set of 1,000 recent upstream Linux kernel issues with “Fixes: ”
>”In my measurement, Sashiko was able to find 53% of bugs based on a completely unfiltered set of 1000 recent upstream issues based on “Fixes:” tags (using Gemini 3.1 Pro). Some might say that 53% is not that impressive, but 100% of these issues were missed by human reviewers.”
One frequent observation about software engineering and AI is that writing the code has traditionally not been the bottleneck in software production and is only one small part of the responsibilities of software engineers.
Verifying the correctness, quality assurance, and debugging is clearly another significant part of the process. And here is the system that Google has been developing for reviewing some incredibly complex code–Linux kernel.
Apple Quietly Blocks Updates for Popular ‘Vibe Coding’ Apps

Apple has quietly blocked AI “vibe coding” apps, such as Replit and Vibecode, from releasing App Store updates unless they make changes, The Information reports.
Apple told The Information that certain vibe coding features breach long-standing App Store rules prohibiting apps from executing code that alters their own functionality or that of other apps. Some of these apps also support building software for Apple devices, which may have contributed to a recent surge in new App Store submissions and, in some cases, slower approval times, according to developers.
I had to double-take when I saw that I had written only six weeks ago the piece <a href="https://webdirections.org/blog/here-comes-everybody-again/">Here comes everybody (again)</a>.
In it, I concluded
Steve Jobs was fond of quoting Wayne Gretzky: “Skate to where the puck is going, not where it has been.”
The puck is going somewhere new. The democratisation of software creation is not a minor trend. It’s a fundamental shift in the relationship between people and technology, as significant as the shift from desktop to mobile. From professional to user-generated content. Indeed I’d argue more significant than these.
Software will be created by everyone, often ephemeral. Shared like content, discovered through social and algorithmic channels, and used in contexts we can’t imagine yet. Web technologies will be the substrate for most of this creation, because the web is the only platform open enough to support it.
The mobile platforms that dominate our digital lives were built for a different world. They assume software is a product made by professionals and distributed through official channels. They assume users need protection from the complexity of software. They assume gatekeeping is a feature, not a bug.
These assumptions, however well intentioned when formulated nearly 2 decades ago, are now antiquated. And the platforms built on them — for all their current dominance — may find themselves on the wrong side of a generational shift in how software gets made, shared, and used.
This shift isn’t coming, it’s arrived (like William Gibson said of the future, “it’s just not evenly distributed”).
Which platforms will adapt to support it, and which will discover too late that they were skating to where the puck used to be?
It seems we're starting to get some answers to that question.
Introducing the Machine Payments Protocol
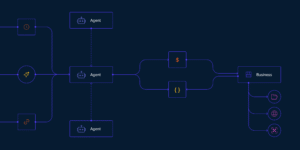
However, the tools of the current financial system were built for humans, so agents struggle to use them. Making a purchase today can require an agent to create an account, navigate a pricing page, choose between subscription tiers, enter payment details, and set up billing—steps that often require human intervention.
To help eliminate these challenges, we’re launching the Machine Payments Protocol (MPP), an open standard, internet-native way for agents to pay—co-authored by Tempo and Stripe. MPP provides a specification for agents and services to coordinate payments programmatically, enabling microtransactions, recurring payments, and more.
I've said more than once recently that I believe an increasingly significant percentage of all the visitors to your site will not be people but will be agents. and this proposed new protocol for agent payments from Stripe and others is the plumbing we will need to enable that.
If you thought the speed of writing code was your problem – you have bigger problems | Debugging Leadership | Debugging Leadership

The core idea is the Theory of Constraints, and it goes like this:
Every system has exactly one constraint. One bottleneck. The throughput of your entire system is determined by the throughput of that bottleneck. Nothing else matters until you fix the bottleneck.
I think the challenge with Andrew Murphy's very thoughtful piece here, and he's someone with an immense amount of engineering and leadership experience is, as with a piece earlier today that we quoted, that he's analysing an existing system, identifying one aspect of it, code generation, and reasoning about what happens if that changes but nothing else does.
But, large language models and agentic systems are not simply increasing the cadence of code generation. They're impacting all of the software development lifecycle. so it makes a much more complex system that we're trying to reason about.
Toward automated verification of unreviewed AI-generated code – Peter Lavigne
I’ve been wondering what it would take for me to use unreviewed AI-generated code in a production setting.
To that end, I ran an experiment that has changed my mindset from “I must always review AI-generated code” to “I must always verify AI-generated code.” By “review” I mean reading the code line by line. By “verify” I mean confirming the code is correct, whether through review, machine-enforceable constraints, or both.
Code generation was never the bottleneck is a refrain we hear daily by people skeptical about the use of LLMs for software engineering.
So what are the other bottlenecks? One of those is verification. Ensuring that the code generated is of sufficient quality. And we've long had many techniques for doing this as humans, which include code reviews. but many of them, much of it is automated with linters, compilers, test suites and so on.
I think a really important question any software engineer should ask is what signals would make me feel comfortable accepting some code?
I also think that's not a one-and-done answer. There's plenty of software I'd write internally to speed up a process that was previously done manually, and what I'm very much concerned, almost solely concerned with there, is what comes out the other end of that process. But, if I'm driving an autonomous car, I would like to think that the code that went into it, whether generated by a human or a LLM, was more rigorously verified.
What answer do you have?
202603 – apenwarr

We’ve all heard of those network effect laws: the value of a network goes up
with the square of the number of members. Or the cost of communication goes
up with the square of the number of members, or maybe it was n log n, or
something like that, depending how you arrange the members. Anyway doubling
a team doesn’t double its speed; there’s coordination overhead. Exactly how
much overhead depends on how badly you botch the org design.But there’s one rule of thumb that someone showed me decades ago, that has
stuck with me ever since, because of how annoyingly true it is. The rule
is annoying because it doesn’t seem like it should be true. There’s no
theoretical basis for this claim that I’ve ever heard. And yet, every time I
look for it, there it is.Every layer of approval makes a process 10x slower
This detailed essay has at its heart a belief about systems–that each layer of approval makes the process ten times slower.
Now, this may be empirically true, even for software development, but it is contingent. I would say all of this essay would have made sense much more a year ago or even less when we focused on the idea of large language models as code generators but kept everything else about the process of software engineering unchanged.
But it's not. Quality assurance and verification are increasingly something we can rely on, or that it made it the systems to do. Formal verification techniques, Which have been used for decades, but which have relied on a tiny number of extremely capable experts are becoming increasingly tractable to large language models.
The challenge when new and transformative technologies emerge is not to see their obvious application, but it's to see their broader application. We've focused a lot on code generation with these technologies the last three or four years, but that's not the only place in the software engineering process that they are already having and will increasingly have an impact.
Grace Hopper’s Revenge – by Greg Olsen
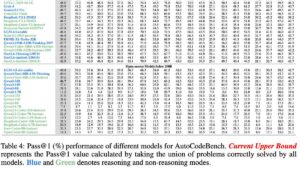
The world of software has lots of rules and laws. One of the most hilarious is Kernighan’s Law:
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.
In the past, humans have written, read, and debugged the code.
Now LLMs write code, humans read and debug. (And LLMs write voluminous mediocre code in verbose languages.)
Humans will do less and less. LLMs will write code, debug, and manage edge cases. LLMs will verify against human specifications, human audits, human requirements. And humans will only intervene when things are misaligned. Which they can see because they have easy verification mechanisms.
This essay by Greg Olson from late last year considers the impact of large language models on software engineering, And in particular, the programming languages that work best with large language models.
I wonder how much longer we're going to be particularly concerned with questions like that. And when we'll start seeing the emergence of programming languages and patterns and paradigms that are LLM first.
WebMCP for Beginners

Raise your hand if you thought WebMCP was just an MCP server. Guilty as charged. I did too. It turns out it’s a W3C standard that uses similar concepts to MCP. Here’s what it actually is.
WebMCP is a way for websites to define actions that AI agents can call directly.
I am increasingly of the opinion that for many websites it's not humans that matter as users but agents. But if you've tried to use many websites with an agent you will find that can be very challenging. So there are a number of emerging standards and patterns for making sites more usable by agents. One of those is WebMCP which Rizel Scarlett gives a great introduction to here.
What is agentic engineering? – Agentic Engineering Patterns – Simon Willison’s Weblog
AI, AI Engineering, coding agent, software engineering

I use the term agentic engineering to describe the practice of developing software with the assistance of coding agents.
What are coding agents? They’re agents that can both write and execute code. Popular examples include Claude Code, OpenAI Codex, and Gemini CLI.
What’s an agent? Clearly defining that term is a challenge that has frustrated AI researchers since at least the 1990s but the definition I’ve come to accept, at least in the field of Large Language Models (LLMs) like GPT-5 and Gemini and Claude, is this one:
A new chapter from Simon Willis' agentic engineering patterns looks at the definition of agentic engineering and the nature of agents in this context.
The Middle Loop – Annie Vella
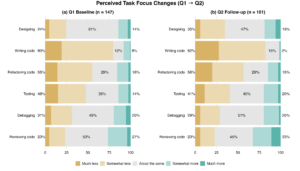
That’s why the first research question I wanted to answer as part of my Masters of Engineering at the University of Auckland, supervised by Kelly Blincoe, was about task focus. Are AI tools shifting where engineers actually spend their time and effort? Because if they are, they’re implicitly shifting what skills we practice and, ultimately, the definition of the role itself.
Ok so engineers are spending less time writing code, no surprise there. But the standard assumption, that freed-up time flows upstream into design and architecture, didn’t hold. Time compressed across almost all six tasks, including design. Rather than trading writing time for design time, engineers reported spending less time on nearly everything.
Annie Vella, who has been doing research into developer workflows as part of a Masters, has been tracking how agentic software development tools are impacting the practice of software engineering.
(5) Software Will Stop Being a Thing – Utopai
AI, economics, software engineering

A thoughtful essay made the rounds recently, arguing that AI-assisted coding splits the software world into three tiers. Tech companies at the top, where senior engineers review what AI produces. Large enterprises in the middle, buying platforms with guardrails and bringing in fractional senior expertise. And small businesses at the bottom, served by a new kind of local developer, a “software plumber” who builds custom tools at price points that finally make sense.
An unspoken assumption in all the conversation about the impact of AI on software engineering is that we will continue to develop software artifacts, apps if you will, just more quickly, more efficiently, more cheaply.
But perhaps, as the author argues here, that won't be the case.
A couple of days ago, I sat down with Vivek Bharathi and dumped my brains. Here’s the interview…
AI, economics, software engineering

Below you’ll find an AI transcription of everything we riffed about.
Key distinction: Software Development vs. Software Engineering:
Here, Jeff Huntley writes up key points from his recent conversation with Vivek Bharathi.
porting software has been trivial for a while now. here’s how you do it.
AI, economics, software engineering

This one is short and sweet. if you want to port a codebase from one language to another here’s the approach:
The key theory here is usage of citations in the specifications which tease the file_read tool to study the original implementation during stage 3. Reducing stage 1 and stage 2 to specs is the precursor which transforms a code base into high level PRDs without coupling the implementation from the source language.
Recently we've covered articles talking about recreating open source software using an AI cleanroom approach that provides a like-for-like replacement with a different license.
Here Geoff Huntley shows our trivia it is to do so.
The Great Turnover: 9 in 10 Companies Plan To Hire in 2026, Yet 6 in 10 Will Have Layoffs
AI, economics, software engineering
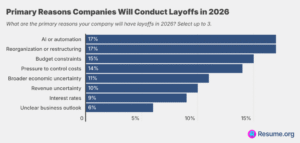
Resume.org’s latest survey of 1,000 U.S. hiring managers found that:
AI is influencing staffing decisions, but most companies aren’t experiencing the dramatic job replacement narrative that often gets pushed. Only 9% say AI has fully replaced certain roles, while nearly half (45%) say it has partially reduced the need for new hires, suggesting companies are using AI more as a hiring slowdown tool than a true workforce substitute. At the same time, 45% report that AI has had little to no impact on staffing levels, underscoring the uneven and limited effect it actually has across organizations.
Many companies admit they frame layoffs or hiring slowdowns as AI-driven because it plays better with stakeholders than saying the real reason is financial constraints. Nearly 6 in 10 companies report doing this, including 17% that claim to do it exactly, and 42% that say they do it somewhat.
As has been observed elsewhere, it's probably sensible to take the explanation that significant job reductions in companies have been driven by AI with a grain of salt.
Software Bonkers
I’m software bonkers: I can’t stop thinking about software. And I can’t stop building software.
My first Claude Code project was to rebuild Twitter as I always thought it should be:
Surprise! It’s really lovely. And members from my membership program have used it this past year to form a community the likes of Ye Internet of Yore. We share nice, inspiring things, and are nice and inspiring to one another.
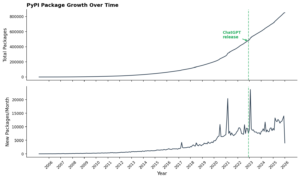
We recently posted a piece from Answers.ai asking where is all the AI developed software if software developers are now many times more productive.
They analyzed the Python ecosystem and found at best three weak signals for a developer productivity increase.
Perhaps they weren't looking in the right place. In my experience, this story from Craig Mod captures where this new software is. It's not necessarily on GitHub Actions or NPM or PyPI–It's running on local hosts. It's running on private cloud instances. In my case, there are a dozen or more applications that I've built to run the internal systems for our conference, to explore ideas with IoT and more.
So where are all the AI apps?
AI, economics, software engineering
Fans of vibecoding and agentic tools say they are 2x as productive, 10x as productive – maybe 100x as productive! Someone built an entire web browser from scratch. Amazing!
So, skeptics reasonably ask, where are all the apps? If AI users are becoming (let’s be conservative) merely 2x more productive, then where do we look to see 2x more software being produced? Such questions all start from the assumption that the world wants more software, so that if software has gotten cheaper to make then people will make more of it. So if you agree with that assumption, then where is the new software surplus, what we might call the “AI effect”?
Anecdotally, many developers are reporting significant improvements in their productivity.
So it's fair to ask the question, where is all the software they are developing?
Here are the folks from AnswerAI. I look in particular at the Python ecosystem. In fairness, not a bad place to look for signals given Python is so intimately connected to AI and software development.
And in short, they find not particularly strong signals of an uptick in developer productivity.
a sneak preview behind an embedded software factory. I suspect rapid application dev is back
AI, AI Engineering, software engineering

Latent Patterns builds Latent patterns. I’ve taken some of the ideas behind “The Weaving Loom” and inverted them, put them into the product itself and have perhaps accidentally created a better Lovable.
It’s interesting because I see all these developer tooling companies building for the persona of developers, but to me, that persona no longer exists. You see, within latent patterns, the product (latent patterns) is now the IDE.
If I want to make a change to something, I pop on designer mode, and this allows me to develop LP in LP. I can make changes to the copy or completely change the application’s functionality using the designer substrate directly from within the product, then click the launch agent to ship.
Geoff Huntley, who is very much the forefront of exploring the deeper impact of agentic coding systems on software engineering practice, thinks that
[he] might retire most developer practices, including CI/CD.
I think he's on to something. I think all the practices of software engineering that we have developed over the last nearly 60 years, let's say since the software engineering crisis of the late 60s, are now contingent. And it doesn't mean they're wrong, but we need to recognise that they emerged in a certain environment where certain things were scarce. There was a high coordination cost of having multiple people working on the same code base. and that as agentic systems become increasingly capable, those costs shifts and so the practices we develop to manage them need to be reconsidered.
I'll actually go a step further. I think Geoff isn't, perhaps, sufficiently ambitious here because he still imagines a world of software, of applications. And I have a growing inclination that where we're going we won't need applications.
(5) My (hypothetical) SRECon26 keynote
AI, o11y, observability, software engineering

Which means it was almost a year ago that Fred Hebert and I were up on stage, delivering the closing keynote1 at SRECon25.
We argued that SREs should get involved and skill up on generative AI tools and techniques, instead of being naysayers and peanut gallerians. You can get a feel for the overall vibe from the description:
What I do know is that one year ago, I still thought of generative AI as one more really big integration or use case we had to support, whether we liked it or not. Like AI was a slop-happy toddler gone mad in our codebase, and our sworn duty as SREs was to corral and control it, while trying not be a total dick about it.
I don’t know when exactly that bit flipped in my head, I only know that it did. And as soon as it did, I felt like the last person on earth to catch on. I can barely connect with my own views from eleven months ago.
So no, I don’t think it was obvious in early 2025 that AI generated code would soon grow out of its slop phase. Skepticism was reasonable for a time, and then it was not. I know a lot of technologists who flipped the same bit at some point in 2025.
If I was giving the keynote at SRECon 2026, I would ditch the begrudging stance. I would start by acknowledging that AI is radically changing the way we build software. It’s here, it’s happening, and it is coming for us all.
It is very, very hard to adjust to change that is being forced on you. So please don’t wait for it to be forced on you. Swim out to meet it. Find your way in, find something to get excited about.
Charity Majors is a genuine giant in the field of software engineering. One of the originators of modern observability, founder of Honeycomb, author, highly respected speaker.
Here she reflects on her transformation over the last 12 months when it comes to thinking about AI and software engineering. She captures a path that I think many software engineers have trod over the last year. And I think this should be required reading. Whether a year ago you were very optimistic and positive about AI and software engineering, or like charity, far more sceptical.
The 8 Levels of Agentic Engineering — Bassim Eledath
AI, AI Engineering, coding agent, software engineering
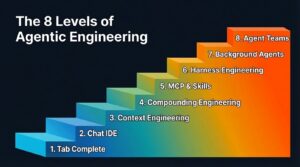
AI’s coding ability is outpacing our ability to wield it effectively. That’s why all the SWE-bench score maxxing isn’t syncing with the productivity metrics engineering leadership actually cares about. When Anthropic’s team ships a product like Cowork in 10 days and another team can’t move past a broken POC using the same models, the difference is that one team has closed the gap between capability and practice and the other hasn’t.
Way back in the dark ages of October 2025, Guy Podjarny at TESSL used the model of autonomous driving and its <a href="https://tessl.io/blog/the-5-levels-of-ai-agent-autonomy-learning-from-self-driving-cars/">five levels to articulate five levels of agentic coding</a>.
Well, stand back because Bassim Eledath now identifies eight levels of agentic engineering.
I built a programming language using Claude Code
AI, AI Engineering, software engineering

Over the course of four weeks in January and February, I built a new programming language using Claude Code. I named it Cutlet after my cat. It’s completely legal to do that. You can find the source code on GitHub, along with build instructions and example programs.
I went into this experiment with some skepticism. My previous attempts at building something entirely using Claude Code hadn’t worked out. But this attempt has not only been successful, but produced results beyond what I’d imagined possible. I don’t hold the belief that all software in the future will be written by LLMs. But I do believe there is a large subset that can be partially or mostly outsourced to these new tools.
Building Cutlet taught me something important: using LLMs to produce code does not mean you forget everything you’ve learned about building software. Agentic engineering requires careful planning, skill, craftsmanship, and discipline, just like any software worth building before generative AI. The skills required to work with coding agents might look different from typing code line-by-line into an editor, but they’re still very much the same engineering skills we’ve been sharpening all our careers.
Geoff Huntley, the discoverer of the Ralph Wiggum technique, used that approach, or indeed discovered that approach, while developing a programming language he called Cursed.
Over the last couple of months Ankur Sethi developed his own, probably somewhat less cursed programming language. And here he writes about his experience with that and broader experience working with large language models.
Billion-Parameter Theories

For most of human history, the things we couldn’t explain, we called mystical. The movement of stars, the trajectories of projectiles, the behavior of gases. Then, over the course of a few centuries, we pulled these phenomena into the domain of human inquiry. We called it science.
What’s remarkable, in retrospect, is how terse those explanations turned out to be. F=ma. E=mc². PV=nRT.
The Enlightenment and its intellectual descendants gave us a powerful toolkit for taming the complicated. And then we made the natural mistake of assuming that toolkit would scale to everything.
The concepts they developed were descriptive rather than prescriptive. Knowing that a system exhibits power law behavior tells you the shape of what will happen without telling you the specifics. You couldn’t pick these principles up and use them to intervene in the world with precision.
Take large language models. Fundamentally, a large language model is a compressed model of an extraordinarily complex system, the totality of human language use, which itself reflects human thought, culture, social dynamics, and reasoning. The compression ratio is enormous. The model is unimaginably smaller than the system it represents. That makes it a theory of that system, in every sense that matters, a lossy but useful representation that lets you make predictions and run counterfactuals.
So perhaps there are two layers of theory here. The system-specific layer, the trained weights, is large and particular to its domain. This will likely always be true. The theory of this economy or this climate will always be vast.
But the meta-layer, the minimal architecture that can learn to represent arbitrary complex systems, might be compact and universal. It might be exactly the kind of good explanation Deutsch would champion.
I've long been very interested in complexity theory. It had its moment back in the late 1980s and early 1990s with chaos theory and a very popular science book from James Gleick.
Benoit Mandelbrot, he of the famed Mandelbrot set, and one of the originators of the science. was something of a rock star.
In this long but very readable and I found engaging essay, Sean Linehan Argues that large language models, attention-based models, are a new science. I highly recommend reading this, even if it's not something you'll apply in your everyday work.